gaoshihang opened a new issue #3790:
URL: https://github.com/apache/hudi/issues/3790
@danny0405 Hi~please help
I use flink-cdc to read binlog data from kafka and pass to hudi table, I
found the initial write will contain duplicate data.
1.job config
(1)left source table:
create table mysql_left_table(
id bigint primary key,
name string
) WITH (
'connector' = 'kafka',
'topic' = 'test4.test_cdc_db.left_table',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'group_mysql_testdb4',
'format' = 'debezium-json',
'scan.startup.mode' = 'earliest-offset',
'debezium-json.schema-include' = 'true'
);
(2) right source table:
create table mysql_right_table(
id bigint primary key,
left_id bigint
) WITH (
'connector' = 'kafka',
'topic' = 'test4.test_cdc_db.right_table',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'group_mysql_testdb5',
'format' = 'debezium-json',
'scan.startup.mode' = 'earliest-offset',
'debezium-json.schema-include' = 'true'
);
(3) hudi table:
create table hudi_left_right(
left_id bigint primary key,
left_name string,
right_id bigint,
`partition` varchar(20)
) partitioned by (`partition`) with (
'connector' = 'hudi',
'table.type' = 'COPY_ON_WRITE',
'path' = 'file:///Users/pgao/flink/flink-1.12.2/hudi/hudi_left_right',
'write.precombine.field' = 'left_id'
);
(4) flink job
insert into hudi_left_right (select a.id as left_id, a.name as left_name,
b.id as right_id, 'par1' from mysql_left_table a left join mysql_right_table b
on a.id = b.id);
2.hudi data
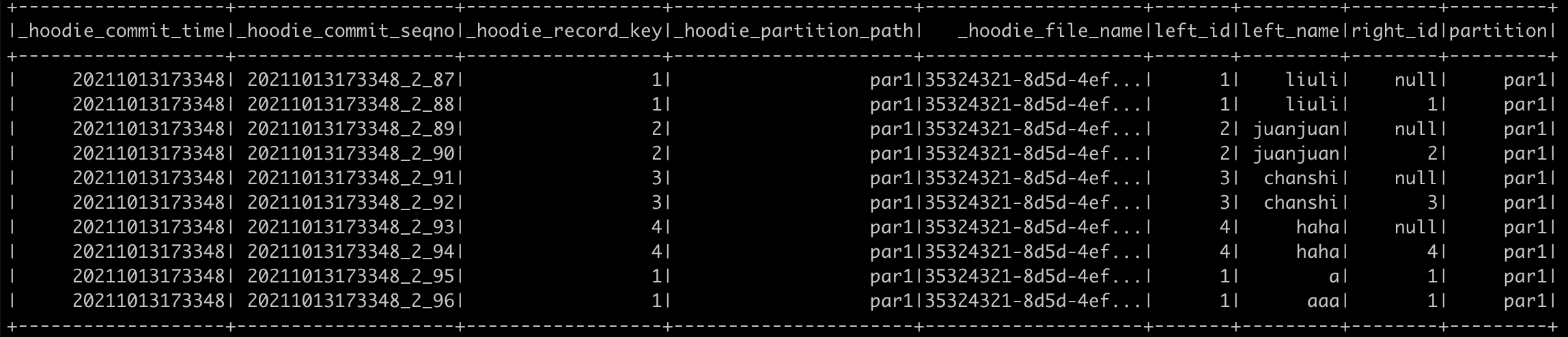
It seems like Hudi doesn't dedup by record_key + partition
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}