This is an automated email from the ASF dual-hosted git repository.
jin pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/incubator-hugegraph-ai.git
The following commit(s) were added to refs/heads/main by this push:
new 560fe03 refactor(llm): use pydantic-settings for config management
(#122)
560fe03 is described below
commit 560fe033e4449583a94f64b5c9e19405545d7720
Author: chenzihong <58508660+chenzihong-ga...@users.noreply.github.com>
AuthorDate: Mon Dec 16 15:47:52 2024 +0800
refactor(llm): use pydantic-settings for config management (#122)
After using lib pydantic-settings, when we use the base model `Config`, the
selected value will be determined in the following order of priority (from
highest to lowest):
1. Parameters are passed in the CLI if cli_parse_args is enabled.
2. Parameters are passed to the Settings class initializer.
3. Environment variables
4. Variables loaded from the dotenv (.env) file.
5. Variables loaded from the secrets directory.(We may make api_key secret
later maybe)
6. Default field values of the Config model.
refer:
https://docs.pydantic.org.cn/latest/concepts/pydantic_settings/#field-value-priority
---------
Co-authored-by: Hongjun Li <returntoinnocenceg...@outlook.com>
Co-authored-by: imbajin <j...@apache.org>
---
hugegraph-llm/README.md | 8 +-
hugegraph-llm/requirements.txt | 1 +
hugegraph-llm/src/hugegraph_llm/api/rag_api.py | 10 +-
hugegraph-llm/src/hugegraph_llm/config/__init__.py | 14 +-
.../config/{__init__.py => admin_config.py} | 19 +-
hugegraph-llm/src/hugegraph_llm/config/generate.py | 6 +-
.../config/{generate.py => hugegraph_config.py} | 25 ++-
.../src/hugegraph_llm/config/llm_config.py | 97 +++++++++
.../hugegraph_llm/config/{ => models}/__init__.py | 15 +-
.../src/hugegraph_llm/config/models/base_config.py | 87 ++++++++
.../{config.py => models/base_prompt_config.py} | 88 +-------
.../config/{config_data.py => prompt_config.py} | 119 +----------
.../src/hugegraph_llm/demo/rag_demo/app.py | 24 ++-
.../hugegraph_llm/demo/rag_demo/configs_block.py | 237 +++++++++++----------
.../src/hugegraph_llm/demo/rag_demo/rag_block.py | 6 +-
.../demo/rag_demo/text2gremlin_block.py | 5 +-
.../src/hugegraph_llm/indices/graph_index.py | 14 +-
.../models/embeddings/init_embedding.py | 22 +-
.../src/hugegraph_llm/models/llms/init_llm.py | 68 +++---
.../models/rerankers/init_reranker.py | 9 +-
.../operators/hugegraph_op/commit_to_hugegraph.py | 14 +-
.../operators/hugegraph_op/fetch_graph_data.py | 2 +-
.../operators/hugegraph_op/graph_rag_query.py | 22 +-
.../operators/hugegraph_op/schema_manager.py | 12 +-
.../operators/index_op/build_semantic_index.py | 4 +-
.../operators/index_op/build_vector_index.py | 4 +-
.../operators/index_op/semantic_id_query.py | 18 +-
.../operators/index_op/vector_index_query.py | 4 +-
.../src/hugegraph_llm/utils/graph_index_utils.py | 6 +-
.../src/hugegraph_llm/utils/hugegraph_utils.py | 14 +-
.../src/hugegraph_llm/utils/vector_index_utils.py | 6 +-
31 files changed, 505 insertions(+), 475 deletions(-)
diff --git a/hugegraph-llm/README.md b/hugegraph-llm/README.md
index aaf9a24..49fe502 100644
--- a/hugegraph-llm/README.md
+++ b/hugegraph-llm/README.md
@@ -17,7 +17,7 @@ graph systems and large language models.
## 2. Environment Requirements
-- python 3.9+ (better to use `3.10`)
+- python 3.9+ (better to use `3.10`)
- hugegraph-server 1.3+
## 3. Preparation
@@ -47,7 +47,7 @@ graph systems and large language models.
```
6. After running the web demo, the config file `.env` will be automatically
generated at the path `hugegraph-llm/.env`. Additionally, a prompt-related
configuration file `config_prompt.yaml` will also be generated at the path
`hugegraph-llm/src/hugegraph_llm/resources/demo/config_prompt.yaml`.
- You can modify the content on the web page, and it will be automatically
saved to the configuration file after the corresponding feature is triggered.
You can also modify the file directly without restarting the web application;
simply refresh the page to load your latest changes.
+ You can modify the content on the web page, and it will be automatically
saved to the configuration file after the corresponding feature is triggered.
You can also modify the file directly without restarting the web application;
refresh the page to load your latest changes.
(Optional)To regenerate the config file, you can use `config.generate`
with `-u` or `--update`.
```bash
python3 -m hugegraph_llm.config.generate --update
@@ -72,13 +72,13 @@ graph systems and large language models.
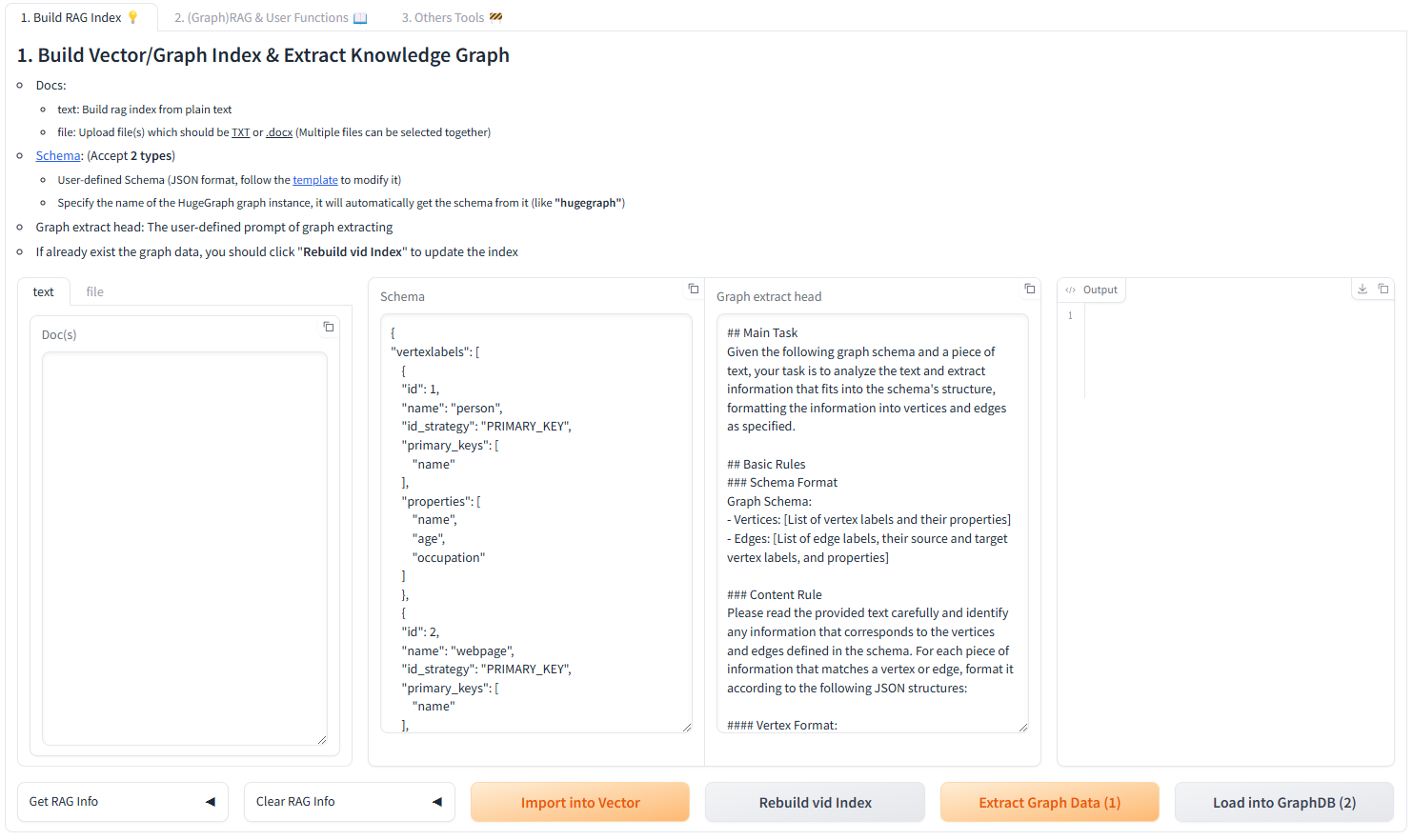
- Docs:
- text: Build rag index from plain text
- file: Upload file(s) which should be <u>TXT</u> or <u>.docx</u> (Multiple
files can be selected together)
-- [Schema](https://hugegraph.apache.org/docs/clients/restful-api/schema/):
(Accept **2 types**)
+- [Schema](https://hugegraph.apache.org/docs/clients/restful-api/schema/):
(Except **2 types**)
- User-defined Schema (JSON format, follow the
[template](https://github.com/apache/incubator-hugegraph-ai/blob/aff3bbe25fa91c3414947a196131be812c20ef11/hugegraph-llm/src/hugegraph_llm/config/config_data.py#L125)
to modify it)
- Specify the name of the HugeGraph graph instance, it will automatically
get the schema from it (like
**"hugegraph"**)
- Graph extract head: The user-defined prompt of graph extracting
-- If already exist the graph data, you should click "**Rebuild vid Index**" to
update the index
+- If it already exists the graph data, you should click "**Rebuild vid
Index**" to update the index
diff --git a/hugegraph-llm/requirements.txt b/hugegraph-llm/requirements.txt
index 755f5be..9cc8c01 100644
--- a/hugegraph-llm/requirements.txt
+++ b/hugegraph-llm/requirements.txt
@@ -14,3 +14,4 @@ python-dotenv>=1.0.1
pyarrow~=17.0.0 # TODO: a temporary dependency for pandas, figure out why
ImportError
pandas~=2.2.2
openpyxl~=3.1.5
+pydantic-settings~=2.6.1
diff --git a/hugegraph-llm/src/hugegraph_llm/api/rag_api.py
b/hugegraph-llm/src/hugegraph_llm/api/rag_api.py
index 0685292..5a4ce0f 100644
--- a/hugegraph-llm/src/hugegraph_llm/api/rag_api.py
+++ b/hugegraph-llm/src/hugegraph_llm/api/rag_api.py
@@ -27,7 +27,7 @@ from hugegraph_llm.api.models.rag_requests import (
RerankerConfigRequest, GraphRAGRequest,
)
from hugegraph_llm.api.models.rag_response import RAGResponse
-from hugegraph_llm.config import settings, prompt
+from hugegraph_llm.config import llm_settings, huge_settings, prompt
from hugegraph_llm.utils.log import log
@@ -40,7 +40,7 @@ def graph_rag_recall(
from hugegraph_llm.operators.graph_rag_task import RAGPipeline
rag = RAGPipeline()
-
rag.extract_keywords().keywords_to_vid().import_schema(settings.graph_name).query_graphdb().merge_dedup_rerank(
+
rag.extract_keywords().keywords_to_vid().import_schema(huge_settings.graph_name).query_graphdb().merge_dedup_rerank(
rerank_method=rerank_method,
near_neighbor_first=near_neighbor_first,
custom_related_information=custom_related_information,
@@ -104,7 +104,7 @@ def rag_http_api(
# TODO: restructure the implement of llm to three types, like
"/config/chat_llm"
@router.post("/config/llm", status_code=status.HTTP_201_CREATED)
def llm_config_api(req: LLMConfigRequest):
- settings.llm_type = req.llm_type
+ llm_settings.llm_type = req.llm_type
if req.llm_type == "openai":
res = apply_llm_conf(req.api_key, req.api_base,
req.language_model, req.max_tokens, origin_call="http")
@@ -116,7 +116,7 @@ def rag_http_api(
@router.post("/config/embedding", status_code=status.HTTP_201_CREATED)
def embedding_config_api(req: LLMConfigRequest):
- settings.embedding_type = req.llm_type
+ llm_settings.embedding_type = req.llm_type
if req.llm_type == "openai":
res = apply_embedding_conf(req.api_key, req.api_base,
req.language_model, origin_call="http")
@@ -128,7 +128,7 @@ def rag_http_api(
@router.post("/config/rerank", status_code=status.HTTP_201_CREATED)
def rerank_config_api(req: RerankerConfigRequest):
- settings.reranker_type = req.reranker_type
+ llm_settings.reranker_type = req.reranker_type
if req.reranker_type == "cohere":
res = apply_reranker_conf(req.api_key, req.reranker_model,
req.cohere_base_url, origin_call="http")
diff --git a/hugegraph-llm/src/hugegraph_llm/config/__init__.py
b/hugegraph-llm/src/hugegraph_llm/config/__init__.py
index 1f39b4c..bdd07e9 100644
--- a/hugegraph-llm/src/hugegraph_llm/config/__init__.py
+++ b/hugegraph-llm/src/hugegraph_llm/config/__init__.py
@@ -16,15 +16,21 @@
# under the License.
-__all__ = ["settings", "prompt", "resource_path"]
+__all__ = ["huge_settings", "admin_settings", "llm_settings", "resource_path"]
import os
-from .config import Config, PromptConfig
-settings = Config()
-settings.from_env()
+from .prompt_config import PromptConfig
+from .hugegraph_config import HugeGraphConfig
+from .admin_config import AdminConfig
+from .llm_config import LLMConfig
+
prompt = PromptConfig()
prompt.ensure_yaml_file_exists()
+huge_settings = HugeGraphConfig()
+admin_settings = AdminConfig()
+llm_settings = LLMConfig()
+
package_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
resource_path = os.path.join(package_path, "resources")
diff --git a/hugegraph-llm/src/hugegraph_llm/config/__init__.py
b/hugegraph-llm/src/hugegraph_llm/config/admin_config.py
similarity index 70%
copy from hugegraph-llm/src/hugegraph_llm/config/__init__.py
copy to hugegraph-llm/src/hugegraph_llm/config/admin_config.py
index 1f39b4c..b2814de 100644
--- a/hugegraph-llm/src/hugegraph_llm/config/__init__.py
+++ b/hugegraph-llm/src/hugegraph_llm/config/admin_config.py
@@ -15,16 +15,11 @@
# specific language governing permissions and limitations
# under the License.
+from typing import Optional
+from .models import BaseConfig
-__all__ = ["settings", "prompt", "resource_path"]
-
-import os
-from .config import Config, PromptConfig
-
-settings = Config()
-settings.from_env()
-prompt = PromptConfig()
-prompt.ensure_yaml_file_exists()
-
-package_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
-resource_path = os.path.join(package_path, "resources")
+class AdminConfig(BaseConfig):
+ """Admin settings"""
+ enable_login: Optional[str] = "False"
+ user_token: Optional[str] = "4321"
+ admin_token: Optional[str] = "xxxx"
diff --git a/hugegraph-llm/src/hugegraph_llm/config/generate.py
b/hugegraph-llm/src/hugegraph_llm/config/generate.py
index 1d85feb..ec7e2c2 100644
--- a/hugegraph-llm/src/hugegraph_llm/config/generate.py
+++ b/hugegraph-llm/src/hugegraph_llm/config/generate.py
@@ -18,12 +18,14 @@
import argparse
-from hugegraph_llm.config import Config, PromptConfig
+from hugegraph_llm.config import huge_settings, admin_settings, llm_settings,
PromptConfig
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Generate hugegraph-llm
config file")
parser.add_argument("-U", "--update", default=True, action="store_true",
help="Update the config file")
args = parser.parse_args()
if args.update:
- Config().generate_env()
+ huge_settings.generate_env()
+ admin_settings.generate_env()
+ llm_settings.generate_env()
PromptConfig().generate_yaml_file()
diff --git a/hugegraph-llm/src/hugegraph_llm/config/generate.py
b/hugegraph-llm/src/hugegraph_llm/config/hugegraph_config.py
similarity index 57%
copy from hugegraph-llm/src/hugegraph_llm/config/generate.py
copy to hugegraph-llm/src/hugegraph_llm/config/hugegraph_config.py
index 1d85feb..cde225a 100644
--- a/hugegraph-llm/src/hugegraph_llm/config/generate.py
+++ b/hugegraph-llm/src/hugegraph_llm/config/hugegraph_config.py
@@ -15,15 +15,20 @@
# specific language governing permissions and limitations
# under the License.
+from typing import Optional
+from .models import BaseConfig
-import argparse
-from hugegraph_llm.config import Config, PromptConfig
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser(description="Generate hugegraph-llm
config file")
- parser.add_argument("-U", "--update", default=True, action="store_true",
help="Update the config file")
- args = parser.parse_args()
- if args.update:
- Config().generate_env()
- PromptConfig().generate_yaml_file()
+class HugeGraphConfig(BaseConfig):
+ """HugeGraph settings"""
+ graph_ip: Optional[str] = "127.0.0.1"
+ graph_port: Optional[str] = "8080"
+ graph_name: Optional[str] = "hugegraph"
+ graph_user: Optional[str] = "admin"
+ graph_pwd: Optional[str] = "xxx"
+ graph_space: Optional[str] = None
+ limit_property: Optional[str] = "False"
+ max_graph_path: Optional[int] = 10
+ max_items: Optional[int] = 30
+ edge_limit_pre_label: Optional[int] = 8
+ vector_dis_threshold: Optional[float] = 0.9
diff --git a/hugegraph-llm/src/hugegraph_llm/config/llm_config.py
b/hugegraph-llm/src/hugegraph_llm/config/llm_config.py
new file mode 100644
index 0000000..45cf4a6
--- /dev/null
+++ b/hugegraph-llm/src/hugegraph_llm/config/llm_config.py
@@ -0,0 +1,97 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+
+import os
+from typing import Optional, Literal
+
+from .models import BaseConfig
+
+
+class LLMConfig(BaseConfig):
+ """LLM settings"""
+
+ chat_llm_type: Literal["openai", "ollama/local", "qianfan_wenxin",
"zhipu"] = "openai"
+ extract_llm_type: Literal["openai", "ollama/local", "qianfan_wenxin",
"zhipu"] = "openai"
+ text2gql_llm_type: Literal["openai", "ollama/local", "qianfan_wenxin",
"zhipu"] = "openai"
+ embedding_type: Optional[Literal["openai", "ollama/local",
"qianfan_wenxin", "zhipu"]] = "openai"
+ reranker_type: Optional[Literal["cohere", "siliconflow"]] = None
+ # 1. OpenAI settings
+ openai_chat_api_base: Optional[str] = os.environ.get("OPENAI_BASE_URL",
"https://api.openai.com/v1";)
+ openai_chat_api_key: Optional[str] = os.environ.get("OPENAI_API_KEY")
+ openai_chat_language_model: Optional[str] = "gpt-4o-mini"
+ openai_extract_api_base: Optional[str] = os.environ.get("OPENAI_BASE_URL",
"https://api.openai.com/v1";)
+ openai_extract_api_key: Optional[str] = os.environ.get("OPENAI_API_KEY")
+ openai_extract_language_model: Optional[str] = "gpt-4o-mini"
+ openai_text2gql_api_base: Optional[str] =
os.environ.get("OPENAI_BASE_URL", "https://api.openai.com/v1";)
+ openai_text2gql_api_key: Optional[str] = os.environ.get("OPENAI_API_KEY")
+ openai_text2gql_language_model: Optional[str] = "gpt-4o-mini"
+ openai_embedding_api_base: Optional[str] =
os.environ.get("OPENAI_EMBEDDING_BASE_URL", "https://api.openai.com/v1";)
+ openai_embedding_api_key: Optional[str] =
os.environ.get("OPENAI_EMBEDDING_API_KEY")
+ openai_embedding_model: Optional[str] = "text-embedding-3-small"
+ openai_chat_tokens: int = 8192
+ openai_extract_tokens: int = 256
+ openai_text2gql_tokens: int = 4096
+ # 2. Rerank settings
+ cohere_base_url: Optional[str] = os.environ.get("CO_API_URL",
"https://api.cohere.com/v1/rerank";)
+ reranker_api_key: Optional[str] = None
+ reranker_model: Optional[str] = None
+ # 3. Ollama settings
+ ollama_chat_host: Optional[str] = "127.0.0.1"
+ ollama_chat_port: Optional[int] = 11434
+ ollama_chat_language_model: Optional[str] = None
+ ollama_extract_host: Optional[str] = "127.0.0.1"
+ ollama_extract_port: Optional[int] = 11434
+ ollama_extract_language_model: Optional[str] = None
+ ollama_text2gql_host: Optional[str] = "127.0.0.1"
+ ollama_text2gql_port: Optional[int] = 11434
+ ollama_text2gql_language_model: Optional[str] = None
+ ollama_embedding_host: Optional[str] = "127.0.0.1"
+ ollama_embedding_port: Optional[int] = 11434
+ ollama_embedding_model: Optional[str] = None
+ # 4. QianFan/WenXin settings
+ qianfan_chat_api_key: Optional[str] = None
+ qianfan_chat_secret_key: Optional[str] = None
+ qianfan_chat_access_token: Optional[str] = None
+ qianfan_extract_api_key: Optional[str] = None
+ qianfan_extract_secret_key: Optional[str] = None
+ qianfan_extract_access_token: Optional[str] = None
+ qianfan_text2gql_api_key: Optional[str] = None
+ qianfan_text2gql_secret_key: Optional[str] = None
+ qianfan_text2gql_access_token: Optional[str] = None
+ qianfan_embedding_api_key: Optional[str] = None
+ qianfan_embedding_secret_key: Optional[str] = None
+ # 4.1 URL settings
+ qianfan_url_prefix: Optional[str] =
"https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop";
+ qianfan_chat_url: Optional[str] = qianfan_url_prefix + "/chat/"
+ qianfan_chat_language_model: Optional[str] = "ERNIE-Speed-128K"
+ qianfan_extract_language_model: Optional[str] = "ERNIE-Speed-128K"
+ qianfan_text2gql_language_model: Optional[str] = "ERNIE-Speed-128K"
+ qianfan_embed_url: Optional[str] = qianfan_url_prefix + "/embeddings/"
+ # refer https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu to get more
details
+ qianfan_embedding_model: Optional[str] = "embedding-v1"
+ # TODO: To be confirmed, whether to configure
+ # 5. ZhiPu(GLM) settings
+ zhipu_chat_api_key: Optional[str] = None
+ zhipu_chat_language_model: Optional[str] = "glm-4"
+ zhipu_chat_embedding_model: Optional[str] = "embedding-2"
+ zhipu_extract_api_key: Optional[str] = None
+ zhipu_extract_language_model: Optional[str] = "glm-4"
+ zhipu_extract_embedding_model: Optional[str] = "embedding-2"
+ zhipu_text2gql_api_key: Optional[str] = None
+ zhipu_text2gql_language_model: Optional[str] = "glm-4"
+ zhipu_text2gql_embedding_model: Optional[str] = "embedding-2"
diff --git a/hugegraph-llm/src/hugegraph_llm/config/__init__.py
b/hugegraph-llm/src/hugegraph_llm/config/models/__init__.py
similarity index 70%
copy from hugegraph-llm/src/hugegraph_llm/config/__init__.py
copy to hugegraph-llm/src/hugegraph_llm/config/models/__init__.py
index 1f39b4c..e73646f 100644
--- a/hugegraph-llm/src/hugegraph_llm/config/__init__.py
+++ b/hugegraph-llm/src/hugegraph_llm/config/models/__init__.py
@@ -15,16 +15,5 @@
# specific language governing permissions and limitations
# under the License.
-
-__all__ = ["settings", "prompt", "resource_path"]
-
-import os
-from .config import Config, PromptConfig
-
-settings = Config()
-settings.from_env()
-prompt = PromptConfig()
-prompt.ensure_yaml_file_exists()
-
-package_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
-resource_path = os.path.join(package_path, "resources")
+from .base_config import BaseConfig
+from .base_prompt_config import BasePromptConfig
diff --git a/hugegraph-llm/src/hugegraph_llm/config/models/base_config.py
b/hugegraph-llm/src/hugegraph_llm/config/models/base_config.py
new file mode 100644
index 0000000..7ad0fda
--- /dev/null
+++ b/hugegraph-llm/src/hugegraph_llm/config/models/base_config.py
@@ -0,0 +1,87 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+
+import os
+
+from dotenv import dotenv_values, set_key
+from pydantic_settings import BaseSettings
+from hugegraph_llm.utils.log import log
+
+dir_name = os.path.dirname
+package_path =
dir_name(dir_name(dir_name(dir_name(dir_name(os.path.abspath(__file__))))))
+env_path = os.path.join(package_path, ".env")
+
+
+class BaseConfig(BaseSettings):
+ class Config:
+ env_file = env_path
+ case_sensitive = False
+ extra = 'ignore' # ignore extra fields to avoid ValidationError
+ env_ignore_empty = True
+
+ def generate_env(self):
+ if os.path.exists(env_path):
+ log.info("%s already exists, do you want to override with the
default configuration? (y/n)", env_path)
+ update = input()
+ if update.lower() != "y":
+ return
+ self.update_env()
+ else:
+ config_dict = self.model_dump()
+ config_dict = {k.upper(): v for k, v in config_dict.items()}
+ with open(env_path, "w", encoding="utf-8") as f:
+ for k, v in config_dict.items():
+ if v is None:
+ f.write(f"{k}=\n")
+ else:
+ f.write(f"{k}={v}\n")
+ log.info("Generate %s successfully!", env_path)
+
+ def update_env(self):
+ config_dict = self.model_dump()
+ config_dict = {k.upper(): v for k, v in config_dict.items()}
+ env_config = dotenv_values(f"{env_path}")
+
+ # dotenv_values make None to '', while pydantic make None to None
+ # dotenv_values make integer to string, while pydantic make integer to
integer
+ for k, v in config_dict.items():
+ if k in env_config:
+ if not (env_config[k] or v):
+ continue
+ if env_config[k] == str(v):
+ continue
+ log.info("Update %s: %s=%s", env_path, k, v)
+ set_key(env_path, k, v if v else "", quote_mode="never")
+
+ def check_env(self):
+ config_dict = self.model_dump()
+ config_dict = {k.upper(): v for k, v in config_dict.items()}
+ env_config = dotenv_values(f"{env_path}")
+ for k, v in config_dict.items():
+ if k in env_config:
+ continue
+ log.info("Update %s: %s=%s", env_path, k, v)
+ set_key(env_path, k, v if v else "", quote_mode="never")
+
+ def __init__(self, **data):
+ super().__init__(**data)
+ if not os.path.exists(env_path):
+ self.generate_env()
+ else:
+ self.check_env()
+ log.info("Loading %s successfully for %s!", env_path,
self.__class__.__name__)
diff --git a/hugegraph-llm/src/hugegraph_llm/config/config.py
b/hugegraph-llm/src/hugegraph_llm/config/models/base_prompt_config.py
similarity index 57%
rename from hugegraph-llm/src/hugegraph_llm/config/config.py
rename to hugegraph-llm/src/hugegraph_llm/config/models/base_prompt_config.py
index aca610f..a03b4df 100644
--- a/hugegraph-llm/src/hugegraph_llm/config/config.py
+++ b/hugegraph-llm/src/hugegraph_llm/config/models/base_prompt_config.py
@@ -15,93 +15,26 @@
# specific language governing permissions and limitations
# under the License.
-
import os
-from dataclasses import dataclass
-from typing import Optional
-
import yaml
-from dotenv import dotenv_values, set_key
-from hugegraph_llm.config.config_data import ConfigData, PromptData
from hugegraph_llm.utils.log import log
dir_name = os.path.dirname
-package_path =
dir_name(dir_name(dir_name(dir_name(os.path.abspath(__file__)))))
-env_path = os.path.join(package_path, ".env")
+package_path =
dir_name(dir_name(dir_name(dir_name(dir_name(os.path.abspath(__file__))))))
F_NAME = "config_prompt.yaml"
yaml_file_path = os.path.join(package_path,
f"src/hugegraph_llm/resources/demo/{F_NAME}")
-def read_dotenv() -> dict[str, Optional[str]]:
- """Read a .env file in the given root path."""
- env_config = dotenv_values(f"{env_path}")
- log.info("Loading %s successfully!", env_path)
- for key, value in env_config.items():
- if key not in os.environ:
- os.environ[key] = value or "" # upper
- return env_config
-
-
-@dataclass
-class Config(ConfigData):
-
- def from_env(self):
- if os.path.exists(env_path):
- env_config = read_dotenv()
- for key, value in env_config.items():
- if key.lower() in self.__annotations__ and value:
- if self.__annotations__[key.lower()] in [int,
Optional[int]]:
- value = int(value)
- setattr(self, key.lower(), value)
- else:
- self.generate_env()
-
- def generate_env(self):
- if os.path.exists(env_path):
- log.info("%s already exists, do you want to override with the
default configuration? (y/n)", env_path)
- update = input()
- if update.lower() != "y":
- return
- self.update_env()
- else:
- config_dict = {}
- for k, v in self.__dict__.items():
- config_dict[k.upper()] = v
- with open(env_path, "w", encoding="utf-8") as f:
- for k, v in config_dict.items():
- if v is None:
- f.write(f"{k}=\n")
- else:
- f.write(f"{k}={v}\n")
- log.info("Generate %s successfully!", env_path)
-
-
- def check_env(self):
- config_dict = {}
- for k, v in self.__dict__.items():
- config_dict[k.upper()] = str(v) if v else ""
- env_config = dotenv_values(f"{env_path}")
- for k, v in config_dict.items():
- if k in env_config:
- continue
- log.info("Update %s: %s=%s", env_path, k, v)
- set_key(env_path, k, v, quote_mode="never")
-
-
- def update_env(self):
- config_dict = {}
- for k, v in self.__dict__.items():
- config_dict[k.upper()] = str(v) if v else ""
- env_config = dotenv_values(f"{env_path}")
- for k, v in config_dict.items():
- if k in env_config and env_config[k] == v:
- continue
- log.info("Update %s: %s=%s", env_path, k, v)
- set_key(env_path, k, v, quote_mode="never")
-
-
-class PromptConfig(PromptData):
+class BasePromptConfig:
+ graph_schema: str = ''
+ extract_graph_prompt: str = ''
+ default_question: str = ''
+ custom_rerank_info: str = ''
+ answer_prompt: str = ''
+ keywords_extract_prompt: str = ''
+ text2gql_graph_schema: str = ''
+ gremlin_generate_prompt: str = ''
def ensure_yaml_file_exists(self):
if os.path.exists(yaml_file_path):
@@ -115,7 +48,6 @@ class PromptConfig(PromptData):
self.generate_yaml_file()
log.info("Prompt file '%s' doesn't exist, create it.",
yaml_file_path)
-
def save_to_yaml(self):
indented_schema = "\n".join([f" {line}" for line in
self.graph_schema.splitlines()])
indented_text2gql_schema = "\n".join([f" {line}" for line in
self.text2gql_graph_schema.splitlines()])
diff --git a/hugegraph-llm/src/hugegraph_llm/config/config_data.py
b/hugegraph-llm/src/hugegraph_llm/config/prompt_config.py
similarity index 58%
rename from hugegraph-llm/src/hugegraph_llm/config/config_data.py
rename to hugegraph-llm/src/hugegraph_llm/config/prompt_config.py
index a3d887e..4d37ced 100644
--- a/hugegraph-llm/src/hugegraph_llm/config/config_data.py
+++ b/hugegraph-llm/src/hugegraph_llm/config/prompt_config.py
@@ -13,113 +13,14 @@
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
-# under the License.\
+# under the License.
-import os
-from dataclasses import dataclass
-from typing import Literal, Optional
+from hugegraph_llm.config.models.base_prompt_config import BasePromptConfig
-
-@dataclass
-class ConfigData:
- """LLM settings"""
-
- # env_path: Optional[str] = ".env"
- chat_llm_type: Literal["openai", "ollama/local", "qianfan_wenxin",
"zhipu"] = "openai"
- extract_llm_type: Literal["openai", "ollama/local", "qianfan_wenxin",
"zhipu"] = "openai"
- text2gql_llm_type: Literal["openai", "ollama/local", "qianfan_wenxin",
"zhipu"] = "openai"
- embedding_type: Optional[Literal["openai", "ollama/local",
"qianfan_wenxin", "zhipu"]] = "openai"
- reranker_type: Optional[Literal["cohere", "siliconflow"]] = None
- # 1. OpenAI settings
- openai_chat_api_base: Optional[str] = os.environ.get("OPENAI_BASE_URL",
"https://api.openai.com/v1";)
- openai_chat_api_key: Optional[str] = os.environ.get("OPENAI_API_KEY")
- openai_chat_language_model: Optional[str] = "gpt-4o-mini"
- openai_extract_api_base: Optional[str] = os.environ.get("OPENAI_BASE_URL",
"https://api.openai.com/v1";)
- openai_extract_api_key: Optional[str] = os.environ.get("OPENAI_API_KEY")
- openai_extract_language_model: Optional[str] = "gpt-4o-mini"
- openai_text2gql_api_base: Optional[str] =
os.environ.get("OPENAI_BASE_URL", "https://api.openai.com/v1";)
- openai_text2gql_api_key: Optional[str] = os.environ.get("OPENAI_API_KEY")
- openai_text2gql_language_model: Optional[str] = "gpt-4o-mini"
- openai_embedding_api_base: Optional[str] =
os.environ.get("OPENAI_EMBEDDING_BASE_URL", "https://api.openai.com/v1";)
- openai_embedding_api_key: Optional[str] =
os.environ.get("OPENAI_EMBEDDING_API_KEY")
- openai_embedding_model: Optional[str] = "text-embedding-3-small"
- openai_chat_tokens: int = 4096
- openai_extract_tokens: int = 4096
- openai_text2gql_tokens: int = 4096
- # 2. Rerank settings
- cohere_base_url: Optional[str] = os.environ.get("CO_API_URL",
"https://api.cohere.com/v1/rerank";)
- reranker_api_key: Optional[str] = None
- reranker_model: Optional[str] = None
- # 3. Ollama settings
- ollama_chat_host: Optional[str] = "127.0.0.1"
- ollama_chat_port: Optional[int] = 11434
- ollama_chat_language_model: Optional[str] = None
- ollama_extract_host: Optional[str] = "127.0.0.1"
- ollama_extract_port: Optional[int] = 11434
- ollama_extract_language_model: Optional[str] = None
- ollama_text2gql_host: Optional[str] = "127.0.0.1"
- ollama_text2gql_port: Optional[int] = 11434
- ollama_text2gql_language_model: Optional[str] = None
- ollama_embedding_host: Optional[str] = "127.0.0.1"
- ollama_embedding_port: Optional[int] = 11434
- ollama_embedding_model: Optional[str] = None
- # 4. QianFan/WenXin settings
- qianfan_chat_api_key: Optional[str] = None
- qianfan_chat_secret_key: Optional[str] = None
- qianfan_chat_access_token: Optional[str] = None
- qianfan_extract_api_key: Optional[str] = None
- qianfan_extract_secret_key: Optional[str] = None
- qianfan_extract_access_token: Optional[str] = None
- qianfan_text2gql_api_key: Optional[str] = None
- qianfan_text2gql_secret_key: Optional[str] = None
- qianfan_text2gql_access_token: Optional[str] = None
- qianfan_embedding_api_key: Optional[str] = None
- qianfan_embedding_secret_key: Optional[str] = None
- # 4.1 URL settings
- qianfan_url_prefix: Optional[str] =
"https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop";
- qianfan_chat_url: Optional[str] = qianfan_url_prefix + "/chat/"
- qianfan_chat_language_model: Optional[str] = "ERNIE-Speed-128K"
- qianfan_extract_language_model: Optional[str] = "ERNIE-Speed-128K"
- qianfan_text2gql_language_model: Optional[str] = "ERNIE-Speed-128K"
- qianfan_embed_url: Optional[str] = qianfan_url_prefix + "/embeddings/"
- # refer https://cloud.baidu.com/doc/WENXINWORKSHOP/s/alj562vvu to get more
details
- qianfan_embedding_model: Optional[str] = "embedding-v1"
- # TODO: To be confirmed, whether to configure
- # 5. ZhiPu(GLM) settings
- zhipu_chat_api_key: Optional[str] = None
- zhipu_chat_language_model: Optional[str] = "glm-4"
- zhipu_chat_embedding_model: Optional[str] = "embedding-2"
- zhipu_extract_api_key: Optional[str] = None
- zhipu_extract_language_model: Optional[str] = "glm-4"
- zhipu_extract_embedding_model: Optional[str] = "embedding-2"
- zhipu_text2gql_api_key: Optional[str] = None
- zhipu_text2gql_language_model: Optional[str] = "glm-4"
- zhipu_text2gql_embedding_model: Optional[str] = "embedding-2"
-
- """HugeGraph settings"""
- graph_ip: Optional[str] = "127.0.0.1"
- graph_port: Optional[str] = "8080"
- graph_name: Optional[str] = "hugegraph"
- graph_user: Optional[str] = "admin"
- graph_pwd: Optional[str] = "xxx"
- graph_space: Optional[str] = None
- limit_property: Optional[str] = "False"
- max_graph_path: Optional[int] = 10
- max_items: Optional[int] = 30
- edge_limit_pre_label: Optional[int] = 8
- vector_dis_threshold: Optional[float] = 0.9
-
- """Admin settings"""
- enable_login: Optional[str] = "False"
- user_token: Optional[str] = "4321"
- admin_token: Optional[str] = "xxxx"
-
-
-# Additional static content like PromptConfig
-class PromptData:
+class PromptConfig(BasePromptConfig):
# Data is detached from llm_op/answer_synthesize.py
- answer_prompt = """You are an expert in knowledge graphs and natural
language processing.
+ answer_prompt: str = """You are an expert in knowledge graphs and natural
language processing.
Your task is to provide a precise and accurate answer based on the given
context.
Context information is below.
@@ -133,12 +34,12 @@ Query: {query_str}
Answer:
"""
- custom_rerank_info = """"""
+ custom_rerank_info: str = """"""
- default_question = """Tell me about Sarah."""
+ default_question: str = """Tell me about Sarah."""
# Data is detached from
hugegraph-llm/src/hugegraph_llm/operators/llm_op/property_graph_extract.py
- extract_graph_prompt = """## Main Task
+ extract_graph_prompt: str = """## Main Task
Given the following graph schema and a piece of text, your task is to analyze
the text and extract information that fits into the schema's structure,
formatting the information into vertices and edges as specified.
## Basic Rules
@@ -174,7 +75,7 @@ Meet Sarah, a 30-year-old attorney, and her roommate, James,
whom she's shared a
[{"id":"1:Sarah","label":"person","type":"vertex","properties":{"name":"Sarah","age":30,"occupation":"attorney"}},{"id":"1:James","label":"person","type":"vertex","properties":{"name":"James","occupation":"journalist"}},{"label":"roommate","type":"edge","outV":"1:Sarah","outVLabel":"person","inV":"1:James","inVLabel":"person","properties":{"date":"2010"}}]
"""
- graph_schema = """{
+ graph_schema: str = """{
"vertexlabels": [
{
"id": 1,
@@ -224,10 +125,10 @@ Meet Sarah, a 30-year-old attorney, and her roommate,
James, whom she's shared a
"""
# TODO: we should provide a better example to reduce the useless
information
- text2gql_graph_schema = ConfigData.graph_name
+ text2gql_graph_schema: str = "hugegraph"
# Extracted from llm_op/keyword_extract.py
- keywords_extract_prompt = """指令:
+ keywords_extract_prompt: str = """指令:
请对以下文本执行以下任务:
1. 从文本中提取关键词:
- 最少 0 个,最多 {max_keywords} 个。
diff --git a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/app.py
b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/app.py
index e08be2e..a247fb2 100644
--- a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/app.py
+++ b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/app.py
@@ -26,7 +26,7 @@ from fastapi.security import HTTPBearer,
HTTPAuthorizationCredentials
from hugegraph_llm.api.admin_api import admin_http_api
from hugegraph_llm.api.rag_api import rag_http_api
-from hugegraph_llm.config import settings, prompt
+from hugegraph_llm.config import huge_settings, prompt
from hugegraph_llm.demo.rag_demo.admin_block import create_admin_block,
log_stream
from hugegraph_llm.demo.rag_demo.configs_block import (
create_configs_block,
@@ -59,11 +59,11 @@ def authenticate(credentials: HTTPAuthorizationCredentials
= Depends(sec)):
# pylint: disable=C0301
def init_rag_ui() -> gr.Interface:
- with gr.Blocks(
+ with (gr.Blocks(
theme="default",
title="HugeGraph RAG Platform",
css=CSS,
- ) as hugegraph_llm_ui:
+ ) as hugegraph_llm_ui):
gr.Markdown("# HugeGraph LLM RAG Demo")
"""
@@ -94,7 +94,8 @@ def init_rag_ui() -> gr.Interface:
with gr.Tab(label="1. Build RAG Index 💡"):
textbox_input_schema, textbox_info_extract_template =
create_vector_graph_block()
with gr.Tab(label="2. (Graph)RAG & User Functions 📖"):
- textbox_inp, textbox_answer_prompt_input,
textbox_keywords_extract_prompt_input = create_rag_block()
+ textbox_inp, textbox_answer_prompt_input,
textbox_keywords_extract_prompt_input, \
+ textbox_custom_related_information = create_rag_block()
with gr.Tab(label="3. Text2gremlin ⚙️"):
textbox_gremlin_inp, textbox_gremlin_schema,
textbox_gremlin_prompt = create_text2gremlin_block()
with gr.Tab(label="4. Graph Tools 🚧"):
@@ -103,13 +104,16 @@ def init_rag_ui() -> gr.Interface:
create_admin_block()
def refresh_ui_config_prompt() -> tuple:
- settings.from_env()
+ # we can use its __init__() for in-place reload
+ # settings.from_env()
+ huge_settings.__init__() # pylint: disable=C2801
prompt.ensure_yaml_file_exists()
return (
- settings.graph_ip, settings.graph_port, settings.graph_name,
settings.graph_user,
- settings.graph_pwd, settings.graph_space, prompt.graph_schema,
prompt.extract_graph_prompt,
+ huge_settings.graph_ip, huge_settings.graph_port,
huge_settings.graph_name, huge_settings.graph_user,
+ huge_settings.graph_pwd, huge_settings.graph_space,
prompt.graph_schema, prompt.extract_graph_prompt,
prompt.default_question, prompt.answer_prompt,
prompt.keywords_extract_prompt,
- prompt.default_question, settings.graph_name,
prompt.gremlin_generate_prompt
+ prompt.custom_rerank_info, prompt.default_question,
huge_settings.graph_name,
+ prompt.gremlin_generate_prompt
)
hugegraph_llm_ui.load(fn=refresh_ui_config_prompt, outputs=[ #
pylint: disable=E1101
@@ -124,6 +128,7 @@ def init_rag_ui() -> gr.Interface:
textbox_inp,
textbox_answer_prompt_input,
textbox_keywords_extract_prompt_input,
+ textbox_custom_related_information,
textbox_gremlin_inp,
textbox_gremlin_schema,
textbox_gremlin_prompt
@@ -139,7 +144,8 @@ if __name__ == "__main__":
args = parser.parse_args()
app = FastAPI()
- settings.check_env()
+ # we don't need to manually check the env now
+ # settings.check_env()
prompt.update_yaml_file()
auth_enabled = os.getenv("ENABLE_LOGIN", "False").lower() == "true"
diff --git a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/configs_block.py
b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/configs_block.py
index 6a65301..b7ace5f 100644
--- a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/configs_block.py
+++ b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/configs_block.py
@@ -17,14 +17,14 @@
import json
import os
-from typing import Optional
from functools import partial
+from typing import Optional
import gradio as gr
import requests
from requests.auth import HTTPBasicAuth
-from hugegraph_llm.config import settings
+from hugegraph_llm.config import huge_settings, llm_settings
from hugegraph_llm.utils.log import log
current_llm = "chat"
@@ -64,10 +64,10 @@ def test_api_connection(url, method="GET", headers=None,
params=None, body=None,
def config_qianfan_model(arg1, arg2, arg3=None, settings_prefix=None,
origin_call=None) -> int:
- setattr(settings, f"qianfan_{settings_prefix}_api_key", arg1)
- setattr(settings, f"qianfan_{settings_prefix}_secret_key", arg2)
+ setattr(llm_settings, f"qianfan_{settings_prefix}_api_key", arg1)
+ setattr(llm_settings, f"qianfan_{settings_prefix}_secret_key", arg2)
if arg3:
- setattr(settings, f"qianfan_{settings_prefix}_language_model", arg3)
+ setattr(llm_settings, f"qianfan_{settings_prefix}_language_model",
arg3)
params = {
"grant_type": "client_credentials",
"client_id": arg1,
@@ -81,40 +81,40 @@ def config_qianfan_model(arg1, arg2, arg3=None,
settings_prefix=None, origin_cal
def apply_embedding_config(arg1, arg2, arg3, origin_call=None) -> int:
status_code = -1
- embedding_option = settings.embedding_type
+ embedding_option = llm_settings.embedding_type
if embedding_option == "openai":
- settings.openai_embedding_api_key = arg1
- settings.openai_embedding_api_base = arg2
- settings.openai_embedding_model = arg3
- test_url = settings.openai_embedding_api_base + "/embeddings"
+ llm_settings.openai_embedding_api_key = arg1
+ llm_settings.openai_embedding_api_base = arg2
+ llm_settings.openai_embedding_model = arg3
+ test_url = llm_settings.openai_embedding_api_base + "/embeddings"
headers = {"Authorization": f"Bearer {arg1}"}
data = {"model": arg3, "input": "test"}
status_code = test_api_connection(test_url, method="POST",
headers=headers, body=data, origin_call=origin_call)
elif embedding_option == "qianfan_wenxin":
status_code = config_qianfan_model(arg1, arg2,
settings_prefix="embedding", origin_call=origin_call)
- settings.qianfan_embedding_model = arg3
+ llm_settings.qianfan_embedding_model = arg3
elif embedding_option == "ollama/local":
- settings.ollama_embedding_host = arg1
- settings.ollama_embedding_port = int(arg2)
- settings.ollama_embedding_model = arg3
+ llm_settings.ollama_embedding_host = arg1
+ llm_settings.ollama_embedding_port = int(arg2)
+ llm_settings.ollama_embedding_model = arg3
status_code = test_api_connection(f"http://{arg1}:{arg2}";,
origin_call=origin_call)
- settings.update_env()
+ llm_settings.update_env()
gr.Info("Configured!")
return status_code
def apply_reranker_config(
- reranker_api_key: Optional[str] = None,
- reranker_model: Optional[str] = None,
- cohere_base_url: Optional[str] = None,
- origin_call=None,
+ reranker_api_key: Optional[str] = None,
+ reranker_model: Optional[str] = None,
+ cohere_base_url: Optional[str] = None,
+ origin_call=None,
) -> int:
status_code = -1
- reranker_option = settings.reranker_type
+ reranker_option = llm_settings.reranker_type
if reranker_option == "cohere":
- settings.reranker_api_key = reranker_api_key
- settings.reranker_model = reranker_model
- settings.cohere_base_url = cohere_base_url
+ llm_settings.reranker_api_key = reranker_api_key
+ llm_settings.reranker_model = reranker_model
+ llm_settings.cohere_base_url = cohere_base_url
headers = {"Authorization": f"Bearer {reranker_api_key}"}
status_code = test_api_connection(
cohere_base_url.rsplit("/", 1)[0] + "/check-api-key",
@@ -123,8 +123,8 @@ def apply_reranker_config(
origin_call=origin_call,
)
elif reranker_option == "siliconflow":
- settings.reranker_api_key = reranker_api_key
- settings.reranker_model = reranker_model
+ llm_settings.reranker_api_key = reranker_api_key
+ llm_settings.reranker_model = reranker_model
from pyhugegraph.utils.constants import Constants
headers = {
@@ -136,18 +136,18 @@ def apply_reranker_config(
headers=headers,
origin_call=origin_call,
)
- settings.update_env()
+ llm_settings.update_env()
gr.Info("Configured!")
return status_code
def apply_graph_config(ip, port, name, user, pwd, gs, origin_call=None) -> int:
- settings.graph_ip = ip
- settings.graph_port = port
- settings.graph_name = name
- settings.graph_user = user
- settings.graph_pwd = pwd
- settings.graph_space = gs
+ huge_settings.graph_ip = ip
+ huge_settings.graph_port = port
+ huge_settings.graph_name = name
+ huge_settings.graph_user = user
+ huge_settings.graph_pwd = pwd
+ huge_settings.graph_space = gs
# Test graph connection (Auth)
if gs and gs.strip():
test_url = f"http://{ip}:{port}/graphspaces/{gs}/graphs/{name}/schema";
@@ -156,25 +156,25 @@ def apply_graph_config(ip, port, name, user, pwd, gs,
origin_call=None) -> int:
auth = HTTPBasicAuth(user, pwd)
# for http api return status
response = test_api_connection(test_url, auth=auth,
origin_call=origin_call)
- settings.update_env()
+ huge_settings.update_env()
return response
# Different llm models have different parameters, so no meaningful argument
names are given here
def apply_llm_config(current_llm_config, arg1, arg2, arg3, arg4,
origin_call=None) -> int:
log.debug("current llm in apply_llm_config is %s", current_llm_config)
- llm_option = getattr(settings, f"{current_llm_config}_llm_type")
+ llm_option = getattr(llm_settings, f"{current_llm_config}_llm_type")
log.debug("llm option in apply_llm_config is %s", llm_option)
status_code = -1
if llm_option == "openai":
- setattr(settings, f"openai_{current_llm_config}_api_key", arg1)
- setattr(settings, f"openai_{current_llm_config}_api_base", arg2)
- setattr(settings, f"openai_{current_llm_config}_language_model", arg3)
- setattr(settings, f"openai_{current_llm_config}_tokens", int(arg4))
+ setattr(llm_settings, f"openai_{current_llm_config}_api_key", arg1)
+ setattr(llm_settings, f"openai_{current_llm_config}_api_base", arg2)
+ setattr(llm_settings, f"openai_{current_llm_config}_language_model",
arg3)
+ setattr(llm_settings, f"openai_{current_llm_config}_tokens", int(arg4))
- test_url = getattr(settings, f"openai_{current_llm_config}_api_base")
+ "/chat/completions"
- log.debug(f"Type of openai {current_llm_config} max token is %s",
type(arg4))
+ test_url = getattr(llm_settings,
f"openai_{current_llm_config}_api_base") + "/chat/completions"
+ log.debug("Type of OpenAI %s max_token is %s", current_llm_config,
type(arg4))
data = {
"model": arg3,
"temperature": 0.0,
@@ -184,172 +184,179 @@ def apply_llm_config(current_llm_config, arg1, arg2,
arg3, arg4, origin_call=Non
status_code = test_api_connection(test_url, method="POST",
headers=headers, body=data, origin_call=origin_call)
elif llm_option == "qianfan_wenxin":
- status_code = config_qianfan_model(arg1, arg2, arg3,
settings_prefix=current_llm_config, origin_call=origin_call) #pylint:
disable=C0301
+ status_code = config_qianfan_model(arg1, arg2, arg3,
settings_prefix=current_llm_config,
+ origin_call=origin_call) # pylint:
disable=C0301
elif llm_option == "ollama/local":
- setattr(settings, f"ollama_{current_llm_config}_host", arg1)
- setattr(settings, f"ollama_{current_llm_config}_port", int(arg2))
- setattr(settings, f"ollama_{current_llm_config}_language_model", arg3)
+ setattr(llm_settings, f"ollama_{current_llm_config}_host", arg1)
+ setattr(llm_settings, f"ollama_{current_llm_config}_port", int(arg2))
+ setattr(llm_settings, f"ollama_{current_llm_config}_language_model",
arg3)
status_code = test_api_connection(f"http://{arg1}:{arg2}";,
origin_call=origin_call)
gr.Info("Configured!")
- settings.update_env()
-
+ llm_settings.update_env()
return status_code
# TODO: refactor the function to reduce the number of statements & separate
the logic
-#pylint: disable=C0301
+# pylint: disable=C0301,E1101
def create_configs_block() -> list:
# pylint: disable=R0915 (too-many-statements)
with gr.Accordion("1. Set up the HugeGraph server.", open=False):
with gr.Row():
graph_config_input = [
- gr.Textbox(value=settings.graph_ip, label="ip"),
- gr.Textbox(value=settings.graph_port, label="port"),
- gr.Textbox(value=settings.graph_name, label="graph"),
- gr.Textbox(value=settings.graph_user, label="user"),
- gr.Textbox(value=settings.graph_pwd, label="pwd",
type="password"),
- gr.Textbox(value=settings.graph_space,
label="graphspace(Optional)"),
+ gr.Textbox(value=huge_settings.graph_ip, label="ip"),
+ gr.Textbox(value=huge_settings.graph_port, label="port"),
+ gr.Textbox(value=huge_settings.graph_name, label="graph"),
+ gr.Textbox(value=huge_settings.graph_user, label="user"),
+ gr.Textbox(value=huge_settings.graph_pwd, label="pwd",
type="password"),
+ gr.Textbox(value=huge_settings.graph_space,
label="graphspace(Optional)"),
]
graph_config_button = gr.Button("Apply Configuration")
graph_config_button.click(apply_graph_config, inputs=graph_config_input)
# pylint: disable=no-member
- #TODO : use OOP to restruact
+ # TODO : use OOP to refactor the following code
with gr.Accordion("2. Set up the LLM.", open=False):
gr.Markdown("> Tips: the openai option also support openai style api
from other providers.")
with gr.Tab(label='chat'):
chat_llm_dropdown = gr.Dropdown(choices=["openai",
"qianfan_wenxin", "ollama/local"],
- value=getattr(settings, "chat_llm_type"),
label="type")
+ value=getattr(llm_settings,
"chat_llm_type"), label="type")
apply_llm_config_with_chat_op = partial(apply_llm_config, "chat")
+
@gr.render(inputs=[chat_llm_dropdown])
def chat_llm_settings(llm_type):
- settings.chat_llm_type = llm_type
- llm_config_input = []
+ llm_settings.chat_llm_type = llm_type
if llm_type == "openai":
llm_config_input = [
- gr.Textbox(value=getattr(settings,
"openai_chat_api_key"), label="api_key", type="password"),
- gr.Textbox(value=getattr(settings,
"openai_chat_api_base"), label="api_base"),
- gr.Textbox(value=getattr(settings,
"openai_chat_language_model"), label="model_name"),
- gr.Textbox(value=getattr(settings,
"openai_chat_tokens"), label="max_token"),
- ]
+ gr.Textbox(value=getattr(llm_settings,
"openai_chat_api_key"), label="api_key",
+ type="password"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_chat_api_base"), label="api_base"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_chat_language_model"), label="model_name"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_chat_tokens"), label="max_token"),
+ ]
elif llm_type == "ollama/local":
llm_config_input = [
- gr.Textbox(value=getattr(settings,
"ollama_chat_host"), label="host"),
- gr.Textbox(value=str(getattr(settings,
"ollama_chat_port")), label="port"),
- gr.Textbox(value=getattr(settings,
"ollama_chat_language_model"), label="model_name"),
+ gr.Textbox(value=getattr(llm_settings,
"ollama_chat_host"), label="host"),
+ gr.Textbox(value=str(getattr(llm_settings,
"ollama_chat_port")), label="port"),
+ gr.Textbox(value=getattr(llm_settings,
"ollama_chat_language_model"), label="model_name"),
gr.Textbox(value="", visible=False),
]
elif llm_type == "qianfan_wenxin":
llm_config_input = [
- gr.Textbox(value=getattr(settings,
"qianfan_chat_api_key"), label="api_key", type="password"),
- gr.Textbox(value=getattr(settings,
"qianfan_chat_secret_key"), label="secret_key", type="password"),
- gr.Textbox(value=getattr(settings,
"qianfan_chat_language_model"), label="model_name"),
+ gr.Textbox(value=getattr(llm_settings,
"qianfan_chat_api_key"), label="api_key",
+ type="password"),
+ gr.Textbox(value=getattr(llm_settings,
"qianfan_chat_secret_key"), label="secret_key",
+ type="password"),
+ gr.Textbox(value=getattr(llm_settings,
"qianfan_chat_language_model"), label="model_name"),
gr.Textbox(value="", visible=False),
]
else:
llm_config_input = [gr.Textbox(value="", visible=False)
for _ in range(4)]
llm_config_button = gr.Button("Apply configuration")
- llm_config_button.click(apply_llm_config_with_chat_op,
inputs=llm_config_input) #pylint: disable=E1101
+ llm_config_button.click(apply_llm_config_with_chat_op,
inputs=llm_config_input)
with gr.Tab(label='mini_tasks'):
extract_llm_dropdown = gr.Dropdown(choices=["openai",
"qianfan_wenxin", "ollama/local"],
- value=getattr(settings, "extract_llm_type"),
label="type")
+ value=getattr(llm_settings,
"extract_llm_type"), label="type")
apply_llm_config_with_extract_op = partial(apply_llm_config,
"extract")
@gr.render(inputs=[extract_llm_dropdown])
def extract_llm_settings(llm_type):
- settings.extract_llm_type = llm_type
- llm_config_input = []
+ llm_settings.extract_llm_type = llm_type
if llm_type == "openai":
llm_config_input = [
- gr.Textbox(value=getattr(settings,
"openai_extract_api_key"), label="api_key", type="password"),
- gr.Textbox(value=getattr(settings,
"openai_extract_api_base"), label="api_base"),
- gr.Textbox(value=getattr(settings,
"openai_extract_language_model"), label="model_name"),
- gr.Textbox(value=getattr(settings,
"openai_extract_tokens"), label="max_token"),
- ]
+ gr.Textbox(value=getattr(llm_settings,
"openai_extract_api_key"), label="api_key",
+ type="password"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_extract_api_base"), label="api_base"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_extract_language_model"), label="model_name"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_extract_tokens"), label="max_token"),
+ ]
elif llm_type == "ollama/local":
llm_config_input = [
- gr.Textbox(value=getattr(settings,
"ollama_extract_host"), label="host"),
- gr.Textbox(value=str(getattr(settings,
"ollama_extract_port")), label="port"),
- gr.Textbox(value=getattr(settings,
"ollama_extract_language_model"), label="model_name"),
+ gr.Textbox(value=getattr(llm_settings,
"ollama_extract_host"), label="host"),
+ gr.Textbox(value=str(getattr(llm_settings,
"ollama_extract_port")), label="port"),
+ gr.Textbox(value=getattr(llm_settings,
"ollama_extract_language_model"), label="model_name"),
gr.Textbox(value="", visible=False),
]
elif llm_type == "qianfan_wenxin":
llm_config_input = [
- gr.Textbox(value=getattr(settings,
"qianfan_extract_api_key"), label="api_key", type="password"),
- gr.Textbox(value=getattr(settings,
"qianfan_extract_secret_key"), label="secret_key", type="password"),
- gr.Textbox(value=getattr(settings,
"qianfan_extract_language_model"), label="model_name"),
+ gr.Textbox(value=getattr(llm_settings,
"qianfan_extract_api_key"), label="api_key",
+ type="password"),
+ gr.Textbox(value=getattr(llm_settings,
"qianfan_extract_secret_key"), label="secret_key",
+ type="password"),
+ gr.Textbox(value=getattr(llm_settings,
"qianfan_extract_language_model"), label="model_name"),
gr.Textbox(value="", visible=False),
]
else:
llm_config_input = [gr.Textbox(value="", visible=False)
for _ in range(4)]
llm_config_button = gr.Button("Apply configuration")
- llm_config_button.click(apply_llm_config_with_extract_op,
inputs=llm_config_input) #pylint: disable=E1101
+ llm_config_button.click(apply_llm_config_with_extract_op,
inputs=llm_config_input)
with gr.Tab(label='text2gql'):
text2gql_llm_dropdown = gr.Dropdown(choices=["openai",
"qianfan_wenxin", "ollama/local"],
- value=getattr(settings, "text2gql_llm_type"),
label="type")
+ value=getattr(llm_settings,
"text2gql_llm_type"), label="type")
apply_llm_config_with_text2gql_op = partial(apply_llm_config,
"text2gql")
@gr.render(inputs=[text2gql_llm_dropdown])
def text2gql_llm_settings(llm_type):
- settings.text2gql_llm_type = llm_type
- llm_config_input = []
+ llm_settings.text2gql_llm_type = llm_type
if llm_type == "openai":
llm_config_input = [
- gr.Textbox(value=getattr(settings,
"openai_text2gql_api_key"), label="api_key", type="password"),
- gr.Textbox(value=getattr(settings,
"openai_text2gql_api_base"), label="api_base"),
- gr.Textbox(value=getattr(settings,
"openai_text2gql_language_model"), label="model_name"),
- gr.Textbox(value=getattr(settings,
"openai_text2gql_tokens"), label="max_token"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_text2gql_api_key"), label="api_key",
+ type="password"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_text2gql_api_base"), label="api_base"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_text2gql_language_model"), label="model_name"),
+ gr.Textbox(value=getattr(llm_settings,
"openai_text2gql_tokens"), label="max_token"),
]
elif llm_type == "ollama/local":
llm_config_input = [
- gr.Textbox(value=getattr(settings,
"ollama_text2gql_host"), label="host"),
- gr.Textbox(value=str(getattr(settings,
"ollama_text2gql_port")), label="port"),
- gr.Textbox(value=getattr(settings,
"ollama_text2gql_language_model"), label="model_name"),
+ gr.Textbox(value=getattr(llm_settings,
"ollama_text2gql_host"), label="host"),
+ gr.Textbox(value=str(getattr(llm_settings,
"ollama_text2gql_port")), label="port"),
+ gr.Textbox(value=getattr(llm_settings,
"ollama_text2gql_language_model"), label="model_name"),
gr.Textbox(value="", visible=False),
]
elif llm_type == "qianfan_wenxin":
llm_config_input = [
- gr.Textbox(value=getattr(settings,
"qianfan_text2gql_api_key"), label="api_key", type="password"),
- gr.Textbox(value=getattr(settings,
"qianfan_text2gql_secret_key"), label="secret_key", type="password"),
- gr.Textbox(value=getattr(settings,
"qianfan_text2gql_language_model"), label="model_name"),
+ gr.Textbox(value=getattr(llm_settings,
"qianfan_text2gql_api_key"), label="api_key",
+ type="password"),
+ gr.Textbox(value=getattr(llm_settings,
"qianfan_text2gql_secret_key"), label="secret_key",
+ type="password"),
+ gr.Textbox(value=getattr(llm_settings,
"qianfan_text2gql_language_model"), label="model_name"),
gr.Textbox(value="", visible=False),
]
else:
llm_config_input = [gr.Textbox(value="", visible=False)
for _ in range(4)]
llm_config_button = gr.Button("Apply configuration")
- llm_config_button.click(apply_llm_config_with_text2gql_op,
inputs=llm_config_input) #pylint: disable=E1101
-
+ llm_config_button.click(apply_llm_config_with_text2gql_op,
inputs=llm_config_input)
with gr.Accordion("3. Set up the Embedding.", open=False):
embedding_dropdown = gr.Dropdown(
- choices=["openai", "qianfan_wenxin", "ollama/local"],
value=settings.embedding_type, label="Embedding"
+ choices=["openai", "qianfan_wenxin", "ollama/local"],
value=llm_settings.embedding_type, label="Embedding"
)
@gr.render(inputs=[embedding_dropdown])
def embedding_settings(embedding_type):
- settings.embedding_type = embedding_type
+ llm_settings.embedding_type = embedding_type
if embedding_type == "openai":
with gr.Row():
embedding_config_input = [
- gr.Textbox(value=settings.openai_embedding_api_key,
label="api_key", type="password"),
- gr.Textbox(value=settings.openai_embedding_api_base,
label="api_base"),
- gr.Textbox(value=settings.openai_embedding_model,
label="model_name"),
+
gr.Textbox(value=llm_settings.openai_embedding_api_key, label="api_key",
type="password"),
+
gr.Textbox(value=llm_settings.openai_embedding_api_base, label="api_base"),
+ gr.Textbox(value=llm_settings.openai_embedding_model,
label="model_name"),
]
elif embedding_type == "ollama/local":
with gr.Row():
embedding_config_input = [
- gr.Textbox(value=settings.ollama_embedding_host,
label="host"),
- gr.Textbox(value=str(settings.ollama_embedding_port),
label="port"),
- gr.Textbox(value=settings.ollama_embedding_model,
label="model_name"),
+ gr.Textbox(value=llm_settings.ollama_embedding_host,
label="host"),
+
gr.Textbox(value=str(llm_settings.ollama_embedding_port), label="port"),
+ gr.Textbox(value=llm_settings.ollama_embedding_model,
label="model_name"),
]
elif embedding_type == "qianfan_wenxin":
with gr.Row():
embedding_config_input = [
- gr.Textbox(value=settings.qianfan_embedding_api_key,
label="api_key", type="password"),
-
gr.Textbox(value=settings.qianfan_embedding_secret_key, label="secret_key",
type="password"),
- gr.Textbox(value=settings.qianfan_embedding_model,
label="model_name"),
+
gr.Textbox(value=llm_settings.qianfan_embedding_api_key, label="api_key",
type="password"),
+
gr.Textbox(value=llm_settings.qianfan_embedding_secret_key, label="secret_key",
+ type="password"),
+ gr.Textbox(value=llm_settings.qianfan_embedding_model,
label="model_name"),
]
else:
embedding_config_input = [
@@ -375,18 +382,18 @@ def create_configs_block() -> list:
@gr.render(inputs=[reranker_dropdown])
def reranker_settings(reranker_type):
- settings.reranker_type = reranker_type if reranker_type != "None"
else None
+ llm_settings.reranker_type = reranker_type if reranker_type !=
"None" else None
if reranker_type == "cohere":
with gr.Row():
reranker_config_input = [
- gr.Textbox(value=settings.reranker_api_key,
label="api_key", type="password"),
- gr.Textbox(value=settings.reranker_model,
label="model"),
- gr.Textbox(value=settings.cohere_base_url,
label="base_url"),
+ gr.Textbox(value=llm_settings.reranker_api_key,
label="api_key", type="password"),
+ gr.Textbox(value=llm_settings.reranker_model,
label="model"),
+ gr.Textbox(value=llm_settings.cohere_base_url,
label="base_url"),
]
elif reranker_type == "siliconflow":
with gr.Row():
reranker_config_input = [
- gr.Textbox(value=settings.reranker_api_key,
label="api_key", type="password"),
+ gr.Textbox(value=llm_settings.reranker_api_key,
label="api_key", type="password"),
gr.Textbox(
value="BAAI/bge-reranker-v2-m3",
label="model",
diff --git a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/rag_block.py
b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/rag_block.py
index fdc554d..4b7449f 100644
--- a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/rag_block.py
+++ b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/rag_block.py
@@ -24,7 +24,7 @@ import gradio as gr
import pandas as pd
from gradio.utils import NamedString
-from hugegraph_llm.config import resource_path, prompt, settings
+from hugegraph_llm.config import resource_path, prompt, huge_settings
from hugegraph_llm.operators.graph_rag_task import RAGPipeline
from hugegraph_llm.utils.log import log
@@ -74,7 +74,7 @@ def rag_answer(
rag.query_vector_index()
if graph_search:
rag.extract_keywords(extract_template=keywords_extract_prompt).keywords_to_vid().import_schema(
-
settings.graph_name).query_graphdb(with_gremlin_template=with_gremlin_template)
+
huge_settings.graph_name).query_graphdb(with_gremlin_template=with_gremlin_template)
# TODO: add more user-defined search strategies
rag.merge_dedup_rerank(graph_ratio, rerank_method, near_neighbor_first, )
rag.synthesize_answer(raw_answer, vector_only_answer, graph_only_answer,
graph_vector_answer, answer_prompt)
@@ -282,4 +282,4 @@ def create_rag_block():
)
questions_file.change(read_file_to_excel, questions_file, [qa_dataframe,
answer_max_line_count])
answer_max_line_count.change(change_showing_excel, answer_max_line_count,
qa_dataframe)
- return inp, answer_prompt_input, keywords_extract_prompt_input
+ return inp, answer_prompt_input, keywords_extract_prompt_input,
custom_related_information
diff --git
a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/text2gremlin_block.py
b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/text2gremlin_block.py
index 797ec73..eaa37bc 100644
--- a/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/text2gremlin_block.py
+++ b/hugegraph-llm/src/hugegraph_llm/demo/rag_demo/text2gremlin_block.py
@@ -17,7 +17,7 @@
import json
import os
-from typing import Any, Tuple, Dict
+from typing import Any, Tuple, Dict, Union
import gradio as gr
import pandas as pd
@@ -60,7 +60,8 @@ def build_example_vector_index(temp_file) -> dict:
return builder.example_index_build(examples).run()
-def gremlin_generate(inp, example_num, schema, gremlin_prompt) -> tuple[str,
str] | tuple[str, Any, Any, Any, Any]:
+def gremlin_generate(inp, example_num, schema, gremlin_prompt) -> Union[
+ tuple[str, str], tuple[str, Any, Any, Any, Any]]:
generator = GremlinGenerator(llm=LLMs().get_text2gql_llm(),
embedding=Embeddings().get_embedding())
sm = SchemaManager(graph_name=schema)
short_schema = False
diff --git a/hugegraph-llm/src/hugegraph_llm/indices/graph_index.py
b/hugegraph-llm/src/hugegraph_llm/indices/graph_index.py
index 996c25c..5b974ba 100644
--- a/hugegraph-llm/src/hugegraph_llm/indices/graph_index.py
+++ b/hugegraph-llm/src/hugegraph_llm/indices/graph_index.py
@@ -19,18 +19,18 @@
from typing import Optional
from pyhugegraph.client import PyHugeClient
-from ..config import settings
+from hugegraph_llm.config import huge_settings
class GraphIndex:
def __init__(
self,
- graph_ip: Optional[str] = settings.graph_ip,
- graph_port: Optional[str] = settings.graph_port,
- graph_name: Optional[str] = settings.graph_name,
- graph_user: Optional[str] = settings.graph_user,
- graph_pwd: Optional[str] = settings.graph_pwd,
- graph_space: Optional[str] = settings.graph_space,
+ graph_ip: Optional[str] = huge_settings.graph_ip,
+ graph_port: Optional[str] = huge_settings.graph_port,
+ graph_name: Optional[str] = huge_settings.graph_name,
+ graph_user: Optional[str] = huge_settings.graph_user,
+ graph_pwd: Optional[str] = huge_settings.graph_pwd,
+ graph_space: Optional[str] = huge_settings.graph_space,
):
self.client = PyHugeClient(graph_ip, graph_port, graph_name,
graph_user, graph_pwd, graph_space)
diff --git
a/hugegraph-llm/src/hugegraph_llm/models/embeddings/init_embedding.py
b/hugegraph-llm/src/hugegraph_llm/models/embeddings/init_embedding.py
index 63ea7ab..48b302b 100644
--- a/hugegraph-llm/src/hugegraph_llm/models/embeddings/init_embedding.py
+++ b/hugegraph-llm/src/hugegraph_llm/models/embeddings/init_embedding.py
@@ -19,31 +19,31 @@
from hugegraph_llm.models.embeddings.openai import OpenAIEmbedding
from hugegraph_llm.models.embeddings.ollama import OllamaEmbedding
from hugegraph_llm.models.embeddings.qianfan import QianFanEmbedding
-from hugegraph_llm.config import settings
+from hugegraph_llm.config import llm_settings
class Embeddings:
def __init__(self):
- self.embedding_type = settings.embedding_type
+ self.embedding_type = llm_settings.embedding_type
def get_embedding(self):
if self.embedding_type == "openai":
return OpenAIEmbedding(
- model_name=settings.openai_embedding_model,
- api_key=settings.openai_embedding_api_key,
- api_base=settings.openai_embedding_api_base
+ model_name=llm_settings.openai_embedding_model,
+ api_key=llm_settings.openai_embedding_api_key,
+ api_base=llm_settings.openai_embedding_api_base
)
if self.embedding_type == "ollama/local":
return OllamaEmbedding(
- model=settings.ollama_embedding_model,
- host=settings.ollama_embedding_host,
- port=settings.ollama_embedding_port
+ model=llm_settings.ollama_embedding_model,
+ host=llm_settings.ollama_embedding_host,
+ port=llm_settings.ollama_embedding_port
)
if self.embedding_type == "qianfan_wenxin":
return QianFanEmbedding(
- model_name=settings.qianfan_embedding_model,
- api_key=settings.qianfan_embedding_api_key,
- secret_key=settings.qianfan_embedding_secret_key
+ model_name=llm_settings.qianfan_embedding_model,
+ api_key=llm_settings.qianfan_embedding_api_key,
+ secret_key=llm_settings.qianfan_embedding_secret_key
)
raise Exception("embedding type is not supported !")
diff --git a/hugegraph-llm/src/hugegraph_llm/models/llms/init_llm.py
b/hugegraph-llm/src/hugegraph_llm/models/llms/init_llm.py
index cb7e73d..c0aeb6c 100644
--- a/hugegraph-llm/src/hugegraph_llm/models/llms/init_llm.py
+++ b/hugegraph-llm/src/hugegraph_llm/models/llms/init_llm.py
@@ -19,78 +19,78 @@
from hugegraph_llm.models.llms.ollama import OllamaClient
from hugegraph_llm.models.llms.openai import OpenAIClient
from hugegraph_llm.models.llms.qianfan import QianfanClient
-from hugegraph_llm.config import settings
+from hugegraph_llm.config import llm_settings
class LLMs:
def __init__(self):
- self.chat_llm_type = settings.chat_llm_type
- self.extract_llm_type = settings.extract_llm_type
- self.text2gql_llm_type = settings.text2gql_llm_type
+ self.chat_llm_type = llm_settings.chat_llm_type
+ self.extract_llm_type = llm_settings.extract_llm_type
+ self.text2gql_llm_type = llm_settings.text2gql_llm_type
def get_chat_llm(self):
if self.chat_llm_type == "qianfan_wenxin":
return QianfanClient(
- model_name=settings.qianfan_chat_language_model,
- api_key=settings.qianfan_chat_api_key,
- secret_key=settings.qianfan_chat_secret_key
+ model_name=llm_settings.qianfan_chat_language_model,
+ api_key=llm_settings.qianfan_chat_api_key,
+ secret_key=llm_settings.qianfan_chat_secret_key
)
if self.chat_llm_type == "openai":
return OpenAIClient(
- api_key=settings.openai_chat_api_key,
- api_base=settings.openai_chat_api_base,
- model_name=settings.openai_chat_language_model,
- max_tokens=settings.openai_chat_tokens,
+ api_key=llm_settings.openai_chat_api_key,
+ api_base=llm_settings.openai_chat_api_base,
+ model_name=llm_settings.openai_chat_language_model,
+ max_tokens=llm_settings.openai_chat_tokens,
)
if self.chat_llm_type == "ollama/local":
return OllamaClient(
- model=settings.ollama_chat_language_model,
- host=settings.ollama_chat_host,
- port=settings.ollama_chat_port,
+ model=llm_settings.ollama_chat_language_model,
+ host=llm_settings.ollama_chat_host,
+ port=llm_settings.ollama_chat_port,
)
raise Exception("chat llm type is not supported !")
def get_extract_llm(self):
if self.extract_llm_type == "qianfan_wenxin":
return QianfanClient(
- model_name=settings.qianfan_extract_language_model,
- api_key=settings.qianfan_extract_api_key,
- secret_key=settings.qianfan_extract_secret_key
+ model_name=llm_settings.qianfan_extract_language_model,
+ api_key=llm_settings.qianfan_extract_api_key,
+ secret_key=llm_settings.qianfan_extract_secret_key
)
if self.extract_llm_type == "openai":
return OpenAIClient(
- api_key=settings.openai_extract_api_key,
- api_base=settings.openai_extract_api_base,
- model_name=settings.openai_extract_language_model,
- max_tokens=settings.openai_extract_tokens,
+ api_key=llm_settings.openai_extract_api_key,
+ api_base=llm_settings.openai_extract_api_base,
+ model_name=llm_settings.openai_extract_language_model,
+ max_tokens=llm_settings.openai_extract_tokens,
)
if self.extract_llm_type == "ollama/local":
return OllamaClient(
- model=settings.ollama_extract_language_model,
- host=settings.ollama_extract_host,
- port=settings.ollama_extract_port,
+ model=llm_settings.ollama_extract_language_model,
+ host=llm_settings.ollama_extract_host,
+ port=llm_settings.ollama_extract_port,
)
raise Exception("extract llm type is not supported !")
def get_text2gql_llm(self):
if self.text2gql_llm_type == "qianfan_wenxin":
return QianfanClient(
- model_name=settings.qianfan_text2gql_language_model,
- api_key=settings.qianfan_text2gql_api_key,
- secret_key=settings.qianfan_text2gql_secret_key
+ model_name=llm_settings.qianfan_text2gql_language_model,
+ api_key=llm_settings.qianfan_text2gql_api_key,
+ secret_key=llm_settings.qianfan_text2gql_secret_key
)
if self.text2gql_llm_type == "openai":
return OpenAIClient(
- api_key=settings.openai_text2gql_api_key,
- api_base=settings.openai_text2gql_api_base,
- model_name=settings.openai_text2gql_language_model,
- max_tokens=settings.openai_text2gql_tokens,
+ api_key=llm_settings.openai_text2gql_api_key,
+ api_base=llm_settings.openai_text2gql_api_base,
+ model_name=llm_settings.openai_text2gql_language_model,
+ max_tokens=llm_settings.openai_text2gql_tokens,
)
if self.text2gql_llm_type == "ollama/local":
return OllamaClient(
- model=settings.ollama_text2gql_language_model,
- host=settings.ollama_text2gql_host,
- port=settings.ollama_text2gql_port,
+ model=llm_settings.ollama_text2gql_language_model,
+ host=llm_settings.ollama_text2gql_host,
+ port=llm_settings.ollama_text2gql_port,
)
raise Exception("text2gql llm type is not supported !")
diff --git a/hugegraph-llm/src/hugegraph_llm/models/rerankers/init_reranker.py
b/hugegraph-llm/src/hugegraph_llm/models/rerankers/init_reranker.py
index f80cd27..b1d6ef5 100644
--- a/hugegraph-llm/src/hugegraph_llm/models/rerankers/init_reranker.py
+++ b/hugegraph-llm/src/hugegraph_llm/models/rerankers/init_reranker.py
@@ -15,20 +15,21 @@
# specific language governing permissions and limitations
# under the License.
-from hugegraph_llm.config import settings
+from hugegraph_llm.config import huge_settings
from hugegraph_llm.models.rerankers.cohere import CohereReranker
from hugegraph_llm.models.rerankers.siliconflow import SiliconReranker
class Rerankers:
def __init__(self):
- self.reranker_type = settings.reranker_type
+ self.reranker_type = huge_settings.reranker_type
def get_reranker(self):
if self.reranker_type == "cohere":
return CohereReranker(
- api_key=settings.reranker_api_key,
base_url=settings.cohere_base_url, model=settings.reranker_model
+ api_key=huge_settings.reranker_api_key,
base_url=huge_settings.cohere_base_url,
+ model=huge_settings.reranker_model
)
if self.reranker_type == "siliconflow":
- return SiliconReranker(api_key=settings.reranker_api_key,
model=settings.reranker_model)
+ return SiliconReranker(api_key=huge_settings.reranker_api_key,
model=huge_settings.reranker_model)
raise Exception("Reranker type is not supported!")
diff --git
a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/commit_to_hugegraph.py
b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/commit_to_hugegraph.py
index 39798f6..ae879e9 100644
---
a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/commit_to_hugegraph.py
+++
b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/commit_to_hugegraph.py
@@ -17,7 +17,7 @@
from typing import Dict, Any
-from hugegraph_llm.config import settings
+from hugegraph_llm.config import huge_settings
from hugegraph_llm.enums.property_cardinality import PropertyCardinality
from hugegraph_llm.enums.property_data_type import PropertyDataType,
default_value_map
from hugegraph_llm.utils.log import log
@@ -28,12 +28,12 @@ from pyhugegraph.utils.exceptions import NotFoundError,
CreateError
class Commit2Graph:
def __init__(self):
self.client = PyHugeClient(
- settings.graph_ip,
- settings.graph_port,
- settings.graph_name,
- settings.graph_user,
- settings.graph_pwd,
- settings.graph_space,
+ huge_settings.graph_ip,
+ huge_settings.graph_port,
+ huge_settings.graph_name,
+ huge_settings.graph_user,
+ huge_settings.graph_pwd,
+ huge_settings.graph_space,
)
self.schema = self.client.schema()
diff --git
a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/fetch_graph_data.py
b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/fetch_graph_data.py
index 9cb5729..1428a3a 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/fetch_graph_data.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/fetch_graph_data.py
@@ -29,5 +29,5 @@ class FetchGraphData:
if context is None:
context = {}
if "vertices" not in context:
- context["vertices"] =
self.graph.gremlin().exec("g.V().id()")["data"]
+ context["vertices"] =
self.graph.gremlin().exec("g.V().id().limit(10000)")["data"]
return context
diff --git
a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/graph_rag_query.py
b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/graph_rag_query.py
index 2f5291a..33190b7 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/graph_rag_query.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/graph_rag_query.py
@@ -18,7 +18,7 @@
import json
from typing import Any, Dict, Optional, List, Set, Tuple
-from hugegraph_llm.config import settings
+from hugegraph_llm.config import huge_settings
from hugegraph_llm.models.embeddings.base import BaseEmbedding
from hugegraph_llm.models.llms.base import BaseLLM
from hugegraph_llm.operators.gremlin_generate_task import GremlinGenerator
@@ -78,7 +78,7 @@ class GraphRAGQuery:
def __init__(
self,
max_deep: int = 2,
- max_items: int = int(settings.max_items),
+ max_items: int = int(huge_settings.max_items),
prop_to_match: Optional[str] = None,
llm: Optional[BaseLLM] = None,
embedding: Optional[BaseEmbedding] = None,
@@ -88,18 +88,18 @@ class GraphRAGQuery:
num_gremlin_generate_example: int = 1
):
self._client = PyHugeClient(
- settings.graph_ip,
- settings.graph_port,
- settings.graph_name,
- settings.graph_user,
- settings.graph_pwd,
- settings.graph_space,
+ huge_settings.graph_ip,
+ huge_settings.graph_port,
+ huge_settings.graph_name,
+ huge_settings.graph_user,
+ huge_settings.graph_pwd,
+ huge_settings.graph_space,
)
self._max_deep = max_deep
self._max_items = max_items
self._prop_to_match = prop_to_match
self._schema = ""
- self._limit_property = settings.limit_property.lower() == "true"
+ self._limit_property = huge_settings.limit_property.lower() == "true"
self._max_v_prop_len = max_v_prop_len
self._max_e_prop_len = max_e_prop_len
self._gremlin_generator = GremlinGenerator(
@@ -176,7 +176,7 @@ class GraphRAGQuery:
_, edge_labels = self._extract_labels_from_schema()
edge_labels_str = ",".join("'" + label + "'" for label in edge_labels)
# TODO: enhance the limit logic later
- edge_limit_amount = len(edge_labels) * settings.edge_limit_pre_label
+ edge_limit_amount = len(edge_labels) *
huge_settings.edge_limit_pre_label
use_id_to_match = self._prop_to_match is None
if use_id_to_match:
@@ -192,7 +192,7 @@ class GraphRAGQuery:
# TODO: use generator or asyncio to speed up the query logic
for matched_vid in matched_vids:
gremlin_query = VID_QUERY_NEIGHBOR_TPL.format(
- keywords="'{}'".format(matched_vid),
+ keywords=f"'{matched_vid}'",
max_deep=self._max_deep,
edge_labels=edge_labels_str,
edge_limit=edge_limit_amount,
diff --git
a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/schema_manager.py
b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/schema_manager.py
index 0e706cc..7bd400f 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/schema_manager.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/hugegraph_op/schema_manager.py
@@ -16,7 +16,7 @@
# under the License.
from typing import Dict, Any, Optional
-from hugegraph_llm.config import settings
+from hugegraph_llm.config import huge_settings
from pyhugegraph.client import PyHugeClient
@@ -24,12 +24,12 @@ class SchemaManager:
def __init__(self, graph_name: str):
self.graph_name = graph_name
self.client = PyHugeClient(
- settings.graph_ip,
- settings.graph_port,
+ huge_settings.graph_ip,
+ huge_settings.graph_port,
self.graph_name,
- settings.graph_user,
- settings.graph_pwd,
- settings.graph_space,
+ huge_settings.graph_user,
+ huge_settings.graph_pwd,
+ huge_settings.graph_space,
)
self.schema = self.client.schema()
diff --git
a/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_semantic_index.py
b/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_semantic_index.py
index 4c19cd6..a69be81 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_semantic_index.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_semantic_index.py
@@ -20,7 +20,7 @@ import os
from typing import Any, Dict
from tqdm import tqdm
-from hugegraph_llm.config import resource_path, settings
+from hugegraph_llm.config import resource_path, huge_settings
from hugegraph_llm.models.embeddings.base import BaseEmbedding
from hugegraph_llm.indices.vector_index import VectorIndex
from hugegraph_llm.utils.log import log
@@ -28,7 +28,7 @@ from hugegraph_llm.utils.log import log
class BuildSemanticIndex:
def __init__(self, embedding: BaseEmbedding):
- self.index_dir = str(os.path.join(resource_path, settings.graph_name,
"graph_vids"))
+ self.index_dir = str(os.path.join(resource_path,
huge_settings.graph_name, "graph_vids"))
self.vid_index = VectorIndex.from_index_file(self.index_dir)
self.embedding = embedding
diff --git
a/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_vector_index.py
b/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_vector_index.py
index f11969e..ef87379 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_vector_index.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/index_op/build_vector_index.py
@@ -20,7 +20,7 @@ import os
from typing import Dict, Any
from tqdm import tqdm
-from hugegraph_llm.config import settings, resource_path
+from hugegraph_llm.config import huge_settings, resource_path
from hugegraph_llm.indices.vector_index import VectorIndex
from hugegraph_llm.models.embeddings.base import BaseEmbedding
from hugegraph_llm.utils.log import log
@@ -29,7 +29,7 @@ from hugegraph_llm.utils.log import log
class BuildVectorIndex:
def __init__(self, embedding: BaseEmbedding):
self.embedding = embedding
- self.index_dir = str(os.path.join(resource_path, settings.graph_name,
"chunks"))
+ self.index_dir = str(os.path.join(resource_path,
huge_settings.graph_name, "chunks"))
self.vector_index = VectorIndex.from_index_file(self.index_dir)
def run(self, context: Dict[str, Any]) -> Dict[str, Any]:
diff --git
a/hugegraph-llm/src/hugegraph_llm/operators/index_op/semantic_id_query.py
b/hugegraph-llm/src/hugegraph_llm/operators/index_op/semantic_id_query.py
index 51a6769..47e80f0 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/index_op/semantic_id_query.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/index_op/semantic_id_query.py
@@ -19,7 +19,7 @@
import os
from typing import Dict, Any, Literal, List, Tuple
-from hugegraph_llm.config import resource_path, settings
+from hugegraph_llm.config import resource_path, huge_settings
from hugegraph_llm.indices.vector_index import VectorIndex
from hugegraph_llm.models.embeddings.base import BaseEmbedding
from hugegraph_llm.utils.log import log
@@ -36,19 +36,19 @@ class SemanticIdQuery:
topk_per_query: int = 10,
topk_per_keyword: int = 1
):
- self.index_dir = str(os.path.join(resource_path, settings.graph_name,
"graph_vids"))
+ self.index_dir = str(os.path.join(resource_path,
huge_settings.graph_name, "graph_vids"))
self.vector_index = VectorIndex.from_index_file(self.index_dir)
self.embedding = embedding
self.by = by
self.topk_per_query = topk_per_query
self.topk_per_keyword = topk_per_keyword
self._client = PyHugeClient(
- settings.graph_ip,
- settings.graph_port,
- settings.graph_name,
- settings.graph_user,
- settings.graph_pwd,
- settings.graph_space,
+ huge_settings.graph_ip,
+ huge_settings.graph_port,
+ huge_settings.graph_name,
+ huge_settings.graph_user,
+ huge_settings.graph_pwd,
+ huge_settings.graph_space,
)
def _exact_match_vids(self, keywords: List[str]) -> Tuple[List[str],
List[str]]:
@@ -76,7 +76,7 @@ class SemanticIdQuery:
for keyword in keywords:
keyword_vector = self.embedding.get_text_embedding(keyword)
results = self.vector_index.search(keyword_vector,
top_k=self.topk_per_keyword,
-
dis_threshold=float(settings.vector_dis_threshold))
+
dis_threshold=float(huge_settings.vector_dis_threshold))
if results:
fuzzy_match_result.extend(results[:self.topk_per_keyword])
return fuzzy_match_result
diff --git
a/hugegraph-llm/src/hugegraph_llm/operators/index_op/vector_index_query.py
b/hugegraph-llm/src/hugegraph_llm/operators/index_op/vector_index_query.py
index fbdf0ad..976155c 100644
--- a/hugegraph-llm/src/hugegraph_llm/operators/index_op/vector_index_query.py
+++ b/hugegraph-llm/src/hugegraph_llm/operators/index_op/vector_index_query.py
@@ -19,7 +19,7 @@
import os
from typing import Dict, Any
-from hugegraph_llm.config import resource_path, settings
+from hugegraph_llm.config import resource_path, huge_settings
from hugegraph_llm.indices.vector_index import VectorIndex
from hugegraph_llm.models.embeddings.base import BaseEmbedding
from hugegraph_llm.utils.log import log
@@ -29,7 +29,7 @@ class VectorIndexQuery:
def __init__(self, embedding: BaseEmbedding, topk: int = 3):
self.embedding = embedding
self.topk = topk
- self.index_dir = str(os.path.join(resource_path, settings.graph_name,
"chunks"))
+ self.index_dir = str(os.path.join(resource_path,
huge_settings.graph_name, "chunks"))
self.vector_index = VectorIndex.from_index_file(self.index_dir)
def run(self, context: Dict[str, Any]) -> Dict[str, Any]:
diff --git a/hugegraph-llm/src/hugegraph_llm/utils/graph_index_utils.py
b/hugegraph-llm/src/hugegraph_llm/utils/graph_index_utils.py
index 28b867d..3aa8699 100644
--- a/hugegraph-llm/src/hugegraph_llm/utils/graph_index_utils.py
+++ b/hugegraph-llm/src/hugegraph_llm/utils/graph_index_utils.py
@@ -26,7 +26,7 @@ import gradio as gr
from .hugegraph_utils import get_hg_client, clean_hg_data
from .log import log
from .vector_index_utils import read_documents
-from ..config import resource_path, settings
+from ..config import resource_path, huge_settings
from ..indices.vector_index import VectorIndex
from ..models.embeddings.init_embedding import Embeddings
from ..models.llms.init_llm import LLMs
@@ -36,7 +36,7 @@ from ..operators.kg_construction_task import KgBuilder
def get_graph_index_info():
builder = KgBuilder(LLMs().get_chat_llm(), Embeddings().get_embedding(),
get_hg_client())
context = builder.fetch_graph_data().run()
- vector_index = VectorIndex.from_index_file(str(os.path.join(resource_path,
settings.graph_name, "graph_vids")))
+ vector_index = VectorIndex.from_index_file(str(os.path.join(resource_path,
huge_settings.graph_name, "graph_vids")))
context["vid_index"] = {
"embed_dim": vector_index.index.d,
"num_vectors": vector_index.index.ntotal,
@@ -47,7 +47,7 @@ def get_graph_index_info():
def clean_all_graph_index():
clean_hg_data()
- VectorIndex.clean(str(os.path.join(resource_path, settings.graph_name,
"graph_vids")))
+ VectorIndex.clean(str(os.path.join(resource_path,
huge_settings.graph_name, "graph_vids")))
gr.Info("Clean graph index successfully!")
diff --git a/hugegraph-llm/src/hugegraph_llm/utils/hugegraph_utils.py
b/hugegraph-llm/src/hugegraph_llm/utils/hugegraph_utils.py
index f63f806..7dc69cc 100644
--- a/hugegraph-llm/src/hugegraph_llm/utils/hugegraph_utils.py
+++ b/hugegraph-llm/src/hugegraph_llm/utils/hugegraph_utils.py
@@ -16,7 +16,7 @@
# under the License.
import json
-from hugegraph_llm.config import settings
+from hugegraph_llm.config import huge_settings
from pyhugegraph.client import PyHugeClient
@@ -27,12 +27,12 @@ def run_gremlin_query(query, fmt=True):
def get_hg_client():
return PyHugeClient(
- settings.graph_ip,
- settings.graph_port,
- settings.graph_name,
- settings.graph_user,
- settings.graph_pwd,
- settings.graph_space,
+ huge_settings.graph_ip,
+ huge_settings.graph_port,
+ huge_settings.graph_name,
+ huge_settings.graph_user,
+ huge_settings.graph_pwd,
+ huge_settings.graph_space,
)
diff --git a/hugegraph-llm/src/hugegraph_llm/utils/vector_index_utils.py
b/hugegraph-llm/src/hugegraph_llm/utils/vector_index_utils.py
index e955aac..0911549 100644
--- a/hugegraph-llm/src/hugegraph_llm/utils/vector_index_utils.py
+++ b/hugegraph-llm/src/hugegraph_llm/utils/vector_index_utils.py
@@ -20,7 +20,7 @@ import os
import docx
import gradio as gr
-from hugegraph_llm.config import resource_path, settings
+from hugegraph_llm.config import resource_path, huge_settings
from hugegraph_llm.indices.vector_index import VectorIndex
from hugegraph_llm.models.embeddings.init_embedding import Embeddings
from hugegraph_llm.models.llms.init_llm import LLMs
@@ -56,7 +56,7 @@ def read_documents(input_file, input_text):
def get_vector_index_info():
- vector_index = VectorIndex.from_index_file(str(os.path.join(resource_path,
settings.graph_name, "chunks")))
+ vector_index = VectorIndex.from_index_file(str(os.path.join(resource_path,
huge_settings.graph_name, "chunks")))
return json.dumps({
"embed_dim": vector_index.index.d,
"num_vectors": vector_index.index.ntotal,
@@ -65,7 +65,7 @@ def get_vector_index_info():
def clean_vector_index():
- VectorIndex.clean(str(os.path.join(resource_path, settings.graph_name,
"chunks")))
+ VectorIndex.clean(str(os.path.join(resource_path,
huge_settings.graph_name, "chunks")))
gr.Info("Clean vector index successfully!")
{kind=link}