tomyanth opened a new issue, #8628: URL: https://github.com/apache/hudi/issues/8628
**Describe the problem you faced** The partitionpath field act somewhat similar to another recordkey(primary key) 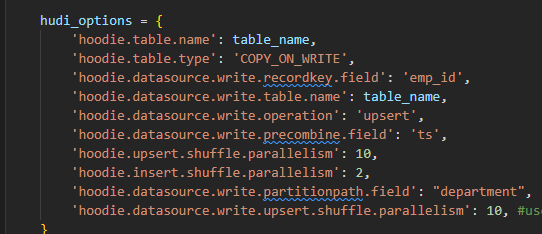 I just use emp_id as the recordkey field and department is only the partition field. However, I feel spark.read treat both emp_id and department as recordkey field when I see the table generated. What I get is this  But according to my understanding, what I get should be :  Because according to hudi's logic, the commit with larger commit time should overwrite the ones with smaller commit time and same recordkey to achieve the effect of updating the talbe **To Reproduce** Steps to reproduce the behavior: Environment: local console with juypter notebook 1. step one run the below code snippet from youtube guide to create the first set of data """ Install https://dlcdn.apache.org/spark/spark-3.3.1/spark-3.3.1-bin-hadoop2.tgz hadoop2.7 https://github.com/soumilshah1995/winutils/blob/master/hadoop-2.7.7/bin/winutils.exe pyspark --packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.1 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' VAR SPARK_HOME HADOOP_HOME PATH `%HAPOOP_HOME%\bin` `%SPARK_HOME%\bin` Complete Tutorials on HUDI https://github.com/soumilshah1995/Insert-Update-Read-Write-SnapShot-Time-Travel-incremental-Query-on-APache-Hudi-transacti/blob/main/hudi%20(1).ipynb """ import os import sys import uuid import pyspark from pyspark.sql import SparkSession from pyspark import SparkConf, SparkContext from pyspark.sql.functions import col, asc, desc from pyspark.sql.functions import col, to_timestamp, monotonically_increasing_id, to_date, when from pyspark.sql.functions import * from pyspark.sql.types import * from datetime import datetime from functools import reduce from faker import Faker from faker import Faker import findspark import datetime time = datetime.datetime.now() time = time.strftime("YMD%Y%m%dHHMMSSms%H%M%S%f") SUBMIT_ARGS = "--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.1 pyspark-shell" os.environ["PYSPARK_SUBMIT_ARGS"] = SUBMIT_ARGS os.environ['PYSPARK_PYTHON'] = sys.executable os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable findspark.init() spark = SparkSession.builder\ .config('spark.serializer', 'org.apache.spark.serializer.KryoSerializer') \ .config('className', 'org.apache.hudi') \ .config('spark.sql.hive.convertMetastoreParquet', 'false') \ .config('spark.sql.extensions', 'org.apache.spark.sql.hudi.HoodieSparkSessionExtension') \ .config('spark.sql.warehouse.dir', 'file:///C:/tmp/testAppend7') \ .getOrCreate() global faker faker = Faker() class DataGenerator(object): @staticmethod def get_data(): return [ ( x, faker.name(), faker.random_element(elements=('IT', 'HR', 'Sales', 'Marketing')), faker.random_element(elements=('CA', 'NY', 'TX', 'FL', 'IL', 'RJ')), faker.random_int(min=10000, max=150000), faker.random_int(min=18, max=60), faker.random_int(min=0, max=100000), faker.unix_time() ) for x in range(5) ] impleDataUpd = DataGenerator.get_data() schema = ["emp_id", "employee_name", "department", "state", "salary", "age", "bonus", "ts"] spark_df = spark.createDataFrame(data=impleDataUpd, schema=schema) print(spark_df.show()) db_name = "hudidb" table_name = "hudi_table2" recordkey = 'emp_id' precombine = 'ts' path = "file:///C:/tmp/testAppend7" method = 'upsert' table_type = "COPY_ON_WRITE" hudi_options = { 'hoodie.table.name': table_name, 'hoodie.table.type': 'COPY_ON_WRITE', 'hoodie.datasource.write.recordkey.field': 'emp_id', 'hoodie.datasource.write.table.name': table_name, 'hoodie.datasource.write.operation': 'upsert', 'hoodie.datasource.write.precombine.field': 'ts', 'hoodie.upsert.shuffle.parallelism': 10, 'hoodie.insert.shuffle.parallelism': 2, 'hoodie.datasource.write.partitionpath.field': "department", 'hoodie.datasource.write.upsert.shuffle.parallelism': 10, #useless } 2. Create an append function to call for later purpose def hudi_append(spark,schema,impleDataUpd,hudi_options,path,mode="append"): """ Function to upsert/overwrite data in S3 and update catalog. Args: spark: the spark instance. schema: The df column names. impleDataUpd: The df data needed for the function. hudi_options: The hudi_options needed. path: The path/assigned path for the hudi file. mode : The mode you want to manipulate your df. Default append *************************************************************************************** below shows some examples of how the variables should look like to use this function *************************************************************************************** # spark = SparkSession \ # .builder \ # .config('spark.serializer', 'org.apache.spark.serializer.KryoSerializer') \ # .getOrCreate() # impleDataUpd = [ # (6, "This is APPEND", "Sales", "RJ", 81000, 30, 23000, 827307999), # (7, "This is APPEND", "Engineering", "RJ", 79000, 53, 15000, 1627694678), # ] # schema = ["emp_id", "employee_name", "department", "state", "salary", "age", "bonus", "ts"] # path = "s3://mybucket/spark_warehouse" # hudi_options = { # 'hoodie.table.name': table_name, # 'hoodie.table.type': 'COPY_ON_WRITE', # 'hoodie.datasource.write.recordkey.field': 'emp_id', # 'hoodie.datasource.write.table.name': table_name, # 'hoodie.datasource.write.operation': 'upsert', # 'hoodie.datasource.write.precombine.field': 'ts', # 'hoodie.upsert.shuffle.parallelism': 2, # 'hoodie.insert.shuffle.parallelism': 2, # "hoodie.datasource.write.partitionpath.field": "department", # } """ spark_df = spark.createDataFrame(data=impleDataUpd, schema=schema) print(spark_df.show()) print("*"*55) print(f"{mode} to hudi") print("*"*55) spark_df.write.format("hudi"). \ options(**hudi_options). \ mode(mode). \ save(path) 3. Call the function to append data hudi_append(spark,schema,impleDataUpd,hudi_options,path) 4. Generate a new set of data for update impleDataUpd = DataGenerator.get_data() 5. Call the function again to append the updates hudi_append(spark,schema,impleDataUpd,hudi_options,path) 6. Read as hudi read_df = spark.read. \ format("hudi"). \ load(path) read_df.sort('emp_id').show() read_df.createOrReplaceGlobalTempView("hudi_error") spark.sql("select * from hudi_error") **Expected behavior** Table should behave like having only emp_id as recordkey field but the fact is both emp_id and department behave like recordkey field **Environment Description** * Hudi version : 0.12.1 * Spark version : 3.3.1 * Hive version : N/A * Hadoop version : 2.7.7 * Storage (HDFS/S3/GCS..) : * Running on Docker? (yes/no) : no **Additional context** JAVA version : 11 **Stacktrace** Not applicable -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}