Limess opened a new issue #3933:
URL: https://github.com/apache/hudi/issues/3933
**Describe the problem you faced**
We're seeing slow execution and large amounts of disk spill when loading a
4.3TB JSON dataset using Hudi upsert/bulk insert (we tried both modes).
We didn't see the same behaviour when loading 1 day, or 1 month of the
dataset (the full load is the equivalent of 450 days of data).
**Environment Description**
EMR 6.4.0
Athena workgroup V2 (experienced on 2021/10/20)
* Hudi version :
Tested on
0.9.0
0.8.0-amzn1
* Spark version :
3.1.2
* Hive version :
Hive 3.1.2
* Hadoop version :
Amazon 3.2.1
* Storage (HDFS/S3/GCS..) :
S3
* Running on Docker? (yes/no) :
no
## Additional context
We're using the following EMR cluster:
- Master: m6g.xlarge, 64 GB EBS storage
- Core: 120 x r6g.4xlarge, 512GB EBS storage per node
with this configuration the job eventually succeeds after 1 hour 18 minutes.
If we run with less storage, the job inevitably fails as we experience huge
amounts of disk spill (30TB written to HDFS after a replication factor of 2)
### Settings
EMR:
```
[
{
"Classification": "spark",
"Properties": {
"maximizeResourceAllocation": "false"
}
},
{
"Classification": "spark-defaults",
"Properties": {
"spark.dynamicAllocation.enabled": "false",
"spark.executor.instances": "599",
"spark.executor.cores": "3",
"spark.executor.memory": "19G",
"spark.executor.memoryOverhead": "3072",
"spark.driver.cores": "3",
"spark.driver.memory": "19G",
"spark.driver.memoryOverhead": "3072",
"spark.default.parallelism": "10036",
"spark.sql.shuffle.partitions": "10036",
"spark.yarn.max.executor.failures": "100",
"spark.yarn.maxAppAttempts": "1",
"spark.sql.hive.convertMetastoreParquet": "false",
"spark.scheduler.mode": "FAIR",
"spark.task.maxFailures": "10",
"spark.rdd.compress": "true",
"spark.shuffle.service.enabled": "true",
"spark.serializer":
"org.apache.spark.serializer.KryoSerializer",
"spark.kryoserializer.buffer.max": "256m",
"spark.driver.extraJavaOptions": "-XX:+UseG1GC
-XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark
-XX:InitiatingHeapOccupancyPercent=35",
"spark.executor.extraJavaOptions": "-XX:+UseG1GC
-XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark
-XX:InitiatingHeapOccupancyPercent=35",
"spark.ui.prometheus.enabled": "true",
"spark.metrics.namespace": "spark",
"spark.executor.processTreeMetrics.enabled": "true"
}
},
{
"Classification": "spark-metrics",
"Properties": {
"*.sink.prometheusServlet.class":
"org.apache.spark.metrics.sink.PrometheusServlet",
"*.sink.prometheusServlet.path": "/metrics/prometheus",
"master.sink.prometheusServlet.path":
"/metrics/master/prometheus",
"applications.sink.prometheusServlet.path":
"/metrics/applications/prometheus",
"master.source.jvm.class":
"org.apache.spark.metrics.source.JvmSource",
"worker.source.jvm.class":
"org.apache.spark.metrics.source.JvmSource",
"driver.source.jvm.class":
"org.apache.spark.metrics.source.JvmSource",
"executor.source.jvm.class":
"org.apache.spark.metrics.source.JvmSource"
}
},
{
"Classification": "capacity-scheduler",
"Properties": {
"yarn.scheduler.capacity.resource-calculator":
"org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator "
}
},
{
"Classification": "yarn-site",
"Properties": {
"yarn.nodemanager.vmem-check-enabled": "false",
"yarn.nodemanager.pmem-check-enabled": "false",
"yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage":
"99.0"
}
},
{
"Classification": "hive-site",
"Properties": {
"hive.metastore.client.factory.class":
"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
}
},
{
"Classification": "hdfs-site",
"Properties": {
"dfs.replication": "2"
}
},
{
"Classification": "presto-connector-hive",
"Properties": {
"hive.metastore.glue.datacatalog.enabled": "true",
"hive.parquet.use-column-names": "true"
}
},
{
"Classification": "spark-hive-site",
"Properties": {
"hive.metastore.client.factory.class":
"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
}
}
]
```
Hudi:
```
"hoodie.table.name": hudi_table_name,
"hoodie.datasource.write.table.type": hudi_table_type,
"hoodie.datasource.write.operation": "bulk_insert",
"hoodie.datasource.write.recordkey.field": "id",
"hoodie.datasource.write.precombine.field": "processed_date",
"hoodie.datasource.write.partitionpath.field":
"story_published_partition_date",
"hoodie.datasource.write.keygenerator.class":
"org.apache.hudi.keygen.TimestampBasedKeyGenerator",
"hoodie.deltastreamer.keygen.timebased.timestamp.type": "DATE_STRING",
"hoodie.deltastreamer.keygen.timebased.input.dateformat":
"yyyy-MM-dd'T'HH:mm:ssZ,yyyy-MM-dd'T'HH:mm:ss.SSSZ",
"hoodie.deltastreamer.keygen.timebased.input.dateformat.list.delimiter.regex":
",",
"hoodie.deltastreamer.keygen.timebased.input.timezone": "",
"hoodie.deltastreamer.keygen.timebased.output.dateformat": "yyyy-MM-dd",
"hoodie.deltastreamer.keygen.timebased.output.timezone": "UTC",
"hoodie.datasource.hive_sync.partition_extractor_class":
"org.apache.hudi.hive.MultiPartKeysValueExtractor",
"hoodie.datasource.write.hive_style_partitioning": "true",
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.database": hudi_database_name,
"hoodie.datasource.hive_sync.table": hudi_table_name,
"hoodie.datasource.hive_sync.partition_fields":
"story_published_partition_date",
"hoodie.datasource.hive_sync.jdbcurl":
f"jdbc:hive2://{master_hostname}:10000",
"hoodie.compact.inline": str(hudi_compact_inline),
"hoodie.compact.inline.trigger.strategy": "NUM_OR_TIME",
"hoodie.cleaner.commits.retained": "1",
"hoodie.write.markers.type": "TIMELINE_SERVER_BASED",
"hoodie.datasource.hive_sync.support_timestamp": "true",
"hoodie.metrics.on": "true",
"hoodie.metrics.reporter.type": "PROMETHEUS",
"hoodie.datasource.write.drop.partition.columns": "true",
"hoodie.bloom.index.prune.by.ranges": "false",
"hoodie.combine.before.insert": "true",
"hoodie.upsert.shuffle.parallelism": "10036",
"hoodie.insert.shuffle.parallelism": "10036",
"hoodie.bulkinsert.shuffle.parallelism": "10036",
```
We're setting parallelism based on the [Tuning
Guide](https://cwiki.apache.org/confluence/display/HUDI/Tuning+Guide) which
states to set it such that its atleast input_data_size/500MB.
Script (somewhat truncated):
```python
def clean_data_frame(spark: SparkSession, df: DataFrame) -> DataFrame:
"""
Sanitised field names, removing invalid characters.
"""
# apache avro does not support - in column names
def sanitizeFieldName(s: str) -> str:
return re.sub("[^0-9a-zA-Z_]+", "_", s)
# We call this on all fields to create a copy and to perform any changes
we might
# want to do to the field.
def sanitizeField(field: StructField) -> StructField:
field = copy(field)
field.name = sanitizeFieldName(field.name)
# We recursively call cleanSchema on all types
field.dataType = cleanSchema(field.dataType)
return field
def cleanSchema(dataType: DataType) -> DataType:
dataType = copy(dataType)
# If the type is a StructType we need to recurse otherwise we can
return since
# we've reached the leaf node
if isinstance(dataType, StructType):
# We call our sanitizer for all top level fields
dataType.fields = [sanitizeField(f) for f in dataType.fields]
dataType.names = [f.name for f in dataType.fields]
elif isinstance(dataType, ArrayType):
dataType.elementType = cleanSchema(dataType.elementType)
return dataType
# Now since we have the new schema we can create a new DataFrame by
using the old Frame's RDD as data and the new schema as the schema for the data
return spark.createDataFrame(df.rdd, cleanSchema(df.schema))
def read_parquet(spark: SparkSession, input_data_path: str) -> DataFrame:
return spark.read.parquet(input_data_path)
def read_json(spark: SparkSession, input_data_path: str) -> DataFrame:
return clean_data_frame(
spark,
spark.read.json(path=input_data_path).select(
f.col("_id"),
f.col("_version"),
f.col("_source.*"),
),
)
def map_column(
schema_datatype: DataType, column_datatype: DataType, c: Column
) -> Column:
try:
# converts JSON string columns to their StructType equivalent
if isinstance(column_datatype, StringType) and isinstance(
schema_datatype, StructType
):
return f.from_json(c, schema_datatype)
# for each nested column, set any missing fields to null and drop
any fields not in the target
if isinstance(schema_datatype, StructType):
target_schema_struct_columns = []
for nested_field in schema_datatype.fields:
nested_datatype = nested_field.dataType
if isinstance(nested_datatype, (StructType, ArrayType)):
new_column = map_column(
nested_datatype,
column_datatype[nested_field.name].dataType,
c.getField(nested_field.name),
)
elif nested_field.name in column_datatype.fieldNames():
new_column =
c.getField(nested_field.name).cast(nested_datatype)
else:
new_column = f.lit(None).cast(nested_datatype)
target_schema_struct_columns.append(new_column.alias(nested_field.name))
return f.struct(*target_schema_struct_columns)
# TODO: support recursive conversion of nested columns with
mismatched schema
if isinstance(schema_datatype, ArrayType):
schema_json = schema_datatype.jsonValue()
schema_json["containsNull"] = True
schema_datatype = ArrayType.fromJson(schema_json)
return c.cast(schema_datatype)
except Exception as ex:
logger.exception(
"Failed to cast column: %s with type %s to type %s",
c.name,
column_datatype.json(),
schema_datatype.json(),
)
raise ex
def cast_target_columns_to_schema(input_df: DataFrame, schema: StructType)
-> DataFrame:
"""
Casts all columns in the input_df to the same column type as the column
with a matching name in the target schema.
Drops columns which do not exist in the target schema.
Order is preserved in the target schema - this is necessary as Hudi does
not support re-ordering of columns or dropping existing columns, new columns
must be added at the end.
i.e. "Add a new nullable column and change the ordering of fields" fails
on on all table types
see https://hudi.apache.org/docs/schema_evolution/
"""
input_schema_field_names = input_df.schema.fieldNames()
schema_field_names = schema.fieldNames()
logger.debug("input data field names %s", input_schema_field_names)
logger.debug("schema field names %s", schema_field_names)
columns = []
for field in schema.fields:
if field.name.startswith("_hoodie"):
continue
if field.name not in input_schema_field_names:
logger.info(
"Column %s does not exist in source dataframe, added as
null",
field.name,
)
mapped_column = f.lit(None).cast(field.dataType)
else:
input_df_field_datatype = input_df.schema[field.name].dataType
mapped_column = map_column(
field.dataType, input_df_field_datatype, f.col(field.name)
)
logger.info(
"Column %s existed in source dataframe, casted from schema
%s to schema %s",
field.name,
field.dataType.json(),
input_df_field_datatype.json(),
)
columns.append(mapped_column.alias(field.name))
for field_name in input_schema_field_names:
if field_name not in schema_field_names:
logger.info("Column %s did not exist in target schema, dropped",
field_name)
return input_df.select(*columns)
def set_df_columns_nullable(
spark: SparkSession, df: DataFrame, nullable: bool = True
) -> DataFrame:
"""
Set all dataframe columns as nullable.
This is primarily to match the output of Firehose/Hudi deltastreamer, as
otherwise schema validation fails when writing into a table using Deltastreamer
and syncing schema,
as columns are set to nullable at this point.
"""
def set_nullable(st: StructType) -> StructType:
for struct_field in st.fields:
if isinstance(struct_field.dataType, StructType):
struct_field.dataType = set_nullable(struct_field.dataType)
elif isinstance(struct_field.dataType, ArrayType) and isinstance(
struct_field.dataType.elementType, StructType
):
struct_field.dataType.elementType = set_nullable(
struct_field.dataType.elementType
)
struct_field.nullable = nullable
return st
return spark.createDataFrame(df.rdd, set_nullable(df.schema))
def main():
spark = (
SparkSession.builder.appName("hudi_full_load")
.enableHiveSupport()
.getOrCreate()
)
input_df = (
(
read_parquet(spark, input_data_path)
if source_format == "parquet"
else (read_json(spark, input_data_path))
)
.withColumnRenamed("_id", "id")
# drop the existing version column which existed under
_source.version in some old chunked datalake data
# to avoid naming conflicts
.drop("version")
.withColumnRenamed("_version", "version")
)
input_df.printSchema()
if target_table_schema is not None:
logger.info("Using target table %s", target_table_schema)
existing_table_df = spark.table(target_table_schema)
logger.info(
"Target schema for %s: %s", target_table_schema,
existing_table_df.schema
)
existing_schema = existing_table_df.schema
input_df = cast_target_columns_to_schema(input_df, existing_schema)
input_df.printSchema()
input_df = input_df.withColumn(
"version", f.coalesce(f.col("version"), f.lit(0))
).withColumn("story_published_partition_date",
f.col("story_published_date"))
input_df = set_df_columns_nullable(spark, input_df, nullable=True)
parallelism = spark.conf.get("spark.default.parallelism")
logger.info("spark.default.parallelism: %s", parallelism)
hudi_parallelism_options = {
"hoodie.upsert.shuffle.parallelism": parallelism,
"hoodie.insert.shuffle.parallelism": parallelism,
"hoodie.bulkinsert.shuffle.parallelism": parallelism,
}
partitioned_df = input_df.repartition(int(parallelism)).persist(
StorageLevel.MEMORY_AND_DISK
)
(
partitioned_df.write.format("org.apache.hudi")
.options(**hudi_options)
.options(**hudi_parallelism_options)
.mode(spark_write_mode)
.save(hudi_table_path)
)
if __name__ == "__main__":
main()
```
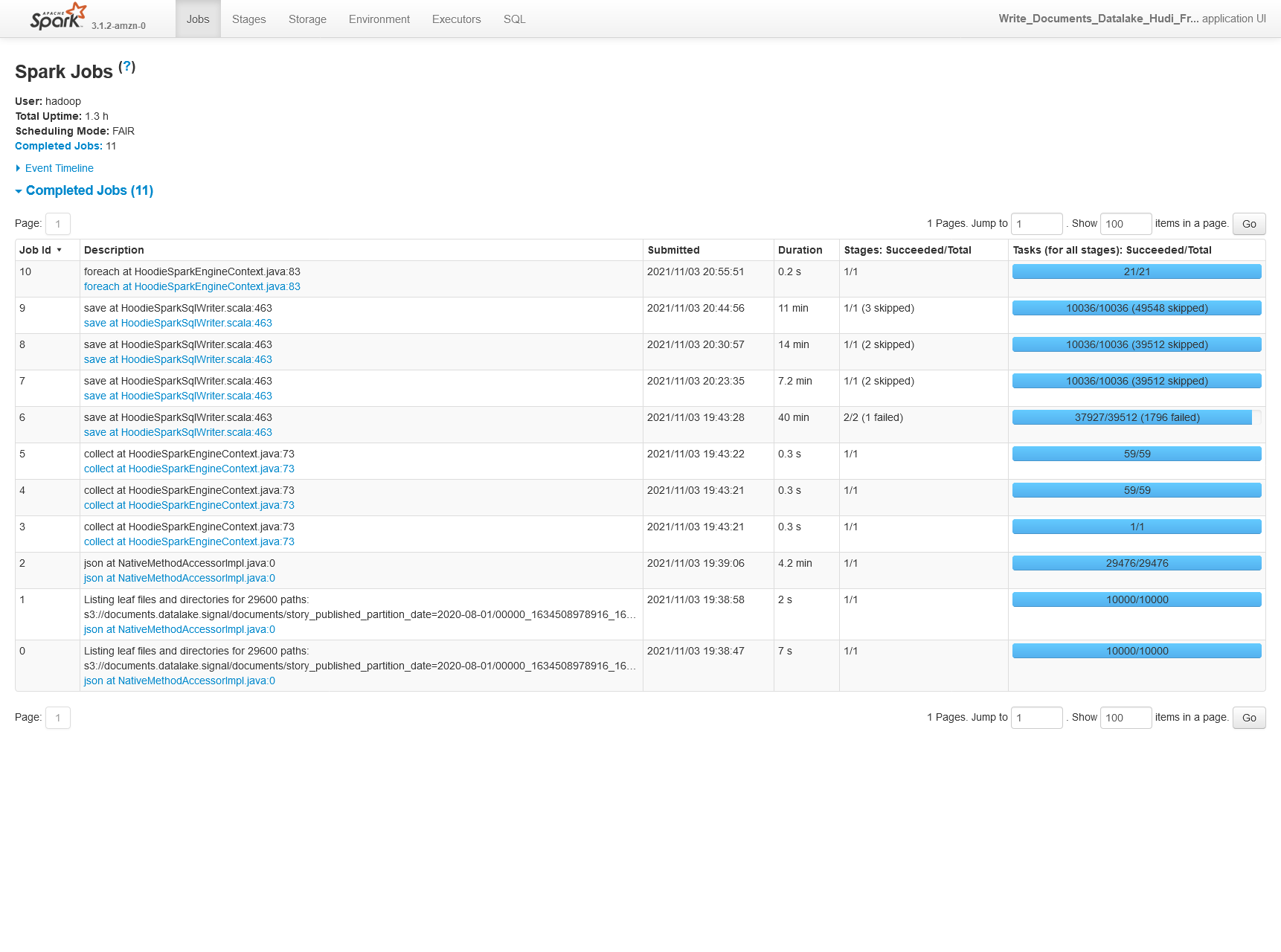
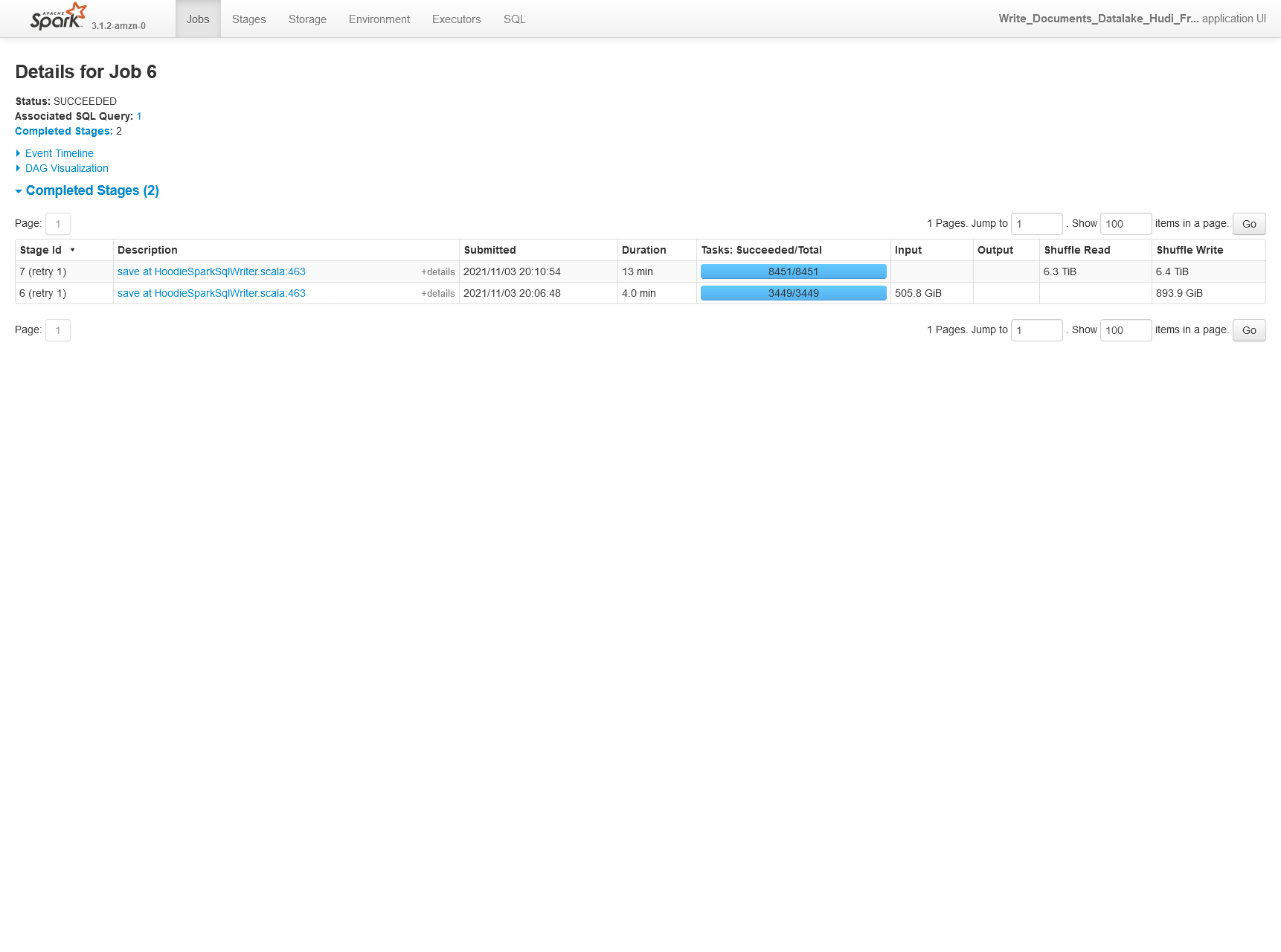
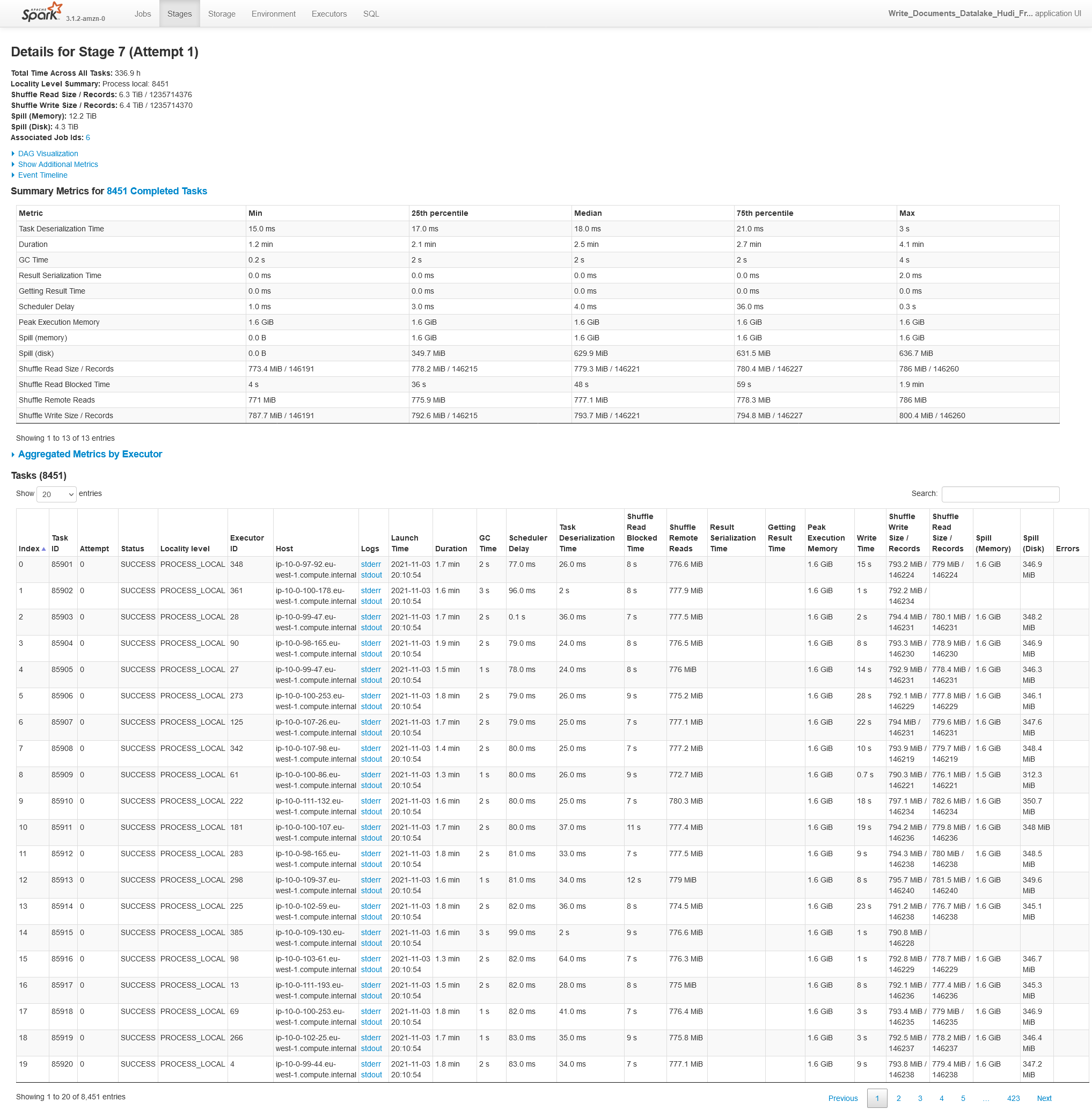
#### Screenshots

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}