JohnEngelhart opened a new issue #4311: URL: https://github.com/apache/hudi/issues/4311
**Describe the problem you faced** We are incrementally upserting data into our Hudi table/s every 5 minutes. As we begin to read this data we notice that duplicate records occur. The only command we execute is Upsert. We never call bulk insert/insert. The duplicates appear to be happen in two respective areas. 1. In the same upsert command. (The hudi commit time in the table is the same) 2. In different upsert commands. (The hudi commit time is different) The screenshot below shows both use cases above  Options used during Upsert 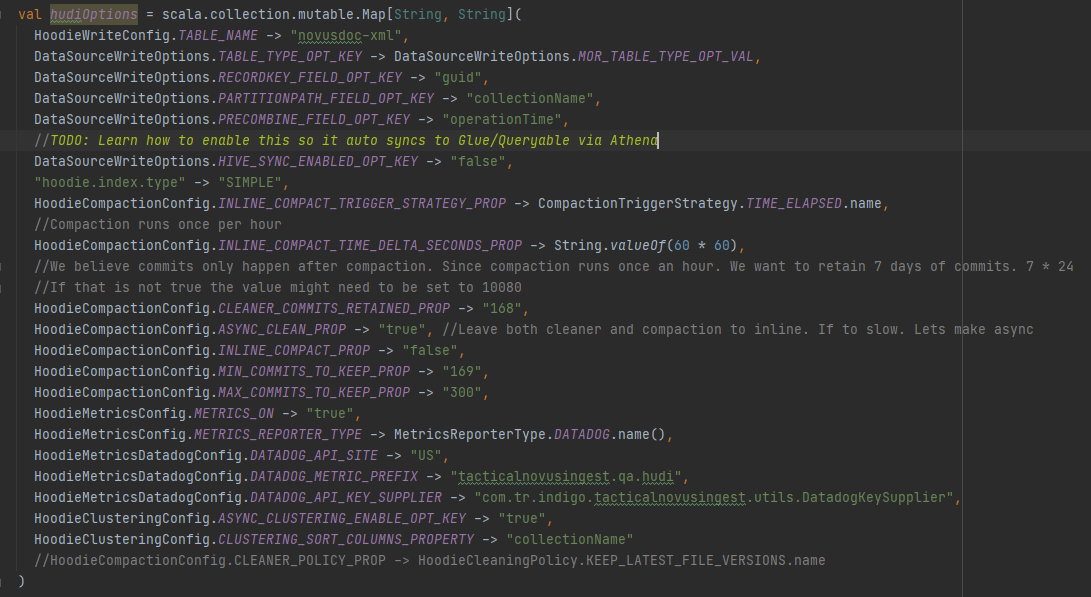 Command Executed During Read. I have tried other different ways to query. Regular Spark code and Spark Sql. 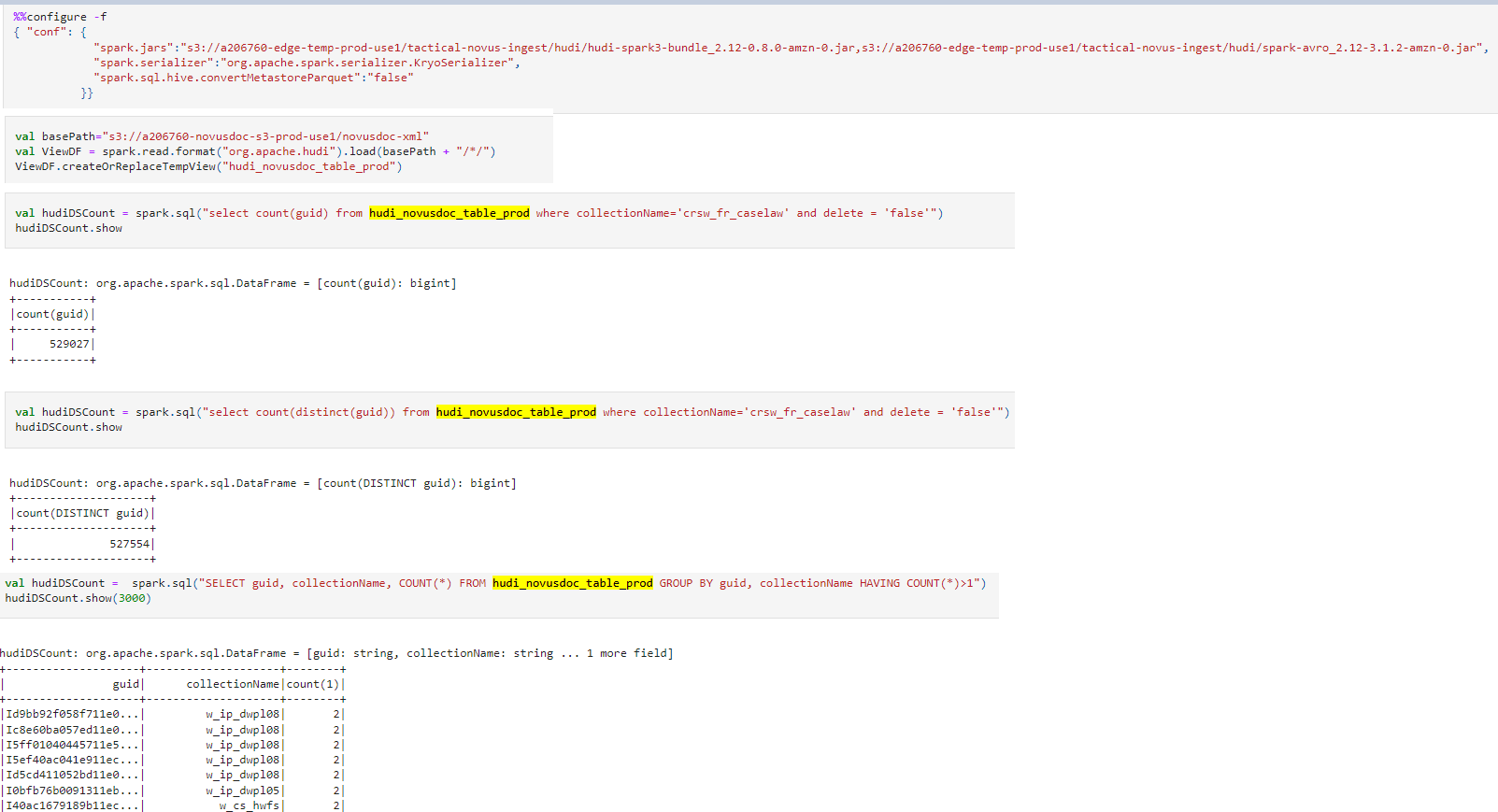 **Expected behavior** When reading data I expect to not have duplicates in my dataframe. **Environment Description** * Hudi version : 0.8.0 * Spark version : 3.1.2-amzn-0 * Hive version : Hive not install on EMR Cluster. But if needed to be installed. Version would be 3.1.2 based on EMR 6.4 * Hadoop version : 3.2.1 * Storage (HDFS/S3/GCS..) : S3 * Running on Docker? (yes/no) : no -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}