vinothchandar edited a comment on pull request #2441: URL: https://github.com/apache/hudi/pull/2441#issuecomment-761742963
On a 250K file table, with 1000 partitions. Baseline single threaded listing : 2mins Parallelized listing from Spark (which is what most of Hudi already does) takes 18 seconds 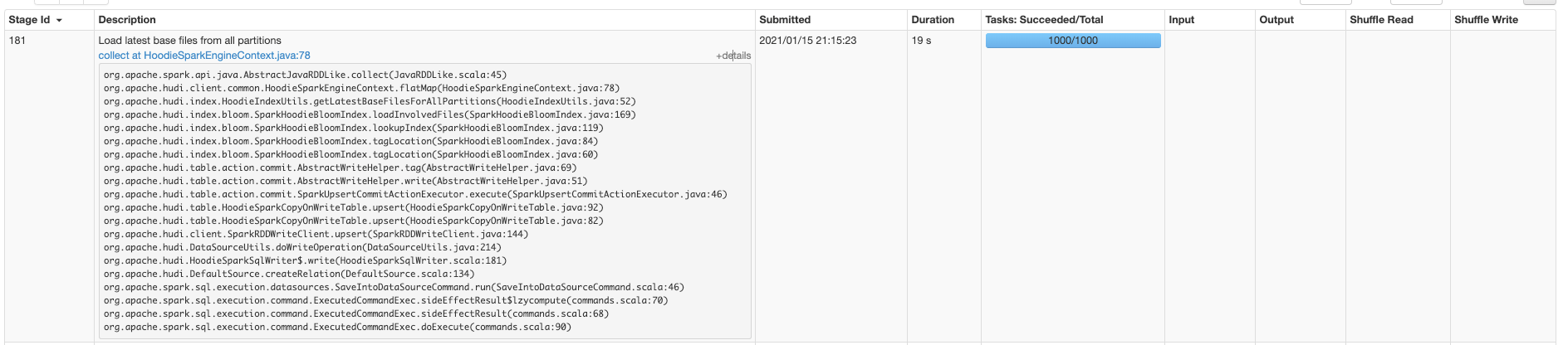 Metadata table is ~2x faster!! (timeline server=on) 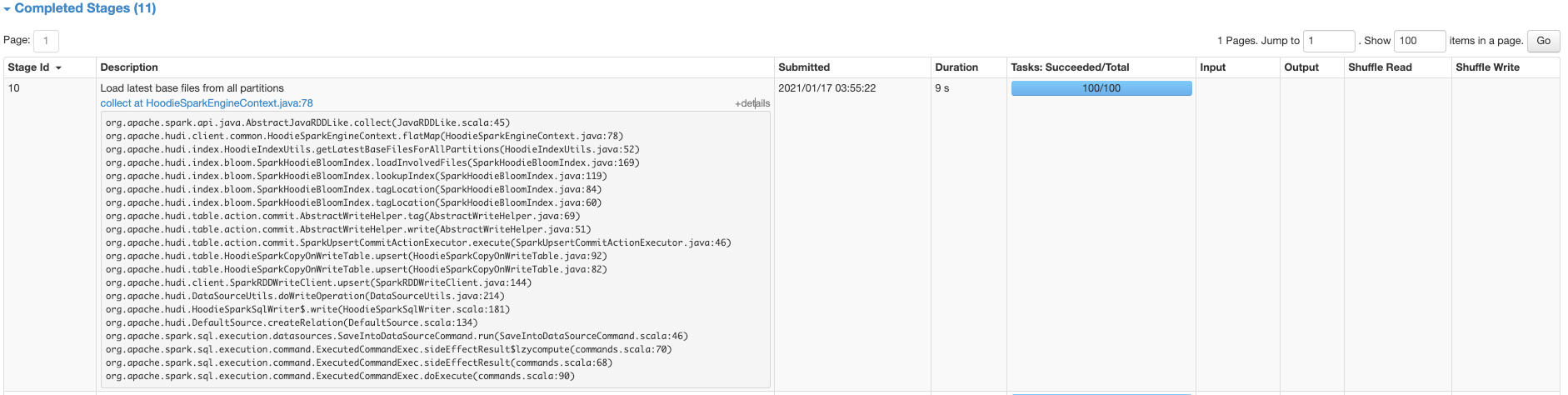 Metadata table is fast, even with parallel access from executors !! (timeline server=off) 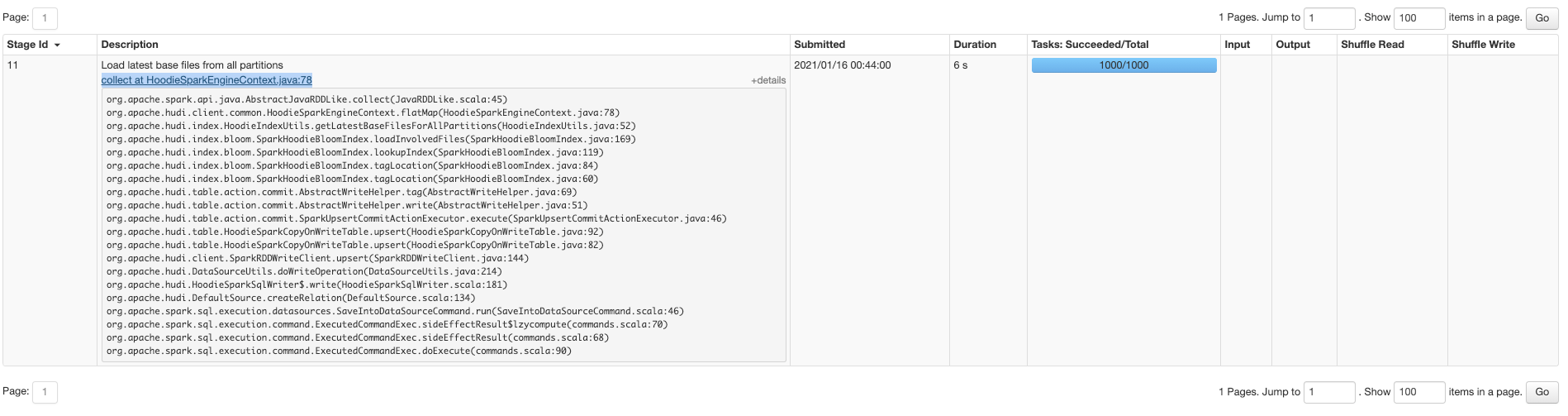 ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}