Jiezhi commented on issue #4190: URL: https://github.com/apache/hudi/issues/4190#issuecomment-984504316
> The pipeline is right, there is a bucket assigner there which would try to assign records to small buckets, do you insert continuously and see the file size ? The cleaner may clean the old small files then. I started two task to consume same Kafka topic with different group id, sink to different Hudi table: 1: Flink 1.12.2 with Hudi 0.9 2: Flink 1.13.2 with latest Hudi version(Started at 05:49 PM for test) Two jobs pipeline are same, but the files under partition are different: Job one keep 13 files, and new data are merged into those files, and be merged into two files(because no much data) at second day. Job two just add new files, and there were more than 2000 files under every partition. 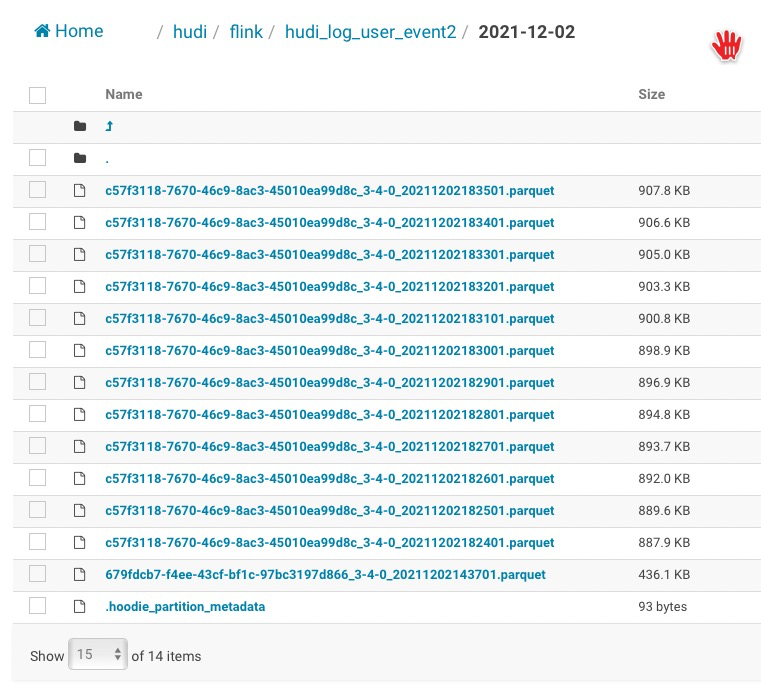 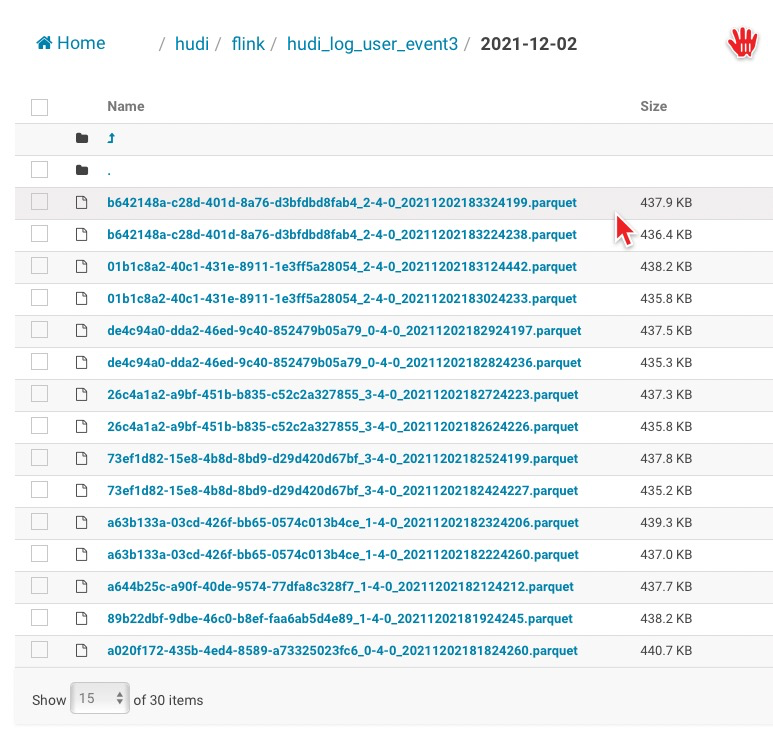 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}