kimberlyamandalu opened a new issue #2696: URL: https://github.com/apache/hudi/issues/2696
I am getting the following set of errors when running a Pyspark Streaming job in AWS Glue and upserting to a Hudi Dataset in S3. Glue version: 2 Python version: 3 Spark version: 2 Hudi version: 0.7.0 `ERROR BaseTableMetadata: Failed to retrieve files in partition s3://mybucket/mydb/mytable/myear=2020/mmonth=3 from metadata` `ERROR FileSystemViewHandler: Got runtime exception servicing request partition=myear%3D2020%2Fmmonth%3D3&maxinstant=20210318163420&basepath=s3%3A%2F%2Fmybucket%2Fmydb%2Fmytable%2F&lastinstantts=20210318171415&timelinehash=c2fb0afdb102e7c3c543109e7df1c954b5aea0e738db1e4d644d9a832baf3d0b` `WARN ExceptionMapper: Uncaught exception` There are a lot of these in my log file. I don't see any failed tasks in my spark ui. But I do see some jobs running for a long time. I have posted screenshots of my sparkui for a microbatch. Can I get some assistance to troubleshoot what might be going on?  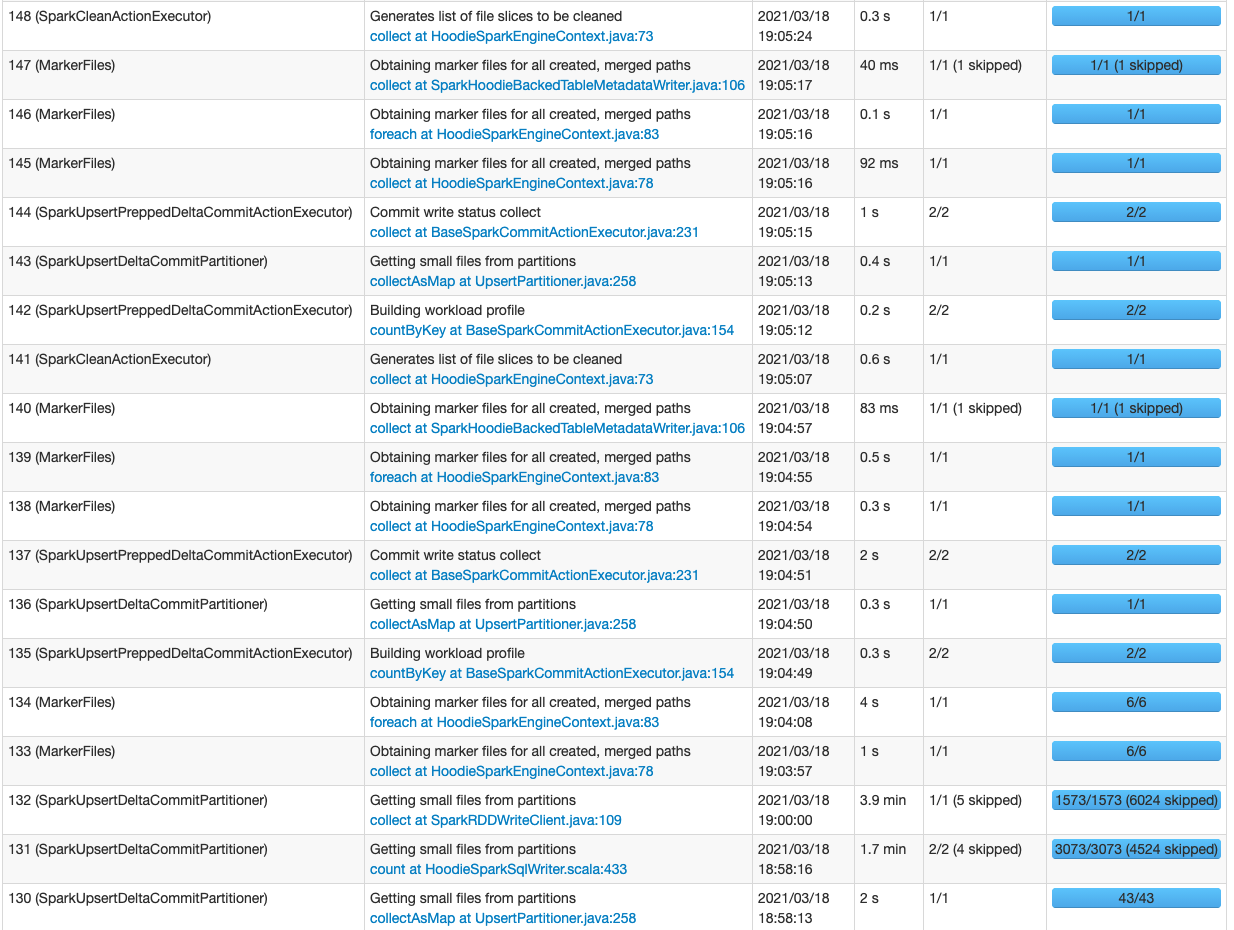 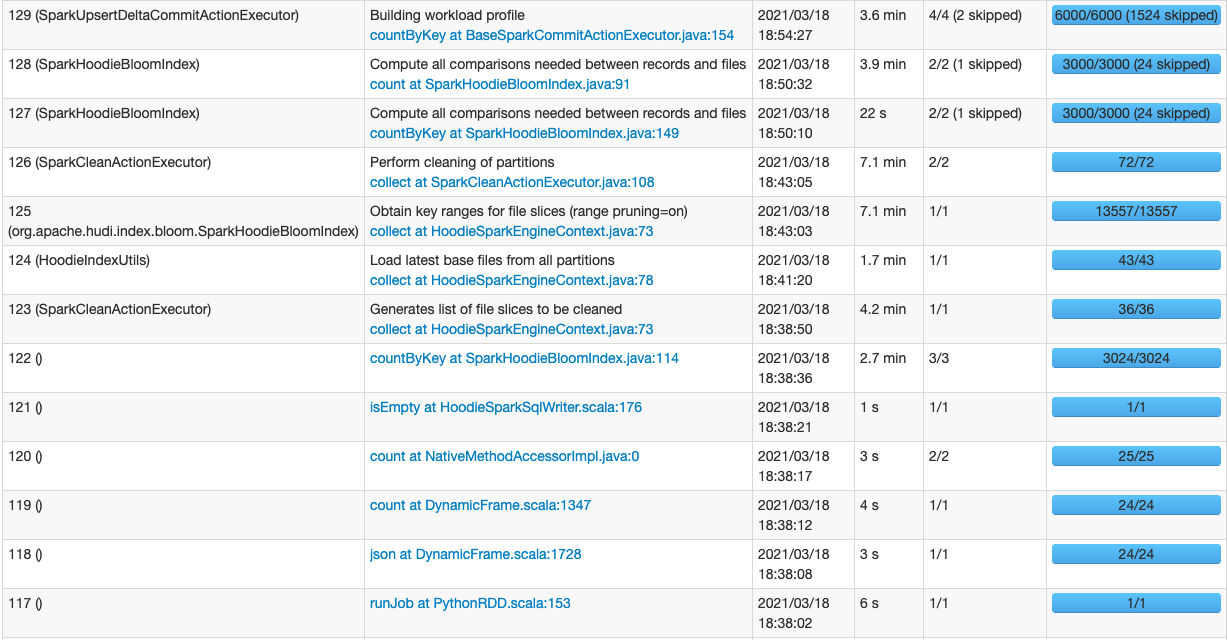 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}