jiangok2006 opened a new issue #2252:
URL: https://github.com/apache/hudi/issues/2252
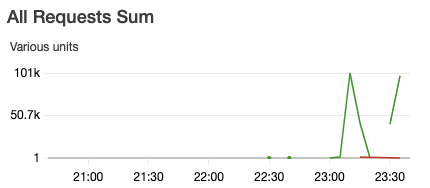
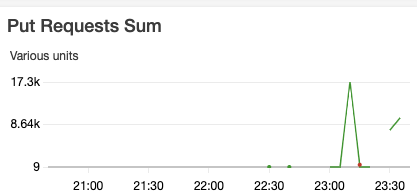
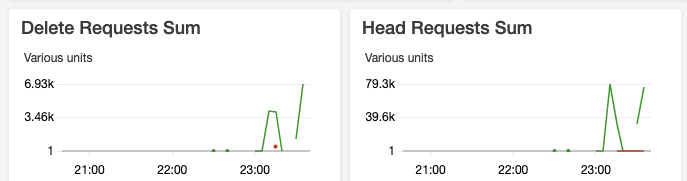
we observed too many s3 requests (the green lines in the graphs). The
dataset is 76GB and we are using hudi 0.6.0. COW vs MOR, insert vs bulkinsert
do not make much difference. Any idea how to optimize it? Thanks.
```
val hudiOptions = Map[String, String](
TABLE_NAME -> tableName,
OPERATION_OPT_KEY -> operation_opt_key,
INSERT_DROP_DUPS_OPT_KEY -> "true",
RECORDKEY_FIELD_OPT_KEY -> recordKey,
PARTITIONPATH_FIELD_OPT_KEY -> partitionKey,
PRECOMBINE_FIELD_OPT_KEY -> precombKey,
TABLE_TYPE_OPT_KEY -> table_type_opt_key,
BULKINSERT_SORT_MODE -> "none", // disable sorting for bulk insert
ENABLE_ROW_WRITER_OPT_KEY -> "true",
"hoodie.insert.shuffle.parallelism" -> "900",
KEYGENERATOR_CLASS_OPT_KEY ->
"org.apache.hudi.keygen.ComplexKeyGenerator",
HIVE_SYNC_ENABLED_OPT_KEY -> "false",
HIVE_PARTITION_FIELDS_OPT_KEY -> partitionKey,
HIVE_URL_OPT_KEY -> "jdbc:hive2://hiveserver:10000",
HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY ->
classOf[MultiPartKeysValueExtractor].getCanonicalName, // use
MultiPartKeysValueExtractor
HIVE_STYLE_PARTITIONING_OPT_KEY -> "true",
HIVE_TABLE_OPT_KEY -> hiveTable)
df.write.format("hudi").
options(hudiOptions).
mode(Overwrite).
save(hudi_basePath)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}
{kind=link}