yihua commented on code in PR #11713: URL: https://github.com/apache/hudi/pull/11713#discussion_r1702128652
########## website/blog/2024-07-31-hudi-file-formats.md: ########## @@ -0,0 +1,68 @@ +--- +title: "Column File Formats: How Hudi Leverages Parquet and ORC " +excerpt: "Explains how Hudi uses Parquet and ORC" +author: Albert Wong +category: blog +image: /assets/images/blog/hudi-parquet-orc.jpg +tags: +- Data Lake +- Apache Hudi +- Parquet +- ORC +--- + +## Introduction +Apache Hudi emerges as a game-changer in the big data ecosystem by transforming data lakes into transactional hubs. Unlike traditional data lakes which struggle with updates and deletes, Hudi empowers users with functionalities like data ingestion, streaming updates (upserts), and even deletions. This allows for efficient incremental processing, keeping your data pipelines agile and data fresh for real-time analytics. Hudi seamlessly integrates with existing storage solutions and boasts compatibility with popular columnar file formats like Parquet (https://parquet.apache.org/) and ORC (https://orc.apache.org/). Choosing the right file format is crucial for optimized performance and efficient data manipulation within Hudi, as it directly impacts processing speed and storage efficiency. This blog will delve deeper into these features, and explore the significance of file format selection. + +## How does data storage work in Apache Hudi +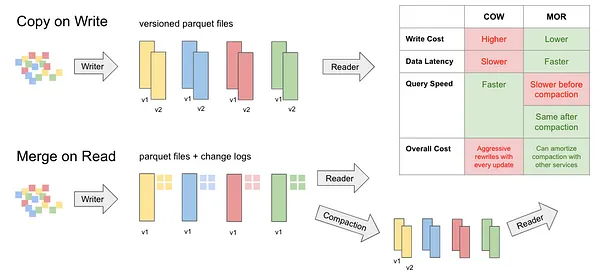 + +Apache Hudi offers two table storage options: Copy-on-Write (COW) and Merge-on-Read (MOR). +* COW tables: + * Data is stored in base files, with Parquet and ORC being the supported formats. + * Updates involve rewriting the entire base file with the modified data. +* MOR tables: + * Data resides in base files, again supporting Parquet and ORC formats. + * Updates are stored in separate delta files (using Avro format) and later merged with the base file by a periodic compaction process in the background. + +## Parquet vs ORC for your Apache Hudi Base File +Choosing the right file format for your Hudi environment depends on your specific needs. Here's a breakdown of Parquet, and ORC along with their strengths, weaknesses, and ideal use cases within Hudi: + +### Apache Parquet +Apache Parquet is a columnar storage file format. It’s designed for efficiency and performance, and it’s particularly well-suited for running complex queries on large datasets. Review Comment: Inlined links to Parquet and ORC would be good, e.g., ```suggestion [Apache Parquet](https://parquet.apache.org/) is a columnar storage file format. It’s designed for efficiency and performance, and it’s particularly well-suited for running complex queries on large datasets. ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}