hj2016 commented on issue #1941: URL: https://github.com/apache/hudi/issues/1941#issuecomment-687573173
@bvaradar: After fixing the change of HBase index partition, the test process is as follows: 1,Use the hbase index to import 100 million data, of which 11 years of data are partitioned by a total of 132 partitions on a monthly basis, and then synchronized using hive. The figure below shows the result of total data query with presto.  The following figure is a partial screenshot of the result of using presto to query the total data volume of each partition. 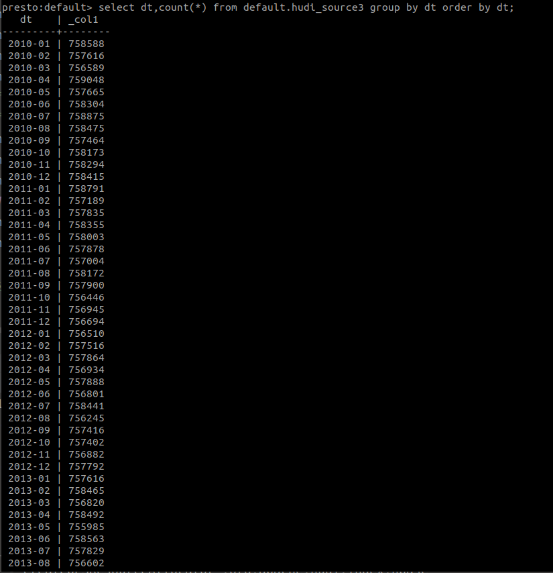 2.Extract 50-month partitions, each partition with 10,000 data volume and modify its original partition value to simulate partition changes, and then import the hive table. The following figure is the sql statement to extract the simulated data. [import_test_data.txt](https://github.com/apache/hudi/files/5177776/import_test_data.txt) The following figure shows the query result after import 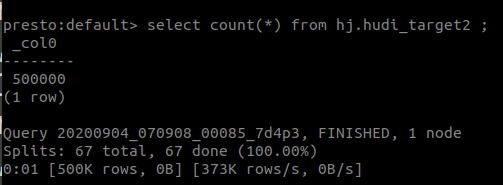 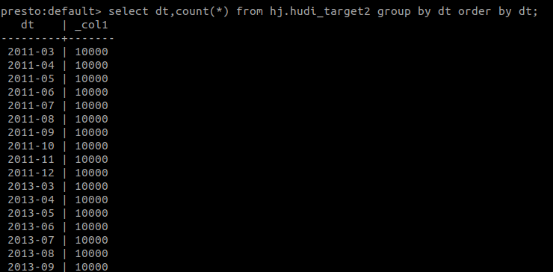 3. Upsert the hudi_target2 data to the hudi_source3 table code show as below ` val insertData: DataFrame = spark.read.parquet(dataPath) insertData.write.format("org.apache.hudi") .options(config) // 设置主键列名 .option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "rowkey") // 设置数据更新时间的列名 .option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "lastupdatedttm") // 设置分区列 .option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "fk_id") .option(DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY, classOf[SimpleKeyGenerator].getName) .option(HoodieIndexConfig.INDEX_TYPE_PROP, HoodieIndex.IndexType.HBASE.name()) .option(HoodieHBaseIndexConfig.HBASE_ZKQUORUM_PROP, "192.168.0.113") .option(HoodieHBaseIndexConfig.HBASE_ZKPORT_PROP, "2181") .option(HoodieHBaseIndexConfig.HBASE_ZK_ZNODEPARENT, "/hbase") .option(HoodieHBaseIndexConfig.HBASE_TABLENAME_PROP, "TEST_HBASE_INDEX") .option(HoodieHBaseIndexConfig.HBASE_INDEX_UPDATE_PARTITION_PATH, "true") .option(HoodieHBaseIndexConfig.HBASE_GET_BATCH_SIZE_PROP, "10000") .option(HoodieHBaseIndexConfig.HBASE_QPS_FRACTION_PROP, "0.5") .option(HoodieWriteConfig.TABLE_NAME, "TEST_HBASE_INDEX") .option(HoodieHBaseIndexConfig.HBASE_MAX_QPS_PER_REGION_SERVER_PROP, "1000") .option(HoodieHBaseIndexConfig.HBASE_INDEX_QPS_ALLOCATOR_CLASS, HoodieHBaseIndexConfig.DEFAULT_HBASE_INDEX_QPS_ALLOCATOR_CLASS) .mode(SaveMode.Append) .save(hudiTablePath)` 4.After the upsert operation, the total number of queries in the hudi_source3 table is still 100 million. After querying the data volume change of each partition, the partition change was completed successfully. The figure below shows the query result. 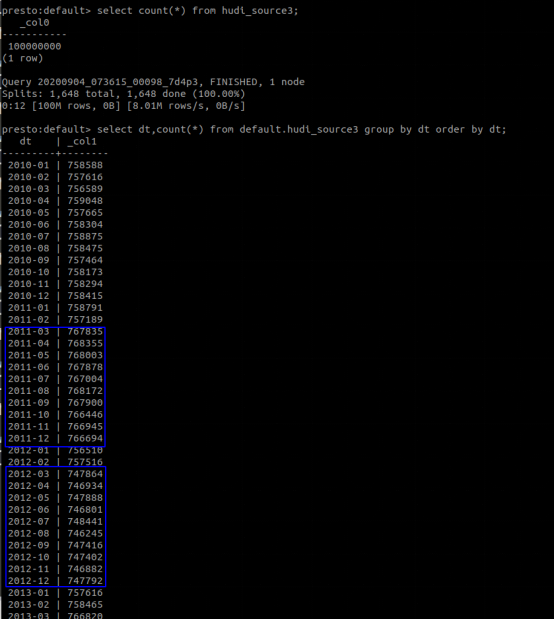 ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}