bradleyhurley commented on issue #2068: URL: https://github.com/apache/hudi/issues/2068#issuecomment-688369846
Failed Stages: 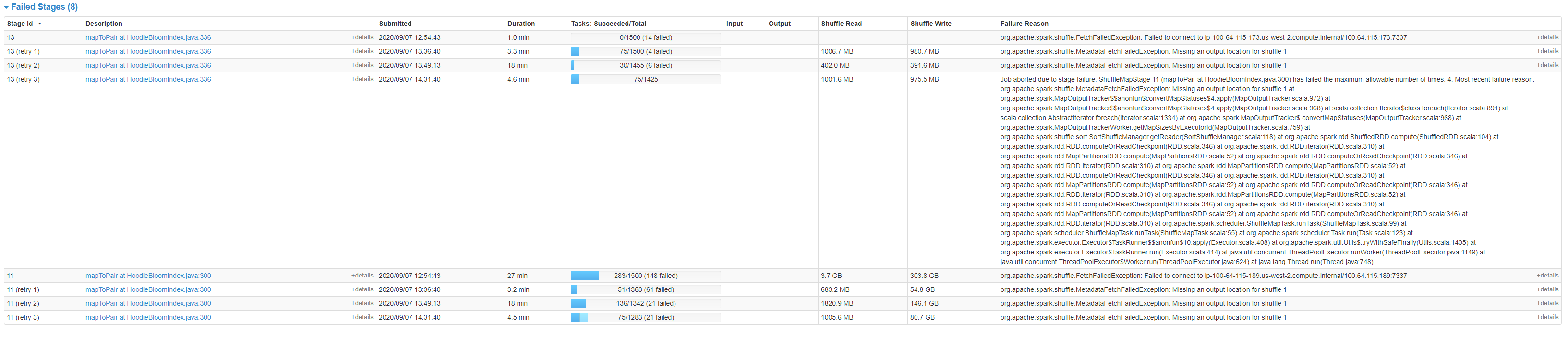 **Failed To Connect To XXX** We see these errors when nodes leave the EMR cluster. ``` org.apache.spark.shuffle.FetchFailedException: Failed to connect to ip-100-64-115-173.us-west-2.compute.internal/100.64.115.173:7337 at org.apache.spark.storage.ShuffleBlockFetcherIterator.throwFetchFailedException(ShuffleBlockFetcherIterator.scala:640) at org.apache.spark.storage.ShuffleBlockFetcherIterator.next(ShuffleBlockFetcherIterator.scala:562) at org.apache.spark.storage.ShuffleBlockFetcherIterator.next(ShuffleBlockFetcherIterator.scala:66) at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:435) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:441) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:409) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at org.apache.spark.util.collection.ExternalAppendOnlyMap.insertAll(ExternalAppendOnlyMap.scala:156) at org.apache.spark.Aggregator.combineCombinersByKey(Aggregator.scala:50) at org.apache.spark.shuffle.BlockStoreShuffleReader.read(BlockStoreShuffleReader.scala:106) at org.apache.spark.rdd.ShuffledRDD.compute(ShuffledRDD.scala:105) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.run(Task.scala:123) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.io.IOException: Failed to connect to ip-100-64-115-173.us-west-2.compute.internal/100.64.115.173:7337 at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:245) at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:187) at org.apache.spark.network.shuffle.ExternalShuffleClient.lambda$fetchBlocks$0(ExternalShuffleClient.java:100) at org.apache.spark.network.shuffle.RetryingBlockFetcher.fetchAllOutstanding(RetryingBlockFetcher.java:141) at org.apache.spark.network.shuffle.RetryingBlockFetcher.lambda$initiateRetry$0(RetryingBlockFetcher.java:169) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.run(FutureTask.java:266) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30) ... 1 more Caused by: io.netty.channel.AbstractChannel$AnnotatedNoRouteToHostException: No route to host: ip-100-64-115-173.us-west-2.compute.internal/100.64.115.173:7337 Caused by: java.net.NoRouteToHostException: No route to host at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:714) at io.netty.channel.socket.nio.NioSocketChannel.doFinishConnect(NioSocketChannel.java:327) at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:334) at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:688) at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:635) at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:552) at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:514) at io.netty.util.concurrent.SingleThreadEventExecutor$6.run(SingleThreadEventExecutor.java:1044) at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30) at java.lang.Thread.run(Thread.java:748) ``` **Missing an output location for shuffle 1** ``` org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 1 at org.apache.spark.MapOutputTracker$$anonfun$convertMapStatuses$4.apply(MapOutputTracker.scala:972) at org.apache.spark.MapOutputTracker$$anonfun$convertMapStatuses$4.apply(MapOutputTracker.scala:968) at scala.collection.Iterator$class.foreach(Iterator.scala:891) at scala.collection.AbstractIterator.foreach(Iterator.scala:1334) at org.apache.spark.MapOutputTracker$.convertMapStatuses(MapOutputTracker.scala:968) at org.apache.spark.MapOutputTrackerWorker.getMapSizesByExecutorId(MapOutputTracker.scala:759) at org.apache.spark.shuffle.sort.SortShuffleManager.getReader(SortShuffleManager.scala:118) at org.apache.spark.rdd.ShuffledRDD.compute(ShuffledRDD.scala:104) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:346) at org.apache.spark.rdd.RDD.iterator(RDD.scala:310) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:55) at org.apache.spark.scheduler.Task.run(Task.scala:123) at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:408) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:414) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) ``` ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}