Rap70r edited a comment on issue #3697: URL: https://github.com/apache/hudi/issues/3697#issuecomment-926186766
Hi @xushiyan, We did some tests using a different instance type (20 machines of type m5.2xlarge) and less partitions. Here's the job flow for an upsert of 130K records (330 MB) against a Hudi collection with 230 partitions and 60 million records (6.2 GB) sitting on S3: 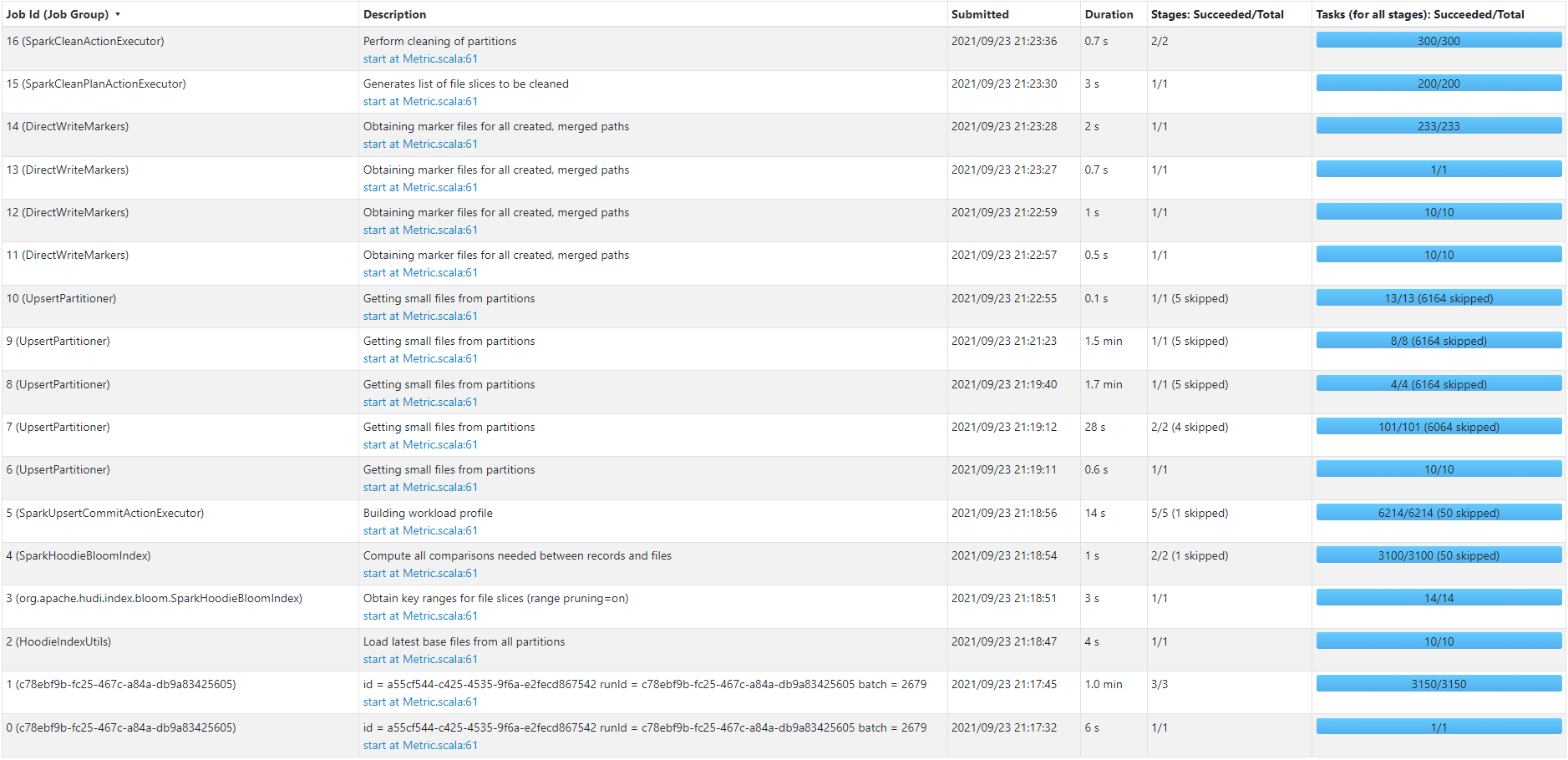 The job took ~6.3 min to finish. We would like to improve that time further. Seems like 6.3 minutes is too much for 130K records using 20 instances of type m5.2xlarge. And it seems like most of the time was taken by UpsertPartitioner step. Do you recommend any further modifications or configurations we could test with to reduce the time? **Spark-Submit Configs** `spark-submit --deploy-mode cluster --conf spark.dynamicAllocation.enabled=true --conf spark.dynamicAllocation.cachedExecutorIdleTimeout=300s --conf spark.dynamicAllocation.executorIdleTimeout=300s --conf spark.scheduler.mode=FAIR --conf spark.memory.fraction=0.4 --conf spark.memory.storageFraction=0.1 --conf spark.shuffle.service.enabled=true --conf spark.sql.hive.convertMetastoreParquet=false --conf spark.sql.parquet.mergeSchema=true --conf spark.driver.maxResultSize=6g --conf spark.driver.memory=12g --conf spark.executor.cores=4 --conf spark.driver.memoryOverhead=4g --conf spark.executor.instances=100 --conf spark.executor.memoryOverhead=4g --conf spark.driver.cores=6 --conf spark.executor.memory=12g --conf spark.rdd.compress=true --conf spark.kryoserializer.buffer.max=512m --conf spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.yarn.nodemanager.vmem-check-enabled=false --conf yarn.nodemanager.pmem-check-enabled=false --conf spark.sql.shuffle.partitions= 100 --conf spark.default.parallelism=100 --conf spark.task.cpus=2` Also, not sure if it helps but we are using below Spark SQL to construct our hoodie_key and hoodie_partition: `CONCAT(trim(string_field), unix_time_field, trim(string_field)) AS hoodie_key` `from_unixtime(substr(unix_time_field, 0, length(unix_time_field) - 3), 'yyyyMM') AS hoodie_partition` Thank you -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}