chinmay-032 opened a new issue, #8625:
URL: https://github.com/apache/hudi/issues/8625
Hi all. Need your help in a weird problem I'm facing while writing to Hudi
using Pyspark. The flow we're using is something like this: Read from Kafka
using spark in batches of 15 minutes. Divide the dataframe into a list of
dataframes according to some business logic. For each dataframe - write to a
different hudi table. The spark job is submitted as a step to an AWS EMR
v6.10.0.
**Describe the problem you faced**
The problem is that partial updates are not working with the above method.
By this I mean, if a later record comes with few fields missing and that is
upserted, it inserts null values in those fields, instead of using the older
values. I had previously tried to do partial updates using the same Hudi
configs in a pyspark notebook attached to an EMR of same version and that had
worked. I am not sure what is now causing the issue.
The config I'm using are:
```
common_config={
"hoodie.datasource.write.table.type": "COPY_ON_WRITE",
"hoodie.datasource.write.recordkey.field": "profile_id",
"hoodie.datasource.write.precombine.field": "timestamp",
"hoodie.datasource.write.partitionpath.field": "timestamp__date_",
"hoodie.datasource.hive_sync.partition_fields": "timestamp__date_",
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.table.name': 'profile_properties_407',
'hoodie.datasource.hive_sync.database': 'hudi_staging',
'hoodie.datasource.hive_sync.table': 'profile_properties_407',
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.index.type': 'GLOBAL_BLOOM',
'hoodie.datasource.hive_sync.mode': 'hms',
'hoodie.bloom.index.update.partition.path': 'false',
'hoodie.datasource.hive_sync.support_timestamp': 'true',
'hoodie.datasource.hive_sync.partition_extractor_class':
'org.apache.hudi.hive.SlashEncodedDayPartitionValueExtractor',
"hoodie.datasource.write.keygenerator.class":
"org.apache.hudi.keygen.TimestampBasedKeyGenerator",
"hoodie.deltastreamer.keygen.timebased.timestamp.type": "SCALAR",
"hoodie.deltastreamer.keygen.timebased.output.dateformat": 'yyyy/MM/dd',
"hoodie.deltastreamer.keygen.timebased.timezone": "GMT",
"hoodie.deltastreamer.keygen.timebased.timestamp.scalar.time.unit":
"DAYS",
"hoodie.datasource.write.payload.class":
"org.apache.hudi.common.model.PartialUpdateAvroPayload",
"hoodie.compaction.payload.class":
"org.apache.hudi.common.model.PartialUpdateAvroPayload",
"hoodie.datasource.compaction.async.enable": "false",
"hoodie.payload.ordering.field": "timestamp"
}
```
Some other code snippets I think may be relevant are:
```
def get_structfield(fieldname, typestring):
if typestring == "NUMBER":
return StructField(fieldname, DoubleType(), True)
elif typestring == "BOOLEAN":
return StructField(fieldname, BooleanType(), True)
elif typestring == "RELATIVE_TIME":
return StructField(fieldname, TimestampType(), True)
elif typestring == "LIST_DOUBLE":
return StructField(fieldname, ArrayType(DoubleType(), False), True)
elif typestring == "LIST_STRING":
return StructField(fieldname, ArrayType(StringType(), False), True)
return StructField(fieldname, StringType(), True)
def get_schema(shop_id):
url = "https://company-private-url.com";
params = {
## Some params
}
response = requests.get(url, params=params)
if response.status_code == 200:
response_json = response.json()
schemaDict = response_json["data"]
schema = StructType()
for key in schemaDict:
schema.add(get_structfield(key, schemaDict[key]))
return schema
else:
raise Exception("Could not get schema")
def write_to_hudi(group):
t1 = time.time()
# Private code for getting table_name and shop_id.
LOGGER.info("Processing for table_name: " + table_name)
json_schema = get_schema(shop_id)
LOGGER.info(f"Table {table_name}: Get struct schema")
json_df = group.select(from_json(col("value"),
json_schema).alias("json_data")) \
.selectExpr("json_data.*")
LOGGER.info(f"Table {table_name}: Get json_df done")
json_df = json_df.withColumn("timestamp__date_",
to_date(json_df["timestamp"]))
LOGGER.info(f"Table {table_name}: Final schema fetched")
try:
json_df.write.format("org.apache.hudi") \
.options(**common_config) \
.option('hoodie.table.name', table_name) \
.option('hoodie.datasource.hive_sync.table', table_name) \
.mode("append") \
.save("s3a://path-to-private-table/" + table_name + "/")
except Exception as e:
LOGGER.info(f"Table {table_name}: Error while writing. Job aborted
{str(e)}")
t2 = time.time()
LOGGER.info(f"Table {table_name}: Writing to hudi completed in
{(t2-t1):.2f} seconds")
return True
```
```
###### Main Script
#############################################################
spark = SparkSession.builder.appName('identifyJob').master('yarn') \
.config("spark.sql.catalogImplementation", "hive") \
.config("spark.databricks.hive.metastore.glueCatalog.enabled",
"true") \
.config("spark.sql.extensions",
"org.apache.spark.sql.hudi.HoodieSparkSessionExtension") \
.config('spark.sql.parquet.binaryAsString', 'false')\
.config('spark.sql.caseSensitive', 'false')\
.config('parquet.enable.dictionary', 'false')\
.config('spark.sql.parquet.enableVectorizedReader', 'false')\
.config('hoodie.schema.on.read.enable', 'true') \
.config('spark.serializer',
'org.apache.spark.serializer.KryoSerializer') \
.config('spark.sql.hive.convertMetastoreParquet', 'false') \
.config("spark.sql.parquet.compression.codec", "gzip").getOrCreate()
startOffsetJson, endOffsetJson = get_kafka_offsets()
sampleDataframe = (
spark.read.format("kafka")
.option("includeHeaders", "true")\
.option("kafka.bootstrap.servers", KAFKA_BOOTSTRAP_SERVER)\
.option("subscribe", KAFKA_TOPIC_NAME)\
.option("kafka.security.protocol", "SASL_SSL") \
.option("startingOffsetsByTimestamp", startOffsetJson)\
.option("endingOffsetsByTimestamp", endOffsetJson)\
.option("kafka.sasl.mechanism", "PLAIN") \
.option("kafka.sasl.jaas.config", KAFKA_AUTH_STR) \
.load()
)
LOGGER.info("Finished reading kafka queue.")
num_events = sampleDataframe.count()
LOGGER.info(f"Consumed {num_events} events from Kafka")
if num_events == 0:
exit(0)
## Grouping according to business logic.
LOGGER.info("Grouping Dataframe done.")
LOGGER.info(f"No of tables to be written: {len(groups_list)}")
## Calling the write_to_hudi(group_list[i]) according to business logic.
LOGGER.info("Job completed successfully.")
```
Snippets from my test notebook (which actually perform partial updates):
```
# Define the schema
schema = StructType([
StructField("id", IntegerType(), True),
StructField("b", IntegerType, True),
StructField("c", StringType(), True),
StructField("d", DateType(), True),
StructField("timestamp", TimestampType(), True),
StructField("f", StringType(), True)
])
df = spark.createDataFrame([
Row(id=1, b=2, c='string1', d=date(2000, 1, 1),
timestamp=datetime.strptime("2000-01-01 12:00:00", '%Y-%m-%d %H:%M:%S'), f =
"2000-01-01 12:00:00"),
Row(id=2, b=3, c='string2', d=date(2000, 2, 1),
timestamp=datetime.strptime("2000-01-01 12:00:00", '%Y-%m-%d %H:%M:%S'), f =
"2000-01-01 12:21:20"),
Row(id=4, b=5, c='string3', d=date(2000, 3, 1),
timestamp=datetime.strptime("2000-01-01 12:00:00", '%Y-%m-%d %H:%M:%S'), f =
"2000-01-03 12:00:00")
], schema)
df.write.format("org.apache.hudi") \
.options(**common_config) \
.mode("append") \
.save("s3a://path-to-bucket/idk3/")
newdf = spark.createDataFrame([
Row(id=4, b=16, c=None, d=None, timestamp=datetime.strptime("2000-01-01
12:35:00", '%Y-%m-%d %H:%M:%S'), f=None)
], schema)
newdf.show()
newdf.write.format("org.apache.hudi") \
.options(**common_config) \
.mode("append") \
.save("s3a://path-to-bucket/idk3")
```
(All other configs are same in both codes).
**To Reproduce**
Important code snippets are provided above. EMR version 6.10.0 is used.
Attach a Pyspark notebook to the EMR to emulate the code from the notebook.
Querying is done using Amazon Athena and Glue Data Catalog is used as Hive
Metastore.
The first record (sent through Kafka) is: (screenshots of Athena after
consuming the record)

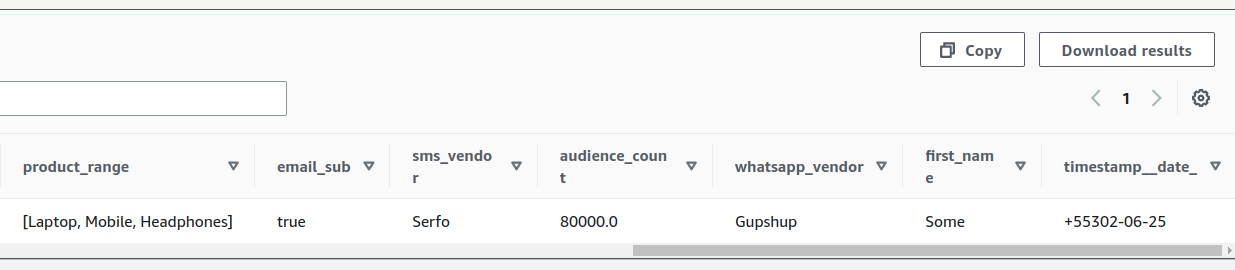
The second record (screenshot of Athena after consuming the record, in
isolation from the first):

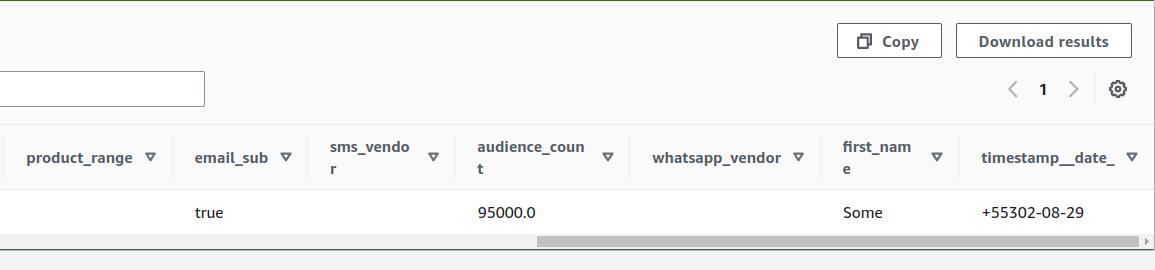
**Expected behavior**
Expected that it should pick up existing values for fields which have
"NULL". The final table should look like this:

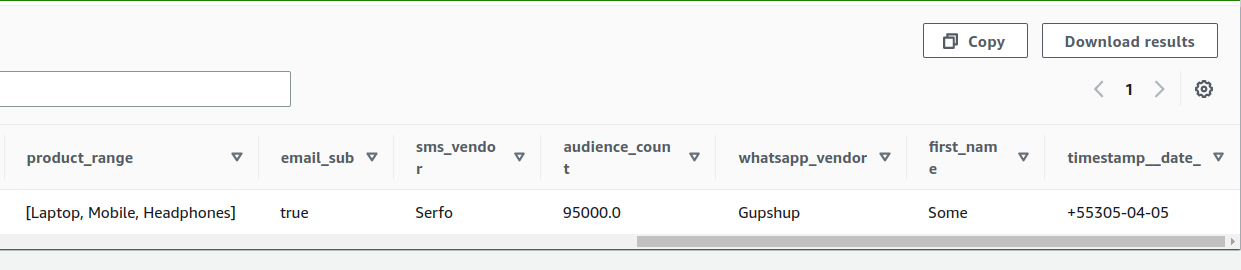
**Environment Description**
* Hudi version : 0.12.2-amzn-0
* Spark version : 3.3.1
* Hive version : 3.1.3
* Hadoop version : 3.3.3
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : No
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}