t822876884 opened a new issue #3711: URL: https://github.com/apache/hudi/issues/3711
**_Tips before filing an issue_** - Have you gone through our [FAQs](https://cwiki.apache.org/confluence/display/HUDI/FAQ)? - Join the mailing list to engage in conversations and get faster support at [email protected]. - If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly. **Describe the problem you faced** A clear and concise description of the problem. **To Reproduce** Steps to reproduce the behavior: 1. 2. 3. 4. **Expected behavior** A clear and concise description of what you expected to happen. **Environment Description** * Hudi version : * Spark version : * Hive version : * Hadoop version : * Storage (HDFS/S3/GCS..) : * Running on Docker? (yes/no) : **Additional context** Add any other context about the problem here. **Stacktrace** ```Add the stacktrace of the error.``` this is example data ```json { "data": { "allocatedMB": -1, "allocatedVCores": -1, "amContainerLogs": "http://10.251.5.216:5008/node/containerlogs/container_e08_1630990426132_290653_01_000002/hive";, "amHostHttpAddress": "10.251.5.216:5008", "amNodeLabelExpression": "", "amRPCAddress": "10.251.5.216:43355", "applicationTags": "", "applicationType": "TEZ", "clusterId": 1630990426132, "clusterUsagePercentage": 0, "diagnostics": "Session stats:submittedDAGs=1, successfulDAGs=1, failedDAGs=0, killedDAGs=0\n", "elapsedTime": 75464, "finalStatus": "SUCCEEDED", "finishedTime": 1632345794876, "id": "application_1630990426132_290653", "logAggregationStatus": "SUCCEEDED", "memorySeconds": 200127, "name": "HIVE-13d2afc5-a34f-4d55-be00-88cf640b4f36", "numAMContainerPreempted": 0, "numNonAMContainerPreempted": 0, "preemptedResourceMB": 0, "preemptedResourceVCores": 0, "priority": "0", "progress": 100, "queue": "root.default", "queueUsagePercentage": 0, "runningContainers": -1, "startedTime": 1632345719412, "state": "FINISHED", "trackingUI": "History", "trackingUrl": "http://10.251.5.44:5004/proxy/application_1630990426132_290653/";, "unmanagedApplication": false, "user": "hive", "vcoreSeconds": 97 }, "datetime": 1632397742386, "id": "application_1630990426132_290653", "type": "yarn" } ``` this is schema.avsc ```json { "type":"record", "name":"stock_ticks", "fields":[{ "name": "id", "type": "string" },{ "name": "type", "type": "string" },{ "name": "data", "type": "row" },{ "name": "datetime", "type": "long" }] } ``` test.java ```java public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); /** * checkpoint */ env.enableCheckpointing(5000L); env.setStateBackend(new FsStateBackend("hdfs://hzwtest/tmp/bertram/hudi_on_flink_cp")); Configuration configuration = new Configuration(); configuration.setString("table-type","COPY_ON_WRITE"); configuration.setString("target-base-path", "hdfs://hzwtest/tmp/bertram/big_data_analyse"); configuration.setString("target-table", "hudi_on_flink"); configuration.setString("props", "hdfs://hzwtest/tmp/bertram/hudi-conf.properties"); configuration.setString("read-schema-path", "hdfs://hzwtest/tmp/bertram/schema.avsc"); configuration.setString("read.avro-schema.path", "hdfs://hzwtest/tmp/bertram/schema.avsc"); configuration.setString("partition-path-field" , "datetime"); configuration.setString("source-ordering-field","datetime"); configuration.setString("record-key-field","id"); env.getConfig().setGlobalJobParameters(configuration); Properties kafkaProps = kafkaProperties(); RowType rowType = (RowType) AvroSchemaConverter.convertToDataType(StreamerUtil.getSourceSchema(configuration)) .getLogicalType(); DataStream<RowData> dataStream = env.addSource(new FlinkKafkaConsumer<>( "big_data_analyse", new JsonRowDataDeserializationSchema( rowType, new RowDataTypeInfo(rowType), false, true, TimestampFormat.ISO_8601 ), kafkaProps)); dataStream.filter(new FilterFunction<RowData>() { @Override public boolean filter(RowData value) throws Exception { System.out.println(">>>>>>>>>>>value:"+value); return false; } }); env.addOperator(dataStream.getTransformation()); env.execute("yarn_log_collect"); } ``` when i commit it to yarn i got this 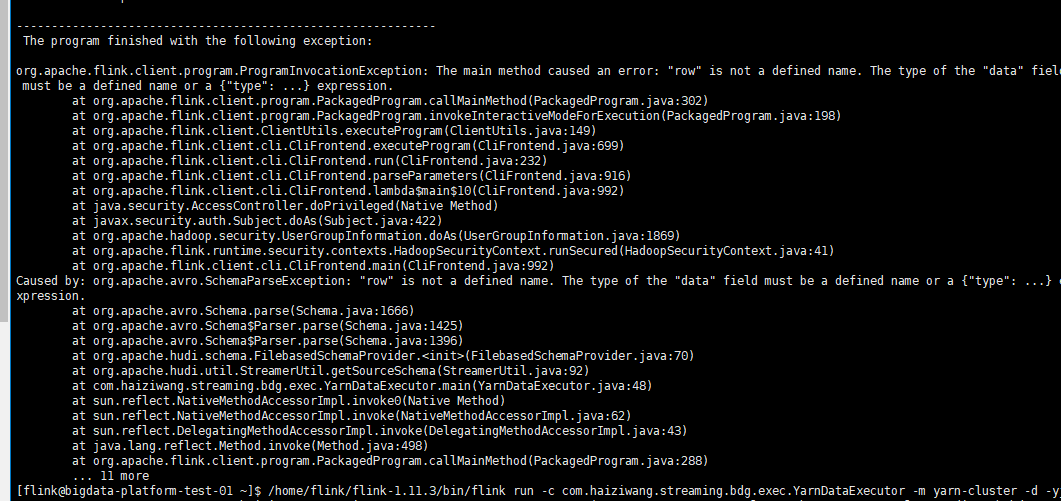 when i change the data type to 'string' i got this  ### How can I parse the data to write to hudi and which type i need choose? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}