AirToSupply opened a new issue #2976: URL: https://github.com/apache/hudi/issues/2976
**To Reproduce** Steps to reproduce the behavior: 1.Build from source with branch [master], the version is 0.9.0-SNAPSHOT. 2.Start a Fink1.12.x streaming job, read data from hudi table to test. 3.Online observation, the exception caused the flink job to fail **Expected behavior** java.lang.IllegalArgumentException: Unexpected type: ... A clear and concise description of what you expected to happen. **Environment Description** * Hudi version : 0.9.0-SNAPSHOT * Spark version : None * Hive version : None * Hadoop version : 2.9.2 * Storage (HDFS/S3/GCS..) : HDFS * Running on Docker? (yes/no) : no **Additional context** The timing of the exception is: when the specified partition column field is not at the end of the sequence of fields written to the hudi table. For example, if the order of the fields (including partition columns) written in the hudi table is: col1, col2, col3. At this time, if the partition column field is col1, the exception will be generated. If the partition column field is col3, it can work normally. A clear and concise description of the problem. **Stacktrace** The exception stack is as follows: 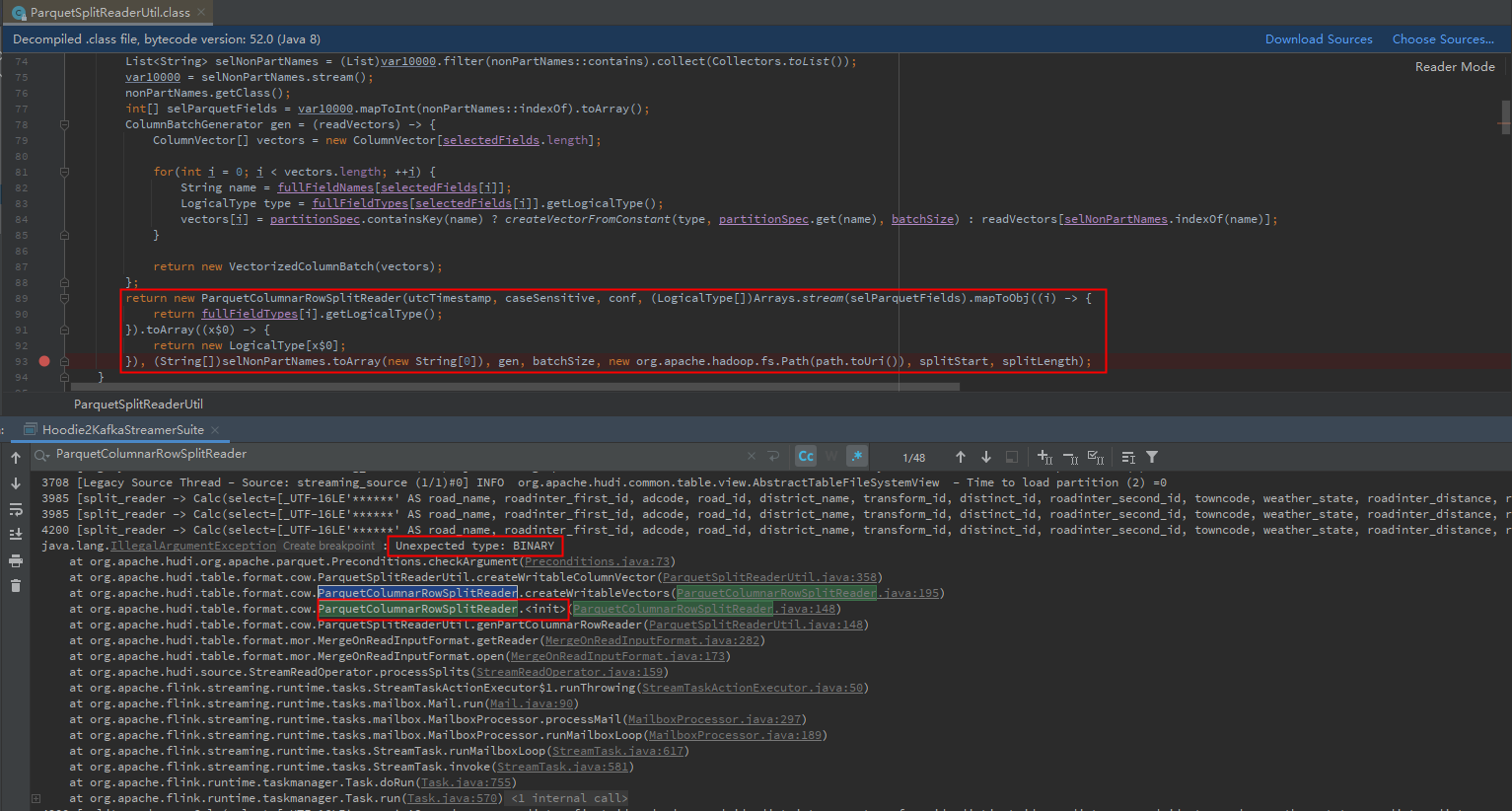 The local debugging is as follows: 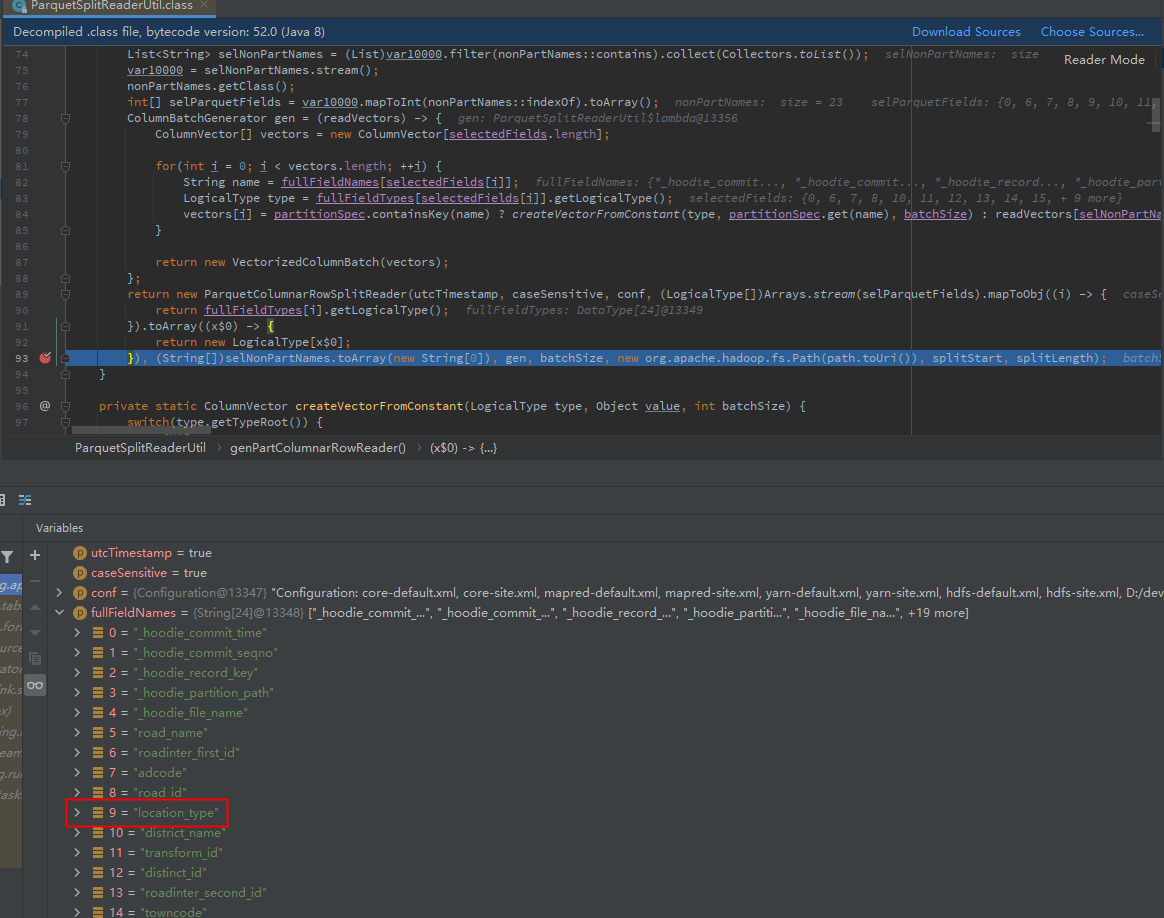 Initial diagnosis reason: When reading the hudi table through Flink, org.apache.hudi.table.format.cow.ParquetSplitReaderUtil#genPartColumnarRowReader will be called. This method returns that the selectedTypes and selectedFieldNames arrays in the ParquetColumnarRowSplitReader object are misaligned. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}