davehagman opened a new issue #3733: URL: https://github.com/apache/hudi/issues/3733
**Describe the problem you faced** We're running Hudi 0.9 in production and we are seeing intermittent issues where the latency introduced by index operations spiked to 8-10x longer than usual which causes us to have a much higher write latency into our datalake. I have put some information about our setup below as well as screenshots of the spark UI. You can see in the screenshots that the time it takes to perform the index lookup starts increasing for each batch. I'd like to figure out what could be causing this as it manifests as a large increase in write latency into our production datalake. **To Reproduce** I am unsure of the root-cause of this issue so I do not currently have concrete reproduction steps. **Expected behavior** The time to perform index lookup should not spike 8-10x it's normal latency. **Environment Description** * Hudi version : 0.9.0 * Spark version : 3.1.2 (AWS EMR 6.3.0) * Hadoop version : 3.2.1 * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : no **Additional context** Ingestion Config: * Compute: 150 nodes, m5.4xlarge * Using the Deltastreamer (source = Kafka) * INSERT mode * Drop dupes enabled * Index type: Bloom Dynamic * No changes to default bloom settings * Data is partitioned by: year / month / day / hour 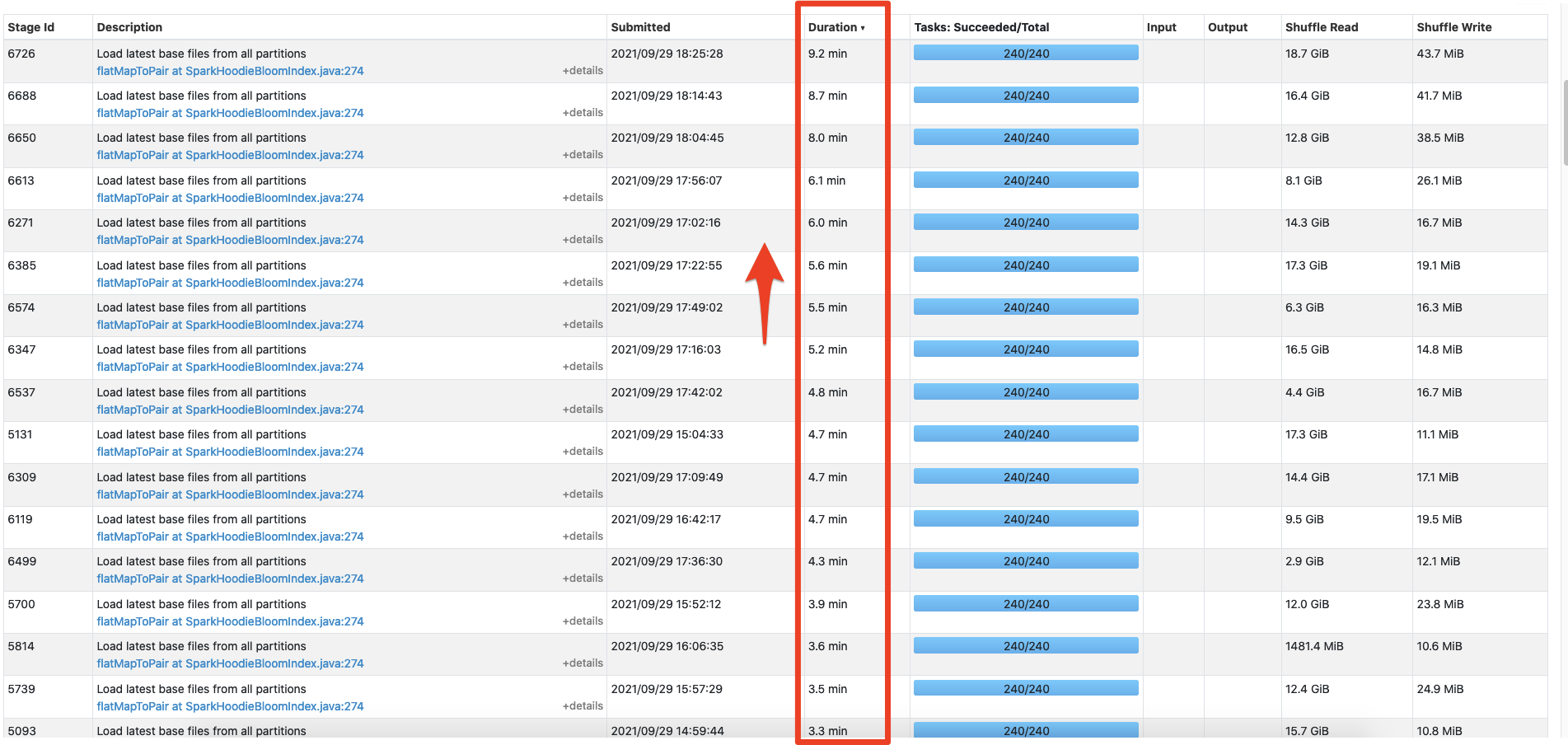 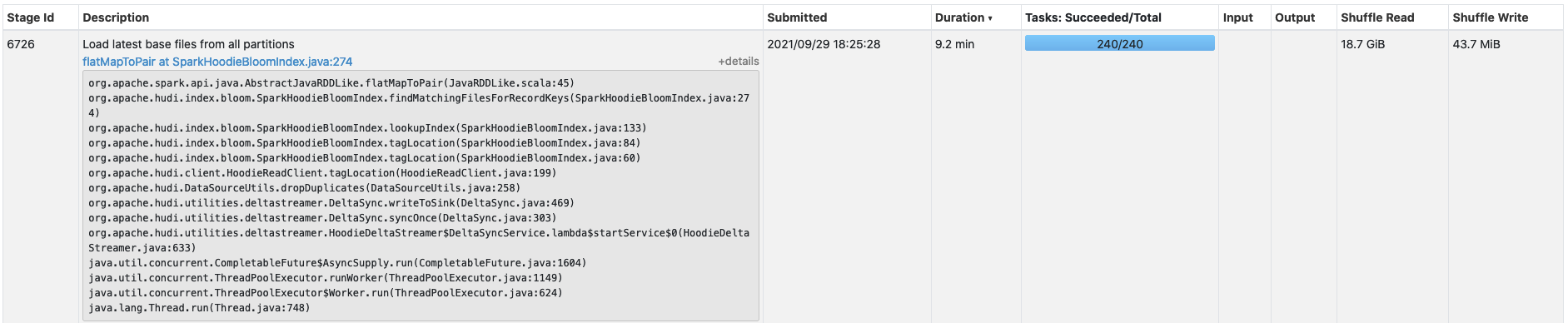 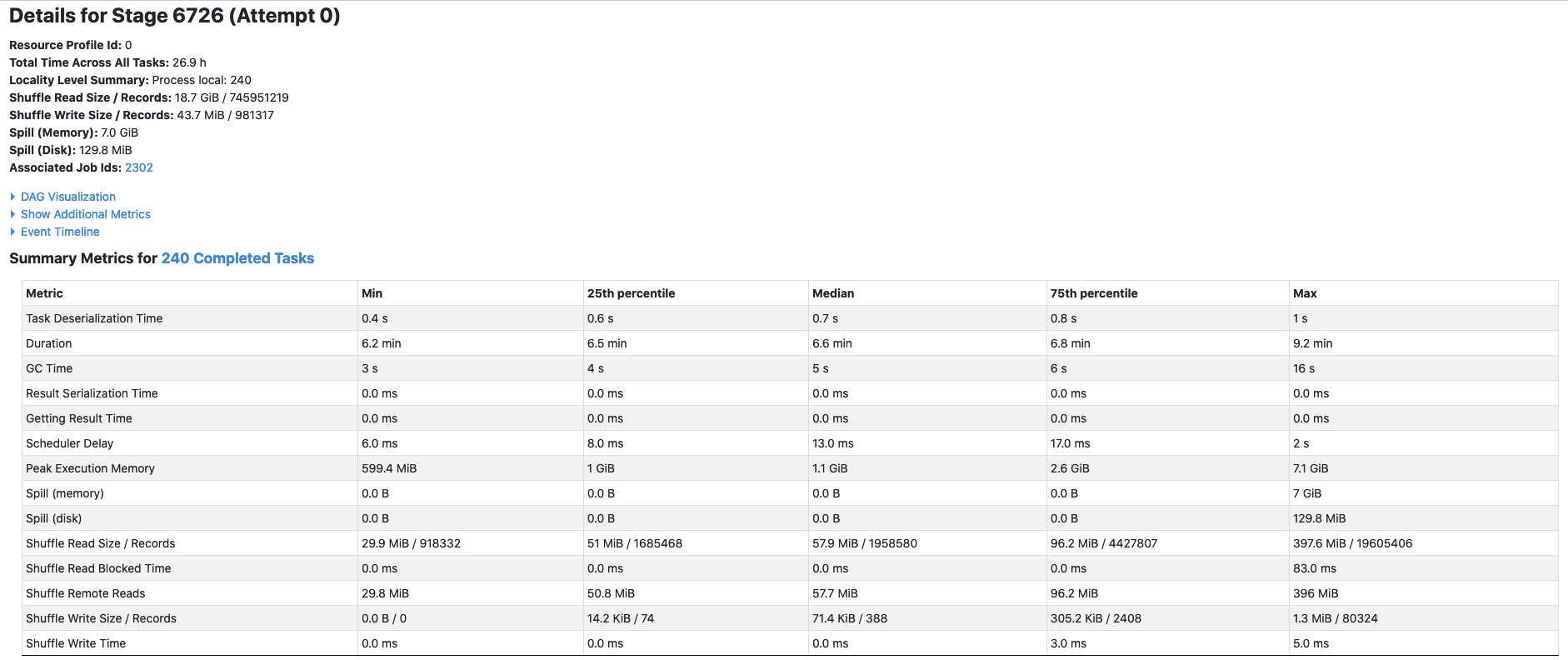 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}