Limess opened a new issue #3854: URL: https://github.com/apache/hudi/issues/3854
**Describe the problem you faced** When benchmarking Hudi on a sample dataset we're seeing 30% lower performance using Hudi 0.9.0 vs Hudi 0.8.0 (on EMR, so technically Amazon's build of Hudi here). 0.8.0 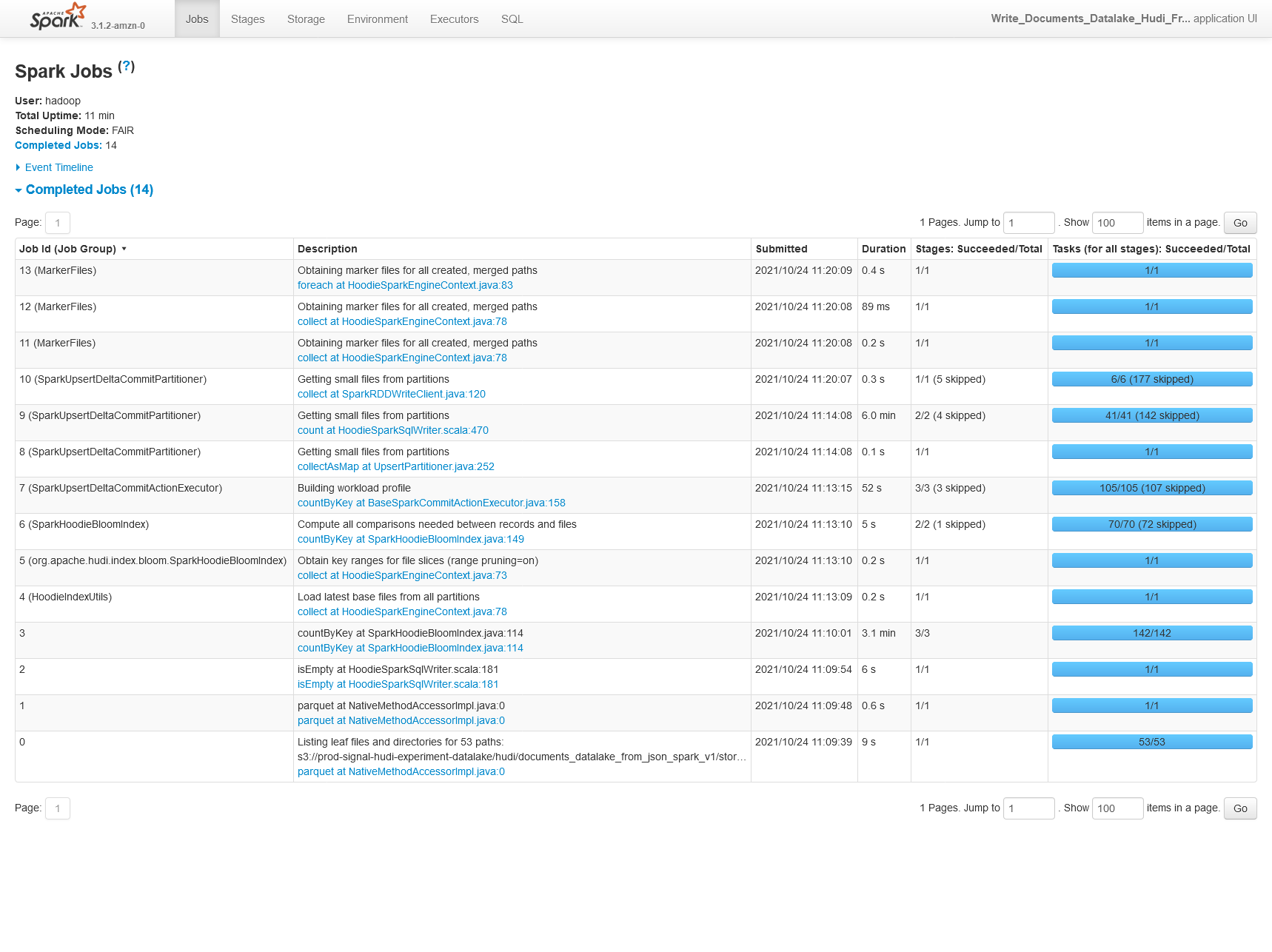 0.9.0 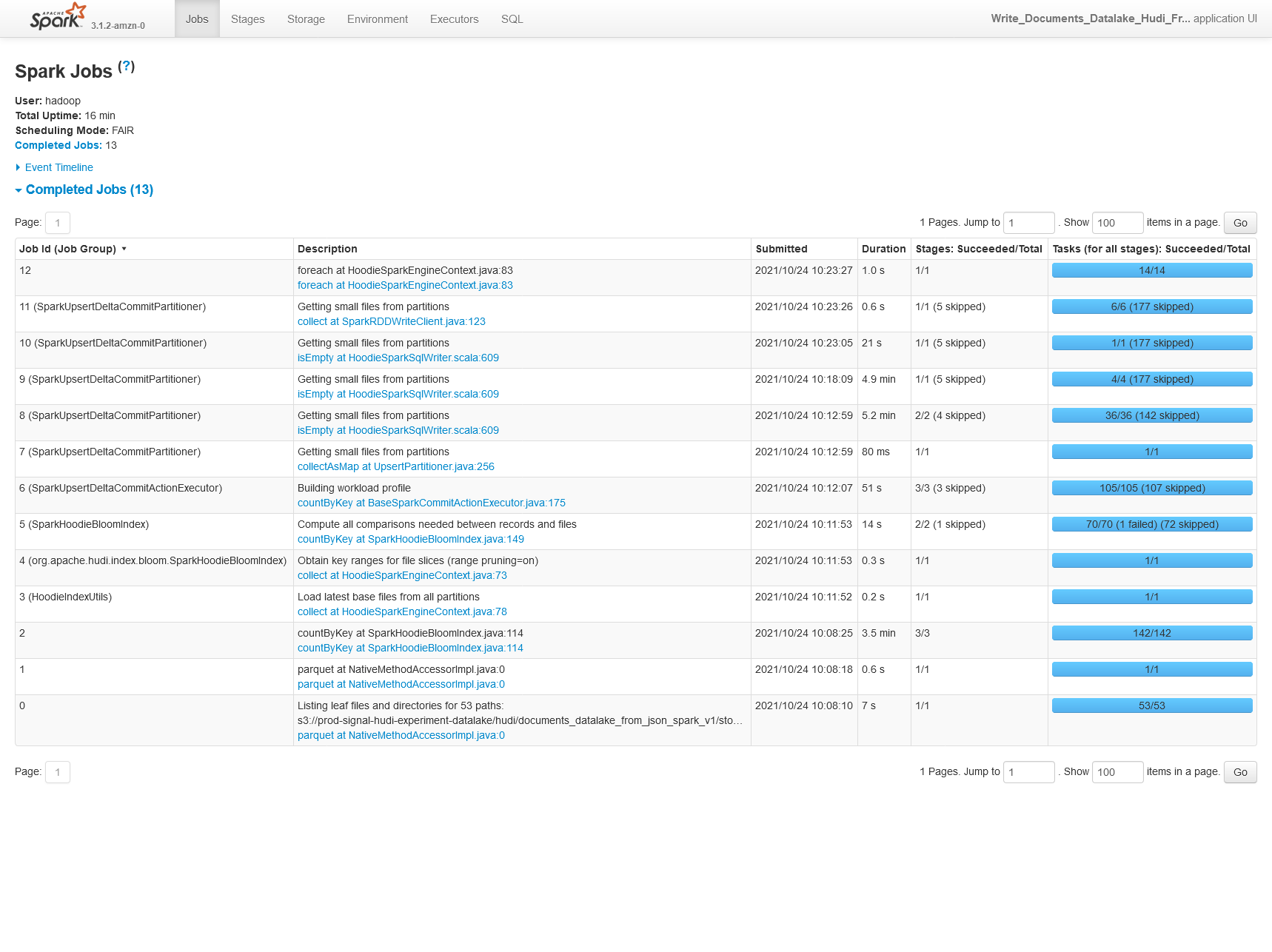 We're also seeing 30% worse performance on CoW upserts of 25% of the original partition storage (50% updates, 50% inserts). 0.8.0 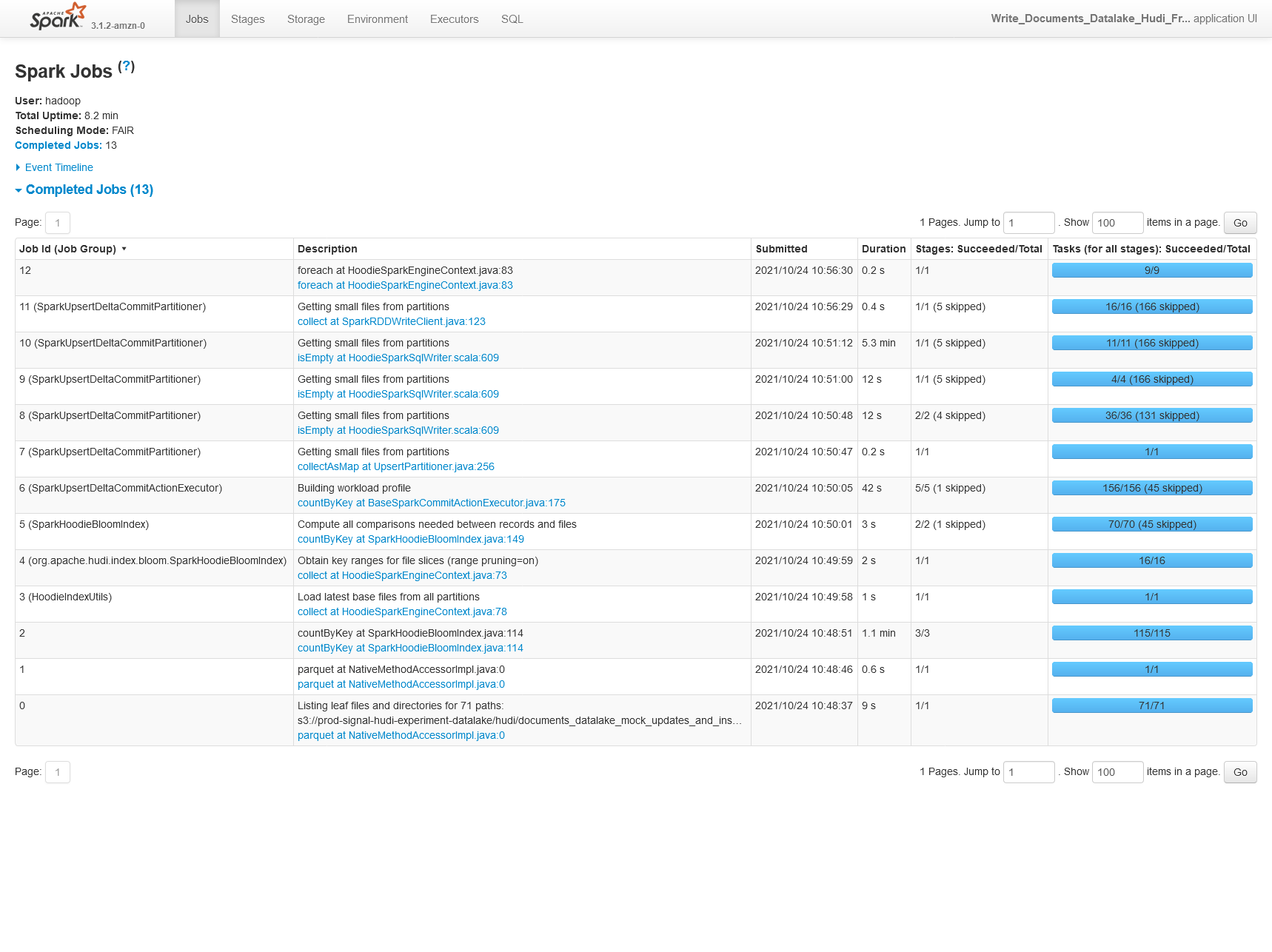 0.9.0 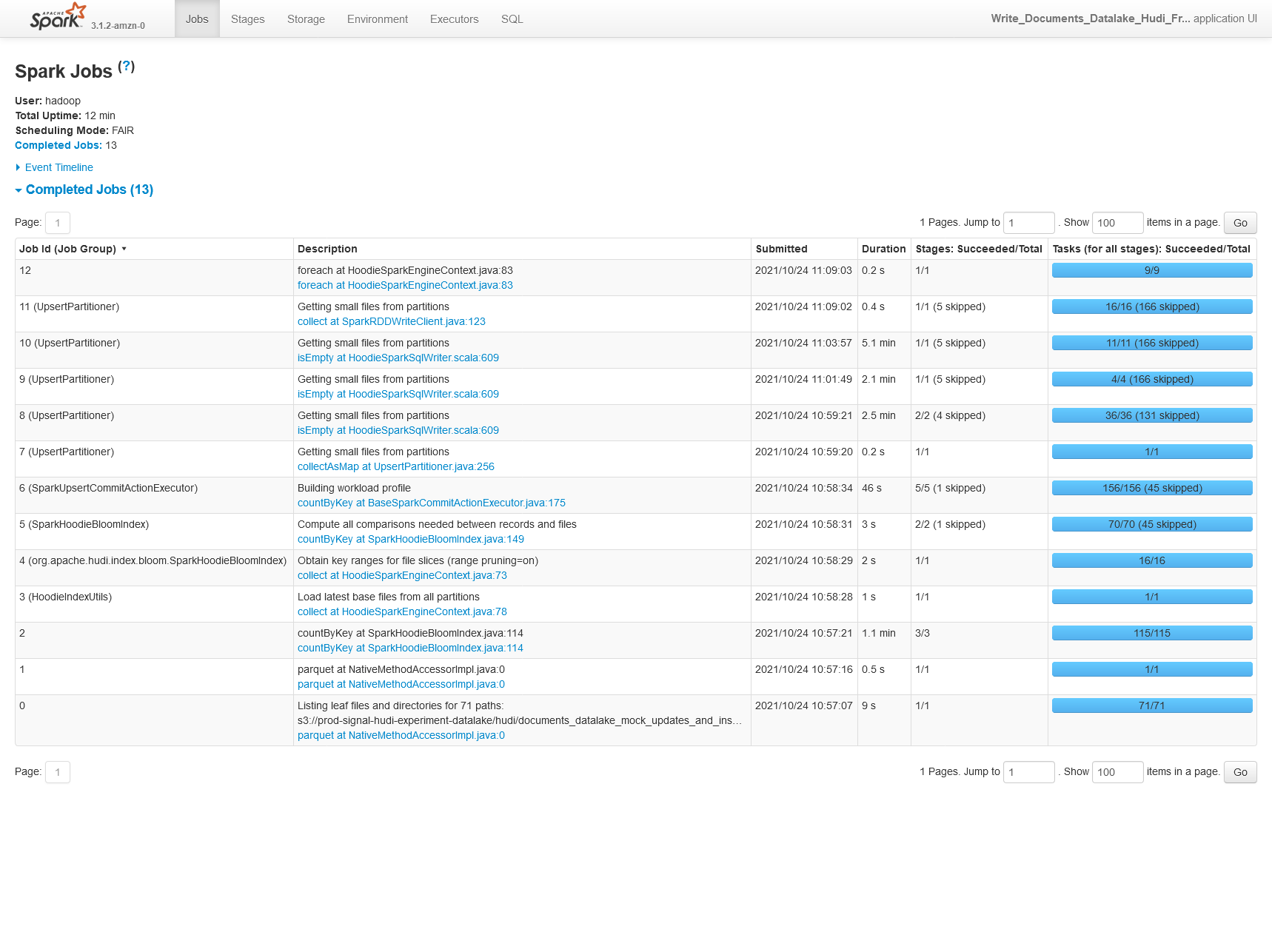 **Config** ``` "hoodie.table.name": hudi_table_name, "hoodie.datasource.write.table.type": hudi_table_type, "hoodie.parquet.max.file.size": str(int(0.5 * 1024.0 * 1024.0 * 1024.0)), "hoodie.parquet.block.size": str(int(0.5 * 1024.0 * 1024.0 * 1024.0)), "hoodie.parquet.small.file.limit": str(int(0.4 * 1024.0 * 1024.0 * 1024.0)), # one of upsert (default), insert or bulk_insert "hoodie.datasource.write.operation": hudi_write_operation, # "hoodie.datasource.write.row.writer.enable": True, "hoodie.datasource.write.recordkey.field": "_id", "hoodie.datasource.write.precombine.field": "processed_date", "hoodie.datasource.write.partitionpath.field": "story_published_date", "hoodie.datasource.write.keygenerator.class": "org.apache.hudi.keygen.TimestampBasedKeyGenerator", "hoodie.deltastreamer.keygen.timebased.timestamp.type": "DATE_STRING", "hoodie.deltastreamer.keygen.timebased.input.dateformat": "yyyy-MM-dd'T'HH:mm:ssZ,yyyy-MM-dd'T'HH:mm:ss.SSSZ", "hoodie.deltastreamer.keygen.timebased.input.dateformat.list.delimiter.regex": ",", "hoodie.deltastreamer.keygen.timebased.input.timezone": "", "hoodie.deltastreamer.keygen.timebased.output.dateformat": "yyyy-MM-dd", "hoodie.deltastreamer.keygen.timebased.output.timezone": "UTC", "hoodie.datasource.hive_sync.partition_extractor_class": "org.apache.hudi.hive.MultiPartKeysValueExtractor", "hoodie.datasource.write.hive_style_partitioning": "true", "hoodie.datasource.hive_sync.enable": "true", "hoodie.datasource.hive_sync.database": "pipeline_reprocessing_hudi_experiment", "hoodie.datasource.hive_sync.table": hudi_table_name, "hoodie.datasource.hive_sync.partition_fields": "story_published_date", "hoodie.datasource.hive_sync.jdbcurl": f"jdbc:hive2://{master_hostname}:10000", "hoodie.write.markers.type": "TIMELINE_SERVER_BASED", "hoodie.datasource.hive_sync.support_timestamp": "true", **Environment Description** EMR 6.4.0 Athena workgroup V2 (experienced on 2021/10/20) Hudi version : Tested on 0.9.0 0.8.0-amzn1 Spark version : 3.1.2 Hive version : Hive 3.1.2 Hadoop version : Amazon 3.2.1 Storage (HDFS/S3/GCS..) : S3 Running on Docker? (yes/no) : no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}