mincwang commented on pull request #3703:
URL: https://github.com/apache/hudi/pull/3703#issuecomment-973696652
Hi @garyli1019 ,i meet some error in try spark UT , so I provide an
operation detail below:
- mysql
```sql
create table user(
id int not null primary key,
name varchar(10) null
);
```
- flink job
```sql
CREATE TABLE user_mysql(
id INT ,
name STRING,
PRIMARY KEY(`id`) NOT ENFORCED
)WITH (
'connector' = 'mysql-cdc',
'hostname' = '10.49.0.x',
'port' = '3306',
'username' = 'root',
'password' = '',
'database-name' = 'poc',
'table-name' = 'user'
);
CREATE TABLE `user_hudi`
WITH (
'connector' = 'hudi',
'table.type' = 'MERGE_ON_READ',
'path' = 'hdfs:///hudi/debug/user',
'index.state.ttl'='0',
'index.global.enabled' = 'false',
'write.tasks' = '1',
'changelog.enabled' = 'true',
'hive_sync.enable' = 'true',
'hive_sync.metastore.uris' =
'thrift://10.49.2.x:7004,thrift://10.49.0.40:x',
'hive_sync.mode' = 'hms',
'hive_sync.db' = 'debug',
'hive_sync.auto_create_db' = 'false',
'hive_sync.table'= 'user',
'hive_sync.username' = 'hadoop',
'hive_sync.password' = '',
'hive_sync.partition_extractor_class' =
'org.apache.hudi.hive.MultiPartKeysValueExtractor',
'hoodie.datasource.write.hive_style_partitioning' = 'true',
'compaction.async.enabled' = 'false', ---- highlight
'compaction.trigger.strategy' = 'time_elapsed', ----- highlight
'compaction.delta_seconds' = '120' ---- highlight
) LIKE `user_mysql`(
EXCLUDING ALL
INCLUDING CONSTRAINTS
);
INSERT INTO user_hudi SELECT * FROM user_mysql;
```
now, we should start the flink task.
then i will interval 30 seconds execute once DML for user table of mysql
```sql
-- init insert into
INSERT INTO user VALUES(1,'1');
INSERT INTO user VALUES(2,'2');
-- delete 30 seconds after
DELETE FROM user WHERE id = 1;
-- insert into new value 60 seconds after
INSERT INTO user VALUES(3,'3');
-- update 90 seconds after
UPDATE user SET name='33' where id = 3;
-- insert into new value 120 seconds after
INSERT INTO user VALUES(4,'4');
```
currently for mysql,user table of query results should below:
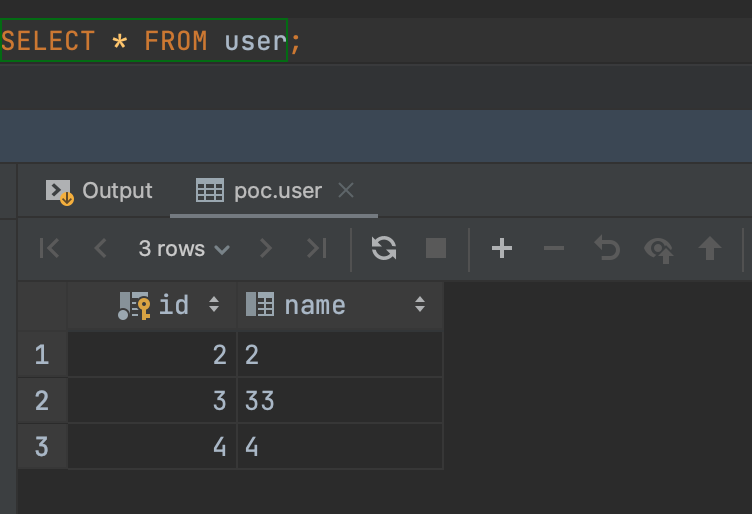
for flink batch query(apply the hudi-2480 patch),results below:
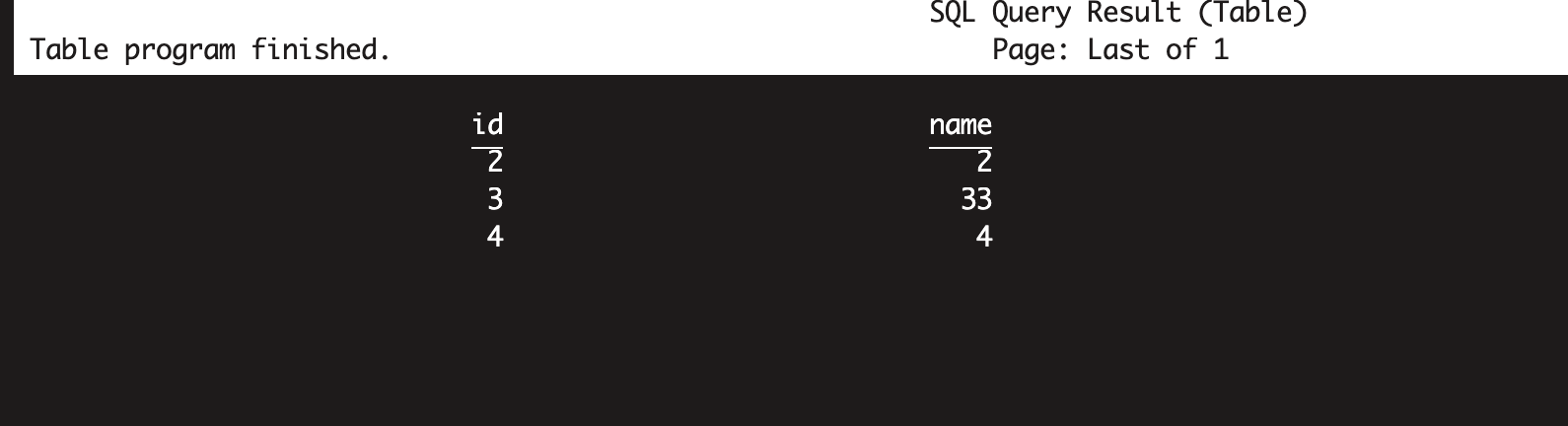
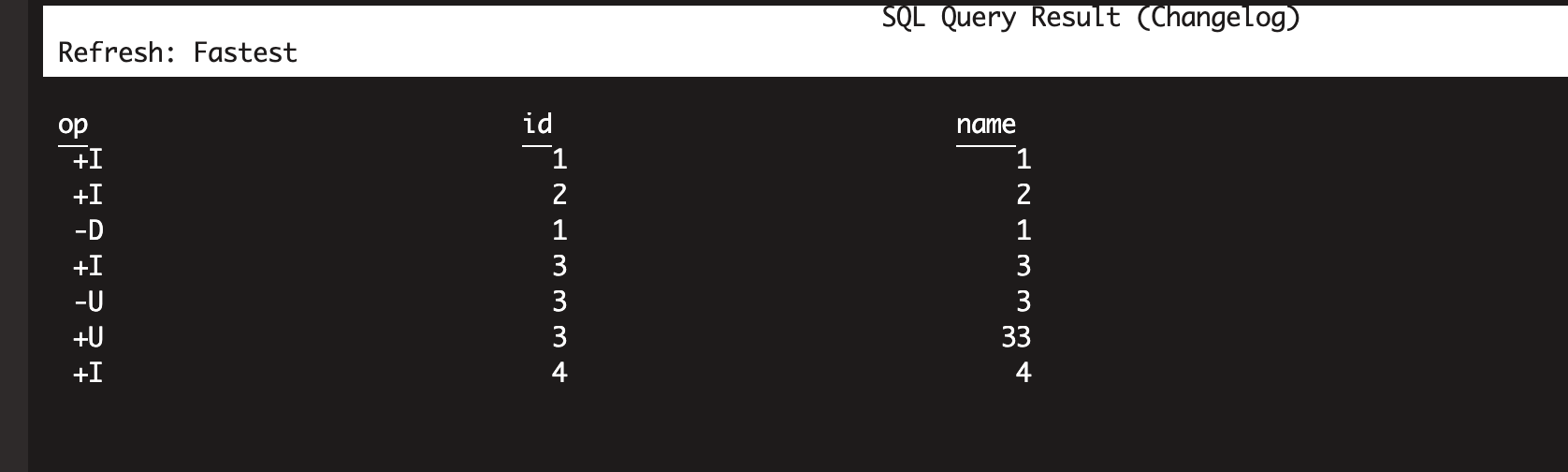
for flink streaming changlog query (apply the hudi-2480 patch),results
below:
for hive batch query,results below:

for spark batch query,results below:

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}