rohit-m-99 opened a new issue #3821: URL: https://github.com/apache/hudi/issues/3821
**Describe the problem you faced** Currently running Hudi 0.9.0 in production without a specific partition field. We are running using 6 workers each with 7 cores and 28GB of RAM. The files are stored in S3. We run 50 `runs` each with about `4000` records. When then combine the runs into one dataframe, writing around 200k records at once using the `upsert` operation. Each record has around 280 columns. We see the majority of time being spent `GettingSmallFiles from partitions`. 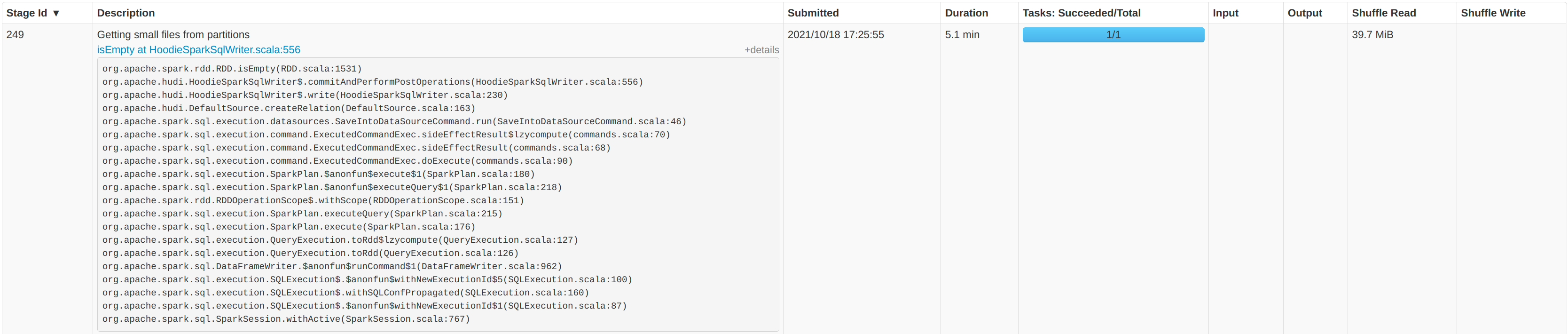   * Hudi version : spark_hudi_0.9.0-SNAPSHOT * Spark version : 3.0.3 * Hadoop version : 3.2.0 * Storage (HDFS/S3/GCS..) : S# * Running on Docker? (yes/no) : K8S -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}