bigdata-spec opened a new issue, #8662: URL: https://github.com/apache/hudi/issues/8662
Hello, I have meet some error for **spark-on-k8s-operator**. My hudi version is 0.13,spark version is 3.3.2 I find the pod log show the task is Successfully,but pod status is still Running? 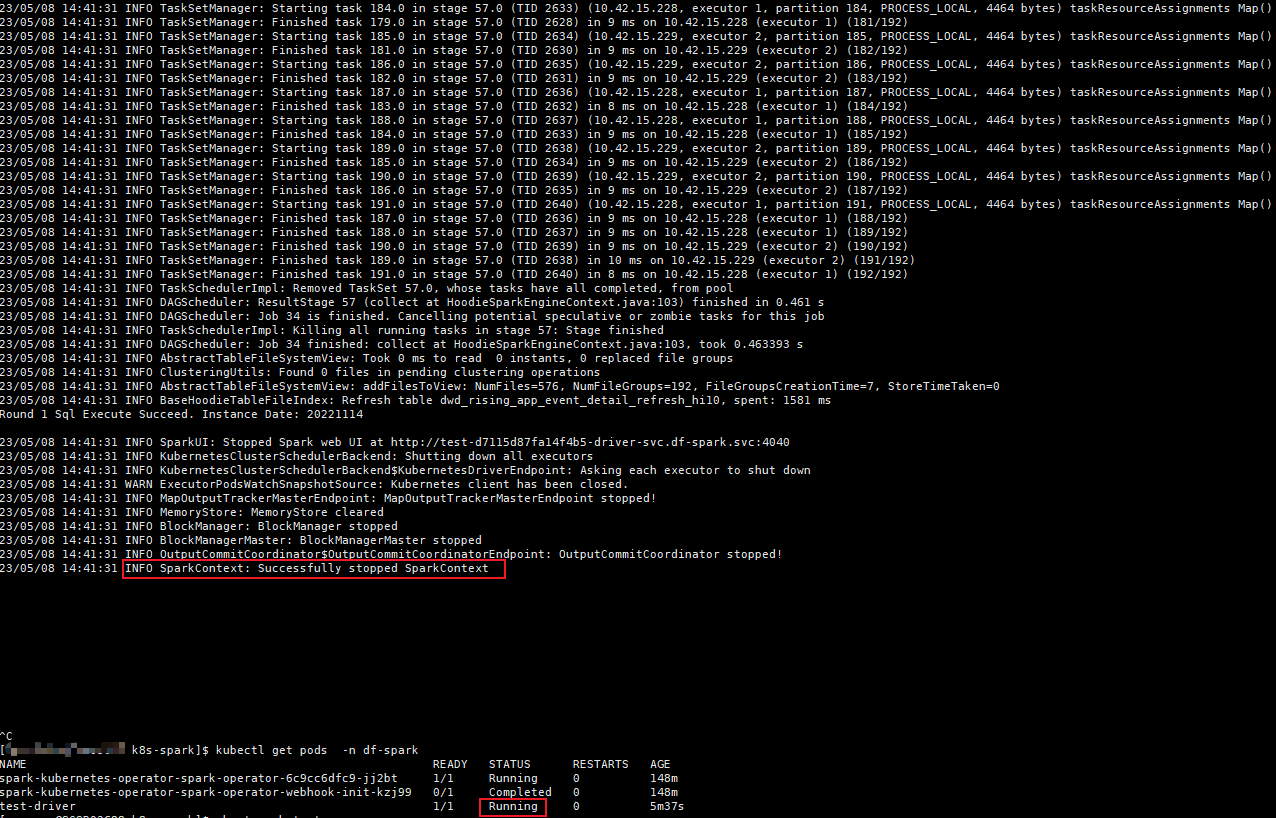 my sql setting is `set spark.sql.shuffle.partitions=600; set hoodie.insert.shuffle.parallelism=600; set hoodie.upsert.shuffle.parallelism=600; set hoodie.write.concurrency.mode=optimistic_concurrency_control; set hoodie.cleaner.policy.failed.writes=LAZY; set hoodie.write.lock.provider=org.apache.hudi.hive.transaction.lock.HiveMetastoreBasedLockProvider; set hoodie.write.lock.hivemetastore.database=zone_test; set hoodie.write.lock.hivemetastore.table=dwd_event_detail_refresh_hi5;` if my sql setting is only 'set spark.sql.shuffle.partitions=600; set hoodie.insert.shuffle.parallelism=600; set hoodie.upsert.shuffle.parallelism=600;' it can worker well. does hudi something settings conf can't use in k8s? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}