WTa-hash edited a comment on issue #2229: URL: https://github.com/apache/hudi/issues/2229#issuecomment-754894794
@bvaradar - I would like to understand a little bit more about what's going on here with the spark stage "Getting small files from partitions" from the screenshot. 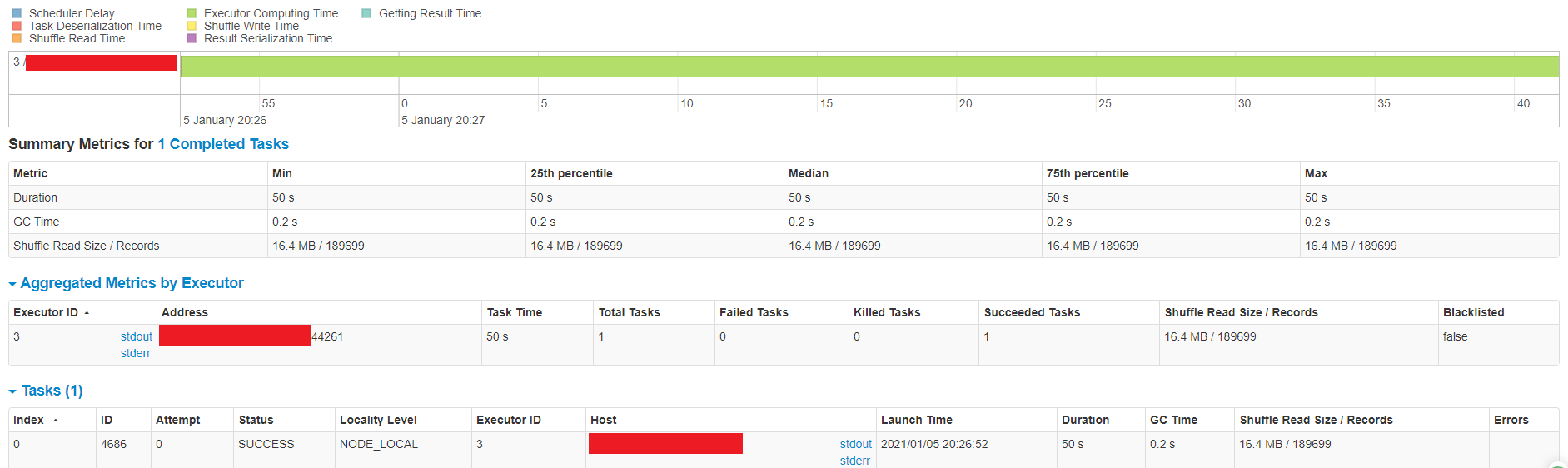 In the executor logs, I see the following: `2021-01-05 20:26:52,176 INFO [dispatcher-event-loop-1] org.apache.spark.executor.CoarseGrainedExecutorBackend:Got assigned task 4686 2021-01-05 20:26:52,176 INFO [Executor task launch worker for task 4686] org.apache.spark.executor.Executor:Running task 0.0 in stage 701.0 (TID 4686) 2021-01-05 20:26:52,176 INFO [Executor task launch worker for task 4686] org.apache.spark.MapOutputTrackerWorker:Updating epoch to 202 and clearing cache 2021-01-05 20:26:52,177 INFO [Executor task launch worker for task 4686] org.apache.spark.broadcast.TorrentBroadcast:Started reading broadcast variable 502 2021-01-05 20:26:52,178 INFO [Executor task launch worker for task 4686] org.apache.spark.storage.memory.MemoryStore:Block broadcast_502_piece0 stored as bytes in memory (estimated size 196.8 KB, free 4.3 GB) 2021-01-05 20:26:52,178 INFO [Executor task launch worker for task 4686] org.apache.spark.broadcast.TorrentBroadcast:Reading broadcast variable 502 took 1 ms 2021-01-05 20:26:52,180 INFO [Executor task launch worker for task 4686] org.apache.spark.storage.memory.MemoryStore:Block broadcast_502 stored as values in memory (estimated size 637.1 KB, free 4.3 GB) 2021-01-05 20:26:52,198 INFO [Executor task launch worker for task 4686] org.apache.spark.MapOutputTrackerWorker:Don't have map outputs for shuffle 201, fetching them 2021-01-05 20:26:52,198 INFO [Executor task launch worker for task 4686] org.apache.spark.MapOutputTrackerWorker:Doing the fetch; tracker endpoint = NettyRpcEndpointRef(spark://MapOutputTracker@ip-xxx-xx-xxx-xxx:35039) 2021-01-05 20:26:52,199 INFO [Executor task launch worker for task 4686] org.apache.spark.MapOutputTrackerWorker:Got the output locations 2021-01-05 20:26:52,199 INFO [Executor task launch worker for task 4686] org.apache.spark.storage.ShuffleBlockFetcherIterator:Getting 18 non-empty blocks including 6 local blocks and 12 remote blocks 2021-01-05 20:26:52,199 INFO [Executor task launch worker for task 4686] org.apache.spark.storage.ShuffleBlockFetcherIterator:Started 2 remote fetches in 0 ms 2021-01-05 20:26:53,287 INFO [Executor task launch worker for task 4686] com.amazon.ws.emr.hadoop.fs.s3n.MultipartUploadOutputStream:close closed:false s3://...table/.hoodie/.temp/20210105202638/1900-01-01/6ac65ea6-5378-4022-9a54-dfda75d6b53d-0_0-701-4686_20210105202638.parquet.marker.MERGE 2021-01-05 20:26:53,384 INFO [pool-22-thread-1] com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem:Opening 's3://...table/1900-01-01/6ac65ea6-5378-4022-9a54-dfda75d6b53d-0_0-659-4407_20210105202508.parquet' for reading 2021-01-05 20:27:40,841 INFO [Executor task launch worker for task 4686] com.amazon.ws.emr.hadoop.fs.s3n.MultipartUploadOutputStream:close closed:false s3://...table/1900-01-01/6ac65ea6-5378-4022-9a54-dfda75d6b53d-0_0-701-4686_20210105202638.parquet 2021-01-05 20:27:41,708 INFO [Executor task launch worker for task 4686] org.apache.spark.storage.memory.MemoryStore:Block rdd_2026_0 stored as values in memory (estimated size 390.0 B, free 4.3 GB) 2021-01-05 20:27:41,713 INFO [Executor task launch worker for task 4686] org.apache.spark.executor.Executor:Finished task 0.0 in stage 701.0 (TID 4686). 3169 bytes result sent to driver ` Does this mean the 50 seconds for this task is used to create a SINGLE new parquet file with the new data using the "small parquet file" as its base? If my thoughts are correct here, is there a configuration to split the records evenly into each executor so that you can have multiple writes occurring in parallel? ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}