MikeBuh commented on issue #3751: URL: https://github.com/apache/hudi/issues/3751#issuecomment-948557950
So, some of the things have changed and performance has increased but we are still struggling to get the best possible results. Hereunder please find an updated detailed explanation. ### Current Setup **Input Data** - Avro Files - 25MB each - 250 / 6GB per day **Resources** _Tried various configurations and this is the most solid and performant given the available hardware_ - num-executors 19 - executor-cores 1 - executor-memory 6g **Spark Configurations** _Various options and values were tried out but performance change was minimal_ - spark.default.parallelism (currently using 200) - repartition on inputDF (currently using 1,000) - spark.executor.memoryOverhead (using default value) **Hudi Configurations** _Still work in progress on optimising this part as there might be other options which may help boost performance_ - hoodie.datasource.write.operation: UPSERT - hoodie.upsert.shuffle.parallelism: 1000 (tried lower values but performance suffered a bit) - hoodie.datasource.write.row.writer.enable: true **Performance & Notes** - the entire process to upsert one day of data into an existing Hudi table (which is not particularly large) is taking around 20 minutes - whatever parameters we seem to tweak, some stages still have a large amount of spillage and thus slowing down the application (see screen-shot hereunder) - data is being 'compacted' using a simple NiFi flow merging the raw incoming data from Kafka - data seems to be skewed and thus not easy to partition using a field and ensuring even distribution **Deltastreamer** We had given this a shot in the past but had various issues with types in the schema. In addition, we wanted a solution which would allow us to have more control and custom operations on the incoming data before persisting it to Hudi. We really wanted to go for this option but we simply did not see how it was possible and thus we opted to build our own Spark streaming application that fits our use case. 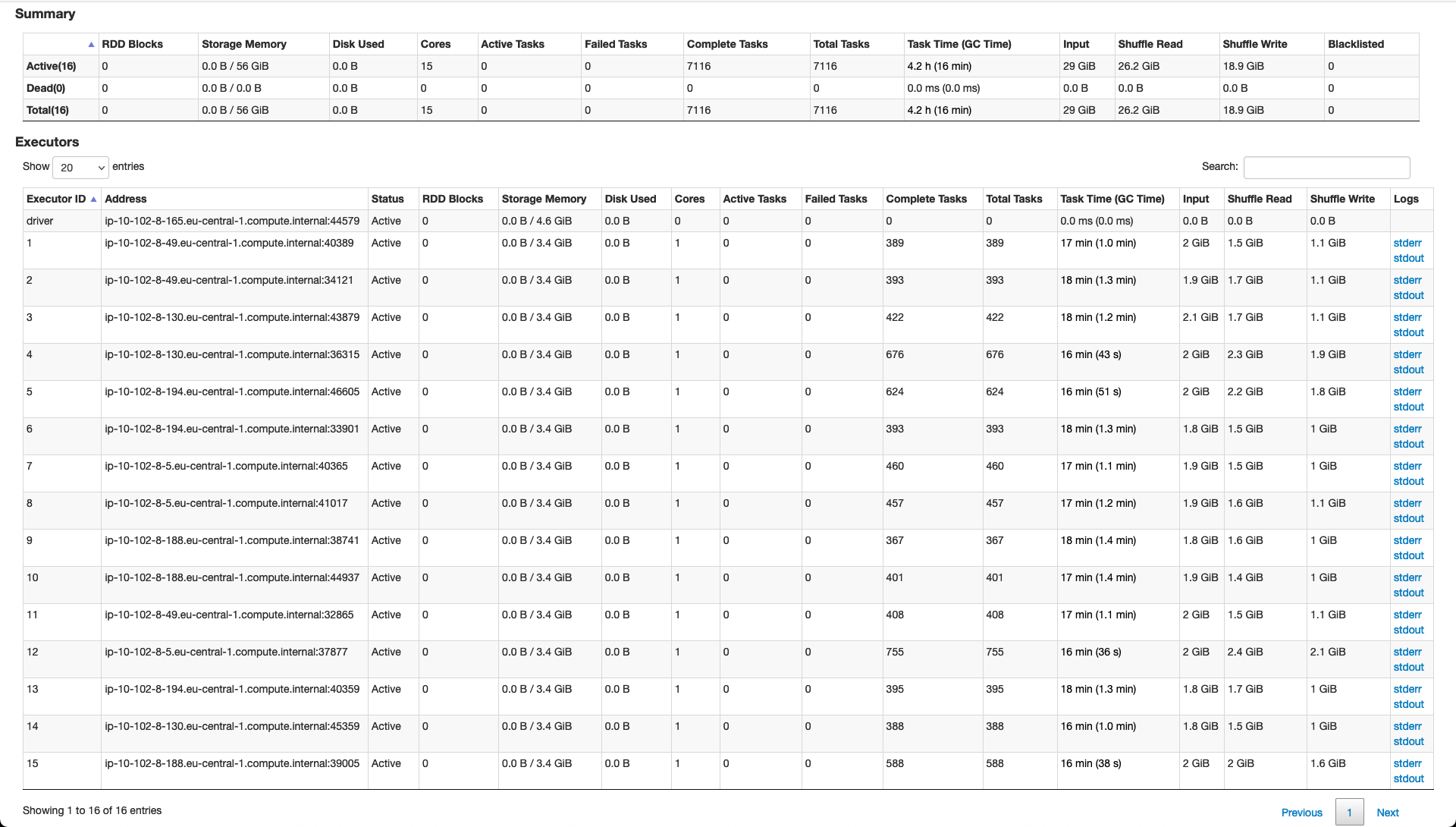 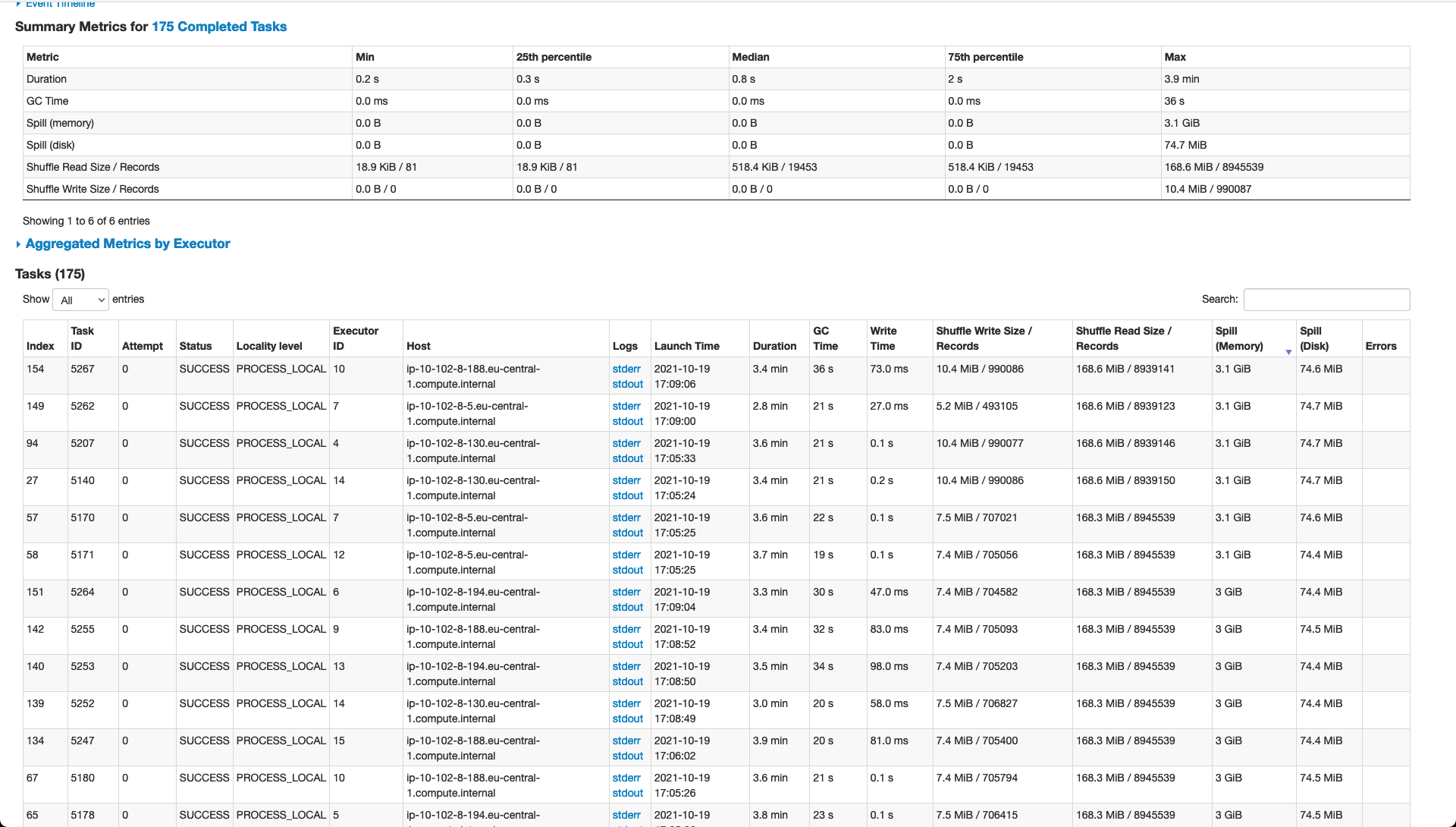 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}