kirkuz opened a new issue #2323:
URL: https://github.com/apache/hudi/issues/2323
**Describe the problem you faced**
Hi guys, I’ve checked that my data is wandering through partitions, so I
changed **hoodie.bloom.index.update.partition.path** to **true** and
**hoodie.index.type** to **GLOBAL_BLOOM** (cause it’s required when you want to
change the first parameter). However, my upsert of 5 mln rows is taking now too
much time. The difference is significant: **SIMPLE (8 minutes)** vs.
**GLOBAL_BLOOM (3.5 hours)** on the same dataset and the same upsert batch.
**Expected behavior**
By "my data may migrate between partition keys", I mean, record1 could be in
partition1 at t0. at t5, if we get record1 with partition2, my requirement is
that record1 should go into partition2 and record1 from partition1 should get
deleted
**Environment Description**
* Hudi version : 0.60 (EMR 5.32)
* Spark version : 2.4.6
* Hive version : 2.3.7
* Hadoop version : EMR 5.32
* Storage (HDFS/S3/GCS..) : S3
* Running on Docker? (yes/no) : no
**Data setup**
Total parquet dataset size: 88 GB after bulkinsert
Total rows in the dataset: 1 billion rows
Total columns in the dataset: 47 columns
Total number of partitions in the dataset: 4088
Partitions are nested (multi-key partitions) by: state and date
Total rows in one batch for upsert: 8.5 mln rows
Total number of partitions to be upserted: 213
**Hardware setup**
EMR (5.32) cluster used for this operation: 1 master and 6 cores
(r5d.4xlarge) with in total 112 vCores, 896 GB RAM, 4.2 TB SSD
**GLOBAL_BLOOM configuration**
`hudi_options = {
"hoodie.clean.automatic": "false",
"hoodie.index.type": "GLOBAL_BLOOM",
"hoodie.bloom.index.update.partition.path": "true",
"hoodie.table.name": tableName,
"hoodie.datasource.write.recordkey.field": recordKey,
"hoodie.datasource.write.partitionpath.field": partitionKey,
"hoodie.datasource.write.table.name": tableName,
"hoodie.datasource.write.operation": "upsert",
"hoodie.datasource.write.precombine.field": precombineKey,
"hoodie.upsert.shuffle.parallelism": 300,
"hoodie.insert.shuffle.parallelism": 300,
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.database": hiveDatabaseName,
"hoodie.datasource.hive_sync.table": tableName,
"hoodie.datasource.hive_sync.partition_fields": partitionKey,
"hoodie.datasource.hive_sync.use_jdbc": "true",
"hoodie.datasource.hive_sync.assume_date_partitioning": "false",
"hoodie.datasource.write.hive_style_partitioning": "true",
"hoodie.datasource.write.keygenerator.class":
"org.apache.hudi.keygen.ComplexKeyGenerator",
'hoodie.datasource.hive_sync.partition_extractor_class':
'org.apache.hudi.hive.MultiPartKeysValueExtractor',
}`
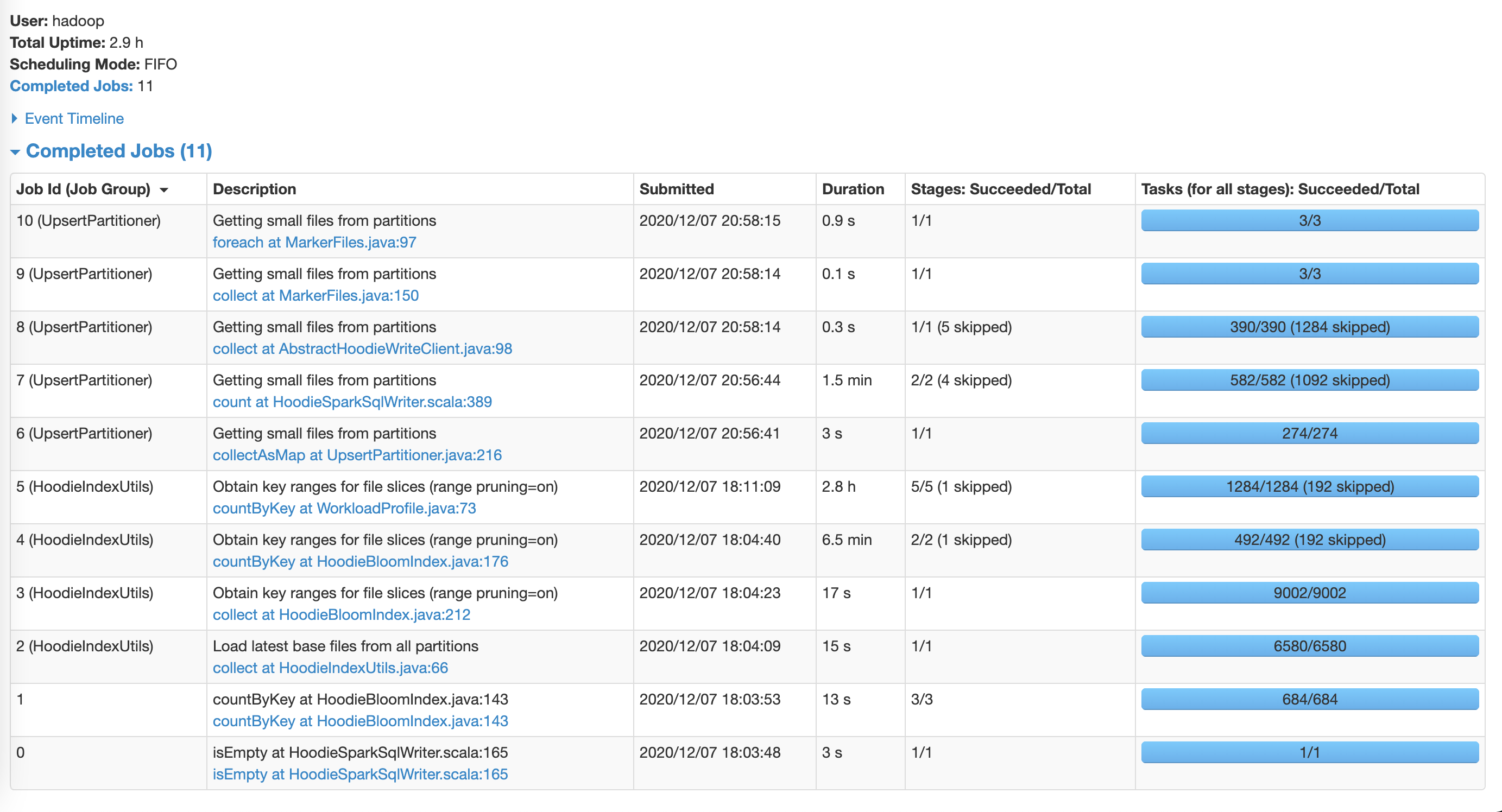
The most expensive step:

**SIMPLE configuration**
`# set global params for all tables
hudi_options = {
"hoodie.clean.async": "true",
"hoodie.clean.automatic": "false",
"hoodie.index.type": "SIMPLE",
"hoodie.table.name": tableName,
"hoodie.datasource.write.recordkey.field": recordKey,
"hoodie.datasource.write.table.name": tableName,
"hoodie.datasource.write.operation": "upsert",
"hoodie.datasource.write.precombine.field": precombineKey,
"hoodie.upsert.shuffle.parallelism": 300,
"hoodie.insert.shuffle.parallelism": 300,
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.database": hiveDatabaseName,
"hoodie.datasource.hive_sync.table": tableName,
"hoodie.datasource.hive_sync.use_jdbc": "true",
"hoodie.datasource.hive_sync.assume_date_partitioning": "false",
"hoodie.datasource.write.hive_style_partitioning": "true",
}
# if no partition key specified
if partitionKey == "0":
hudi_options["hoodie.datasource.write.partitionpath.field"] = ""
hudi_options["hoodie.datasource.write.keygenerator.class"] =
"org.apache.hudi.keygen.NonpartitionedKeyGenerator"
hudi_options["hoodie.datasource.hive_sync.partition_fields"] = ""
hudi_options["hoodie.datasource.hive_sync.partition_extractor_class"] =
"org.apache.hudi.hive.NonPartitionedExtractor"
else:
hudi_options["hoodie.datasource.write.partitionpath.field"] =
partitionKey
hudi_options["hoodie.datasource.write.keygenerator.class"] =
"org.apache.hudi.keygen.SimpleKeyGenerator"
hudi_options["hoodie.datasource.hive_sync.partition_fields"] =
partitionKey`
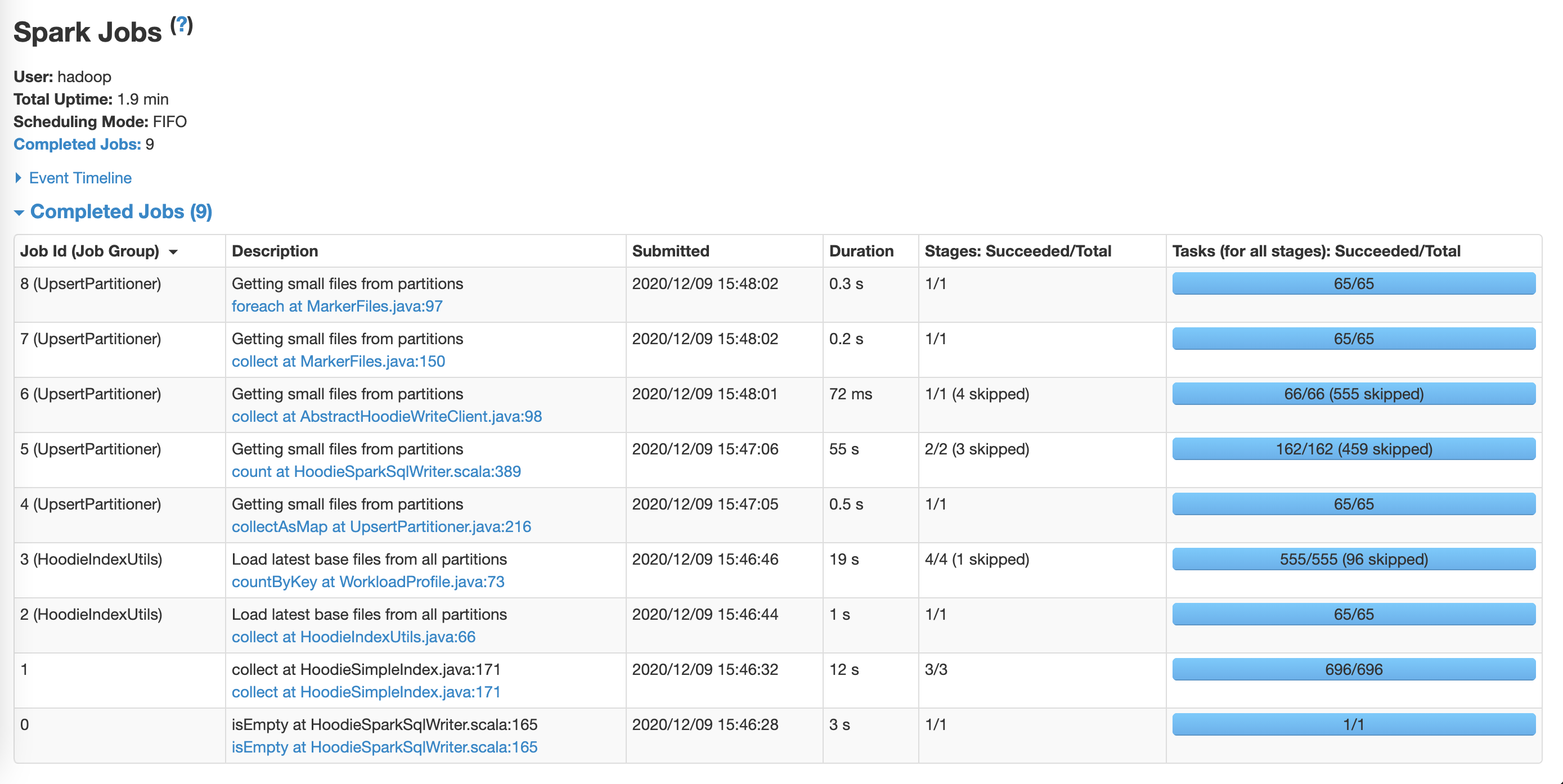
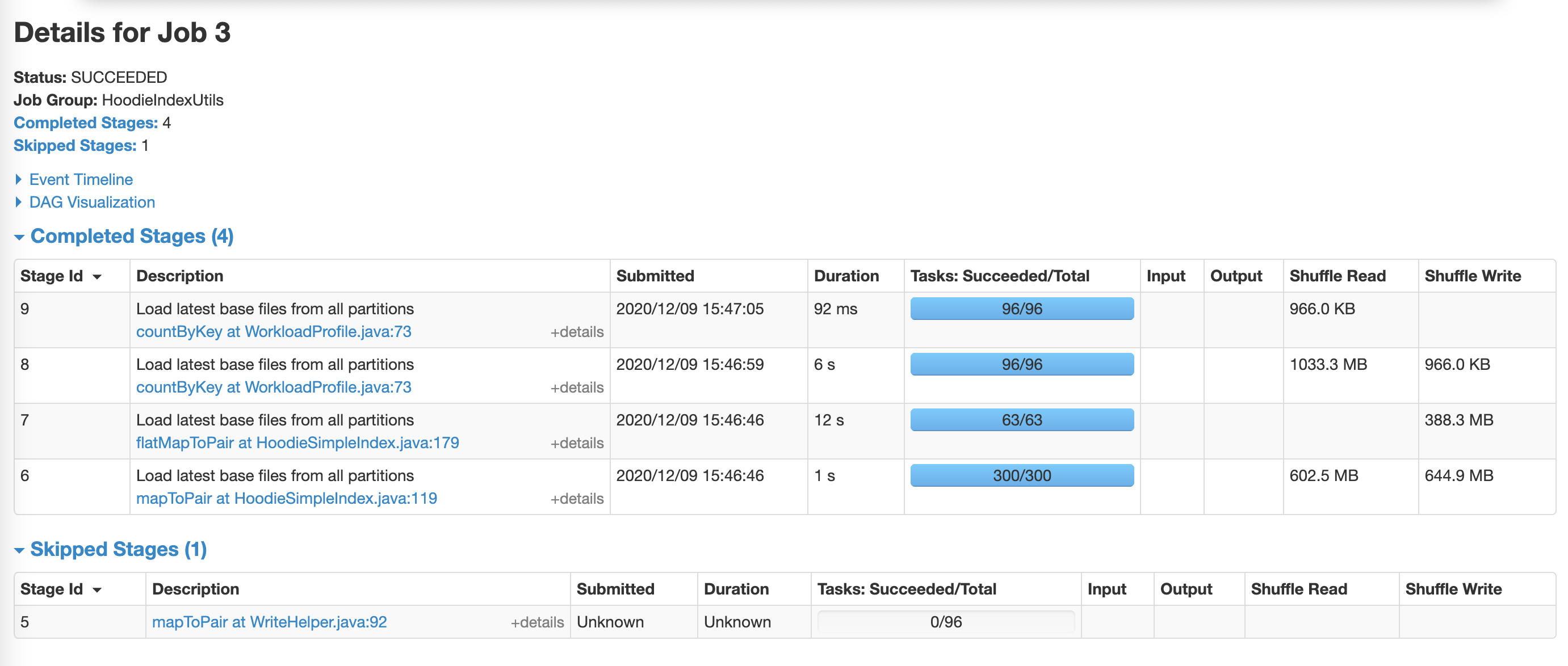
**Spark configuration**
I'm using:
spark.dynamicAllocation.enabled = true
maximizeResourceAllocation = true
I was trying to parametrize spark due to this advice, but it was much slower
then dynamicAllocation
https://aws.amazon.com/blogs/big-data/best-practices-for-successfully-managing-memory-for-apache-spark-applications-on-amazon-emr/
Spark submit query:
`spark-submit --deploy-mode client --jars
/usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-avro.jar
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf
spark.sql.hive.convertMetastoreParquet=false my_script.py param1 param2 paramN`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}