This is an automated email from the ASF dual-hosted git repository.
fokko pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/iceberg.git
The following commit(s) were added to refs/heads/main by this push:
new 33838d5a48 docs: Add links checker (#9965)
33838d5a48 is described below
commit 33838d5a4870e654829e551a1a2770ff82ac94ab
Author: Fokko Driesprong <[email protected]>
AuthorDate: Sat Mar 23 11:37:10 2024 +0100
docs: Add links checker (#9965)
* docs: Add links checker
* Comments
* Fix broken paths
* Fix moar links
* Last few
---
.github/workflows/docs-check-links.yml | 40 +++++++++++++++++++++++++++++++++
README.md | 7 ++----
docs/docs/configuration.md | 8 +++----
docs/docs/daft.md | 2 +-
docs/docs/flink-actions.md | 2 +-
docs/docs/flink-connector.md | 6 ++---
docs/docs/flink-ddl.md | 2 +-
docs/docs/flink-queries.md | 2 +-
docs/docs/flink-writes.md | 10 ++++-----
docs/docs/flink.md | 35 +++++++++++++++--------------
docs/docs/spark-configuration.md | 4 ++--
docs/docs/spark-ddl.md | 16 ++++++-------
docs/docs/spark-getting-started.md | 31 ++++++++++++-------------
docs/docs/spark-procedures.md | 8 +++----
docs/docs/spark-queries.md | 4 ++--
docs/docs/spark-structured-streaming.md | 10 ++++-----
docs/docs/spark-writes.md | 10 ++++-----
format/spec.md | 2 +-
site/README.md | 2 +-
site/docs/blogs.md | 11 +++++----
site/docs/how-to-release.md | 2 +-
site/docs/multi-engine-support.md | 12 ++++++++++
site/docs/releases.md | 7 +++---
site/docs/spark-quickstart.md | 1 +
site/docs/vendors.md | 9 +++++---
site/link-checker-config.json | 23 +++++++++++++++++++
26 files changed, 172 insertions(+), 94 deletions(-)
diff --git a/.github/workflows/docs-check-links.yml
b/.github/workflows/docs-check-links.yml
new file mode 100644
index 0000000000..9de842813d
--- /dev/null
+++ b/.github/workflows/docs-check-links.yml
@@ -0,0 +1,40 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+#
+
+name: Check Markdown docs links
+
+on:
+ push:
+ paths:
+ - docs/**
+ - site/**
+ branches:
+ - 'main'
+ pull_request:
+ workflow_dispatch:
+
+jobs:
+ markdown-link-check:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ - uses: gaurav-nelson/github-action-markdown-link-check@v1
+ with:
+ config-file: 'site/link-checker-config.json'
+ use-verbose-mode: yes
diff --git a/README.md b/README.md
index 3ba4f74f87..8d36b212b9 100644
--- a/README.md
+++ b/README.md
@@ -17,7 +17,7 @@
- under the License.
-->
-
+
[](https://github.com/apache/iceberg/actions/workflows/java-ci.yml)
[](https://apache-iceberg.slack.com/)
@@ -37,11 +37,8 @@ The core Java library is located in this repository and is
the reference impleme
[Documentation][iceberg-docs] is available for all libraries and integrations.
-Current work is tracked in the [roadmap][roadmap].
-
[iceberg-docs]: https://iceberg.apache.org/docs/latest/
-[iceberg-spec]: https://iceberg.apache.org/spec
-[roadmap]: https://iceberg.apache.org/roadmap/
+[iceberg-spec]: https://iceberg.apache.org/spec/
## Collaboration
diff --git a/docs/docs/configuration.md b/docs/docs/configuration.md
index d5e33529c0..ec7af06ca7 100644
--- a/docs/docs/configuration.md
+++ b/docs/docs/configuration.md
@@ -108,9 +108,9 @@ Iceberg tables support table properties to configure table
behavior, like the de
Reserved table properties are only used to control behaviors when creating or
updating a table.
The value of these properties are not persisted as a part of the table
metadata.
-| Property | Default | Description
|
-| -------------- | -------- |
------------------------------------------------------------- |
-| format-version | 2 | Table's format version (can be 1 or 2) as
defined in the [Spec](../../../spec/#format-versioning). Defaults to 2 since
version 1.4.0. |
+| Property | Default | Description
|
+| -------------- | --------
|--------------------------------------------------------------------------------------------------------------------------------------|
+| format-version | 2 | Table's format version (can be 1 or 2) as
defined in the [Spec](../../spec.md#format-versioning). Defaults to 2 since
version 1.4.0. |
### Compatibility flags
@@ -131,7 +131,7 @@ Iceberg catalogs support using catalog properties to
configure catalog behaviors
| clients | 2 | client pool size
|
| cache-enabled | true | Whether to cache
catalog entries |
| cache.expiration-interval-ms | 30000 | How long catalog
entries are locally cached, in milliseconds; 0 disables caching, negative
values disable expiration |
-| metrics-reporter-impl | org.apache.iceberg.metrics.LoggingMetricsReporter |
Custom `MetricsReporter` implementation to use in a catalog. See the [Metrics
reporting](../metrics-reporting.md) section for additional details |
+| metrics-reporter-impl | org.apache.iceberg.metrics.LoggingMetricsReporter |
Custom `MetricsReporter` implementation to use in a catalog. See the [Metrics
reporting](metrics-reporting.md) section for additional details |
`HadoopCatalog` and `HiveCatalog` can access the properties in their
constructors.
Any other custom catalog can access the properties by implementing
`Catalog.initialize(catalogName, catalogProperties)`.
diff --git a/docs/docs/daft.md b/docs/docs/daft.md
index da78b7eb6c..71030e3949 100644
--- a/docs/docs/daft.md
+++ b/docs/docs/daft.md
@@ -20,7 +20,7 @@ title: "Daft"
# Daft
-[Daft](www.getdaft.io) is a distributed query engine written in Python and
Rust, two fast-growing ecosystems in the data engineering and machine learning
industry.
+[Daft](https://www.getdaft.io/) is a distributed query engine written in
Python and Rust, two fast-growing ecosystems in the data engineering and
machine learning industry.
It exposes its flavor of the familiar [Python DataFrame
API](https://www.getdaft.io/projects/docs/en/latest/api_docs/dataframe.html)
which is a common abstraction over querying tables of data in the Python data
ecosystem.
diff --git a/docs/docs/flink-actions.md b/docs/docs/flink-actions.md
index 4e54732c3b..c058795fd0 100644
--- a/docs/docs/flink-actions.md
+++ b/docs/docs/flink-actions.md
@@ -20,7 +20,7 @@ title: "Flink Actions"
## Rewrite files action
-Iceberg provides API to rewrite small files into large files by submitting
Flink batch jobs. The behavior of this Flink action is the same as Spark's
[rewriteDataFiles](../maintenance.md#compact-data-files).
+Iceberg provides API to rewrite small files into large files by submitting
Flink batch jobs. The behavior of this Flink action is the same as Spark's
[rewriteDataFiles](maintenance.md#compact-data-files).
```java
import org.apache.iceberg.flink.actions.Actions;
diff --git a/docs/docs/flink-connector.md b/docs/docs/flink-connector.md
index 260a5c5814..025e9aee92 100644
--- a/docs/docs/flink-connector.md
+++ b/docs/docs/flink-connector.md
@@ -29,13 +29,13 @@ To create the table in Flink SQL by using SQL syntax
`CREATE TABLE test (..) WIT
* `connector`: Use the constant `iceberg`.
* `catalog-name`: User-specified catalog name. It's required because the
connector don't have any default value.
* `catalog-type`: `hive` or `hadoop` for built-in catalogs (defaults to
`hive`), or left unset for custom catalog implementations using `catalog-impl`.
-* `catalog-impl`: The fully-qualified class name of a custom catalog
implementation. Must be set if `catalog-type` is unset. See also [custom
catalog](../flink.md#adding-catalogs) for more details.
+* `catalog-impl`: The fully-qualified class name of a custom catalog
implementation. Must be set if `catalog-type` is unset. See also [custom
catalog](flink.md#adding-catalogs) for more details.
* `catalog-database`: The iceberg database name in the backend catalog, use
the current flink database name by default.
* `catalog-table`: The iceberg table name in the backend catalog. Default to
use the table name in the flink `CREATE TABLE` sentence.
## Table managed in Hive catalog.
-Before executing the following SQL, please make sure you've configured the
Flink SQL client correctly according to the [quick start
documentation](../flink.md).
+Before executing the following SQL, please make sure you've configured the
Flink SQL client correctly according to the [quick start
documentation](flink.md).
The following SQL will create a Flink table in the current Flink catalog,
which maps to the iceberg table `default_database.flink_table` managed in
iceberg catalog.
@@ -138,4 +138,4 @@ SELECT * FROM flink_table;
3 rows in set
```
-For more details, please refer to the Iceberg [Flink
documentation](../flink.md).
+For more details, please refer to the Iceberg [Flink documentation](flink.md).
diff --git a/docs/docs/flink-ddl.md b/docs/docs/flink-ddl.md
index 681a018865..c2b3051fde 100644
--- a/docs/docs/flink-ddl.md
+++ b/docs/docs/flink-ddl.md
@@ -150,7 +150,7 @@ Table create commands support the commonly used [Flink
create clauses](https://n
* `PARTITION BY (column1, column2, ...)` to configure partitioning, Flink does
not yet support hidden partitioning.
* `COMMENT 'table document'` to set a table description.
-* `WITH ('key'='value', ...)` to set [table
configuration](../configuration.md) which will be stored in Iceberg table
properties.
+* `WITH ('key'='value', ...)` to set [table configuration](configuration.md)
which will be stored in Iceberg table properties.
Currently, it does not support computed column and watermark definition etc.
diff --git a/docs/docs/flink-queries.md b/docs/docs/flink-queries.md
index 036d95a495..431a5554f2 100644
--- a/docs/docs/flink-queries.md
+++ b/docs/docs/flink-queries.md
@@ -75,7 +75,7 @@ SET table.exec.iceberg.use-flip27-source = true;
### Reading branches and tags with SQL
Branch and tags can be read via SQL by specifying options. For more details
-refer to [Flink Configuration](../flink-configuration.md#read-options)
+refer to [Flink Configuration](flink-configuration.md#read-options)
```sql
--- Read from branch b1
diff --git a/docs/docs/flink-writes.md b/docs/docs/flink-writes.md
index c41b367dea..ef1e602c82 100644
--- a/docs/docs/flink-writes.md
+++ b/docs/docs/flink-writes.md
@@ -67,7 +67,7 @@ Iceberg supports `UPSERT` based on the primary key when
writing data into v2 tab
) with ('format-version'='2', 'write.upsert.enabled'='true');
```
-2. Enabling `UPSERT` mode using `upsert-enabled` in the [write
options](#write-options) provides more flexibility than a table level config.
Note that you still need to use v2 table format and specify the [primary
key](../flink-ddl.md/#primary-key) or [identifier
fields](../../spec.md#identifier-field-ids) when creating the table.
+2. Enabling `UPSERT` mode using `upsert-enabled` in the [write
options](#write-options) provides more flexibility than a table level config.
Note that you still need to use v2 table format and specify the [primary
key](flink-ddl.md/#primary-key) or [identifier
fields](../../spec.md#identifier-field-ids) when creating the table.
```sql
INSERT INTO tableName /*+ OPTIONS('upsert-enabled'='true') */
@@ -185,7 +185,7 @@ FlinkSink.builderFor(
### Branch Writes
Writing to branches in Iceberg tables is also supported via the `toBranch` API
in `FlinkSink`
-For more information on branches please refer to [branches](../branching.md).
+For more information on branches please refer to [branches](branching.md).
```java
FlinkSink.forRowData(input)
.tableLoader(tableLoader)
@@ -262,13 +262,13 @@ INSERT INTO tableName /*+
OPTIONS('upsert-enabled'='true') */
...
```
-Check out all the options here:
[write-options](../flink-configuration.md#write-options)
+Check out all the options here:
[write-options](flink-configuration.md#write-options)
## Notes
Flink streaming write jobs rely on snapshot summary to keep the last committed
checkpoint ID, and
-store uncommitted data as temporary files. Therefore, [expiring
snapshots](../maintenance.md#expire-snapshots)
-and [deleting orphan files](../maintenance.md#delete-orphan-files) could
possibly corrupt
+store uncommitted data as temporary files. Therefore, [expiring
snapshots](maintenance.md#expire-snapshots)
+and [deleting orphan files](maintenance.md#delete-orphan-files) could possibly
corrupt
the state of the Flink job. To avoid that, make sure to keep the last snapshot
created by the Flink
job (which can be identified by the `flink.job-id` property in the summary),
and only delete
orphan files that are old enough.
diff --git a/docs/docs/flink.md b/docs/docs/flink.md
index 7f27a280eb..b8ab694ad9 100644
--- a/docs/docs/flink.md
+++ b/docs/docs/flink.md
@@ -22,22 +22,22 @@ title: "Flink Getting Started"
Apache Iceberg supports both [Apache Flink](https://flink.apache.org/)'s
DataStream API and Table API. See the [Multi-Engine
Support](../../multi-engine-support.md#apache-flink) page for the integration
of Apache Flink.
-| Feature support | Flink | Notes
|
-| -----------------------------------------------------------
|-------|----------------------------------------------------------------------------------------|
-| [SQL create catalog](../flink-ddl.md#create-catalog) | ✔️ |
|
-| [SQL create database](../flink-ddl.md#create-database) | ✔️ |
|
-| [SQL create table](../flink-ddl.md#create-table) |
✔️ |
|
-| [SQL create table like](../flink-ddl.md#create-table-like) |
✔️ |
|
-| [SQL alter table](../flink-ddl.md#alter-table) |
✔️ | Only support altering table properties, column and partition changes
are not supported |
-| [SQL drop_table](../flink-ddl.md#drop-table) |
✔️ |
|
-| [SQL select](../flink-queries.md#reading-with-sql)
| ✔️ | Support both streaming and batch mode
|
-| [SQL insert into](../flink-writes.md#insert-into)
| ✔️ ️ | Support both streaming and batch mode
|
-| [SQL insert overwrite](../flink-writes.md#insert-overwrite)
| ✔️ ️ |
|
-| [DataStream read](../flink-queries.md#reading-with-datastream)
| ✔️ ️ |
|
-| [DataStream append](../flink-writes.md#appending-data)
| ✔️ ️ |
|
-| [DataStream overwrite](../flink-writes.md#overwrite-data)
| ✔️ ️ |
|
-| [Metadata tables](../flink-queries.md#inspecting-tables)
| ✔️ |
|
-| [Rewrite files action](../flink-actions.md#rewrite-files-action)
| ✔️ ️ |
|
+| Feature support | Flink | Notes
|
+| --------------------------------------------------------
|-------|----------------------------------------------------------------------------------------|
+| [SQL create catalog](flink-ddl.md#create-catalog) | ✔️ |
|
+| [SQL create database](flink-ddl.md#create-database) | ✔️ |
|
+| [SQL create table](flink-ddl.md#create-table) | ✔️
|
|
+| [SQL create table like](flink-ddl.md#create-table-like) | ✔️
|
|
+| [SQL alter table](flink-ddl.md#alter-table) | ✔️
| Only support altering table properties, column and partition changes are not
supported |
+| [SQL drop_table](flink-ddl.md#drop-table) | ✔️
|
|
+| [SQL select](flink-queries.md#reading-with-sql) | ✔️
| Support both streaming and batch mode
|
+| [SQL insert into](flink-writes.md#insert-into) | ✔️
️ | Support both streaming and batch mode
|
+| [SQL insert overwrite](flink-writes.md#insert-overwrite) | ✔️
️ |
|
+| [DataStream read](flink-queries.md#reading-with-datastream) |
✔️ ️ |
|
+| [DataStream append](flink-writes.md#appending-data) | ✔️
️ |
|
+| [DataStream overwrite](flink-writes.md#overwrite-data) | ✔️
️ |
|
+| [Metadata tables](flink-queries.md#inspecting-tables) |
✔️ |
|
+| [Rewrite files action](flink-actions.md#rewrite-files-action) | ✔️
️ |
|
## Preparation when using Flink SQL Client
@@ -69,6 +69,7 @@ export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
./bin/start-cluster.sh
```
+<!-- markdown-link-check-disable-next-line -->
Start the Flink SQL client. There is a separate `flink-runtime` module in the
Iceberg project to generate a bundled jar, which could be loaded by Flink SQL
client directly. To build the `flink-runtime` bundled jar manually, build the
`iceberg` project, and it will generate the jar under
`<iceberg-root-dir>/flink-runtime/build/libs`. Or download the `flink-runtime`
jar from the [Apache
repository](https://repo.maven.apache.org/maven2/org/apache/iceberg/iceberg-flink-runtime-1.16/{{
iceber [...]
```bash
@@ -271,7 +272,7 @@ env.execute("Test Iceberg DataStream");
### Branch Writes
Writing to branches in Iceberg tables is also supported via the `toBranch` API
in `FlinkSink`
-For more information on branches please refer to [branches](../branching.md).
+For more information on branches please refer to [branches](branching.md).
```java
FlinkSink.forRowData(input)
.tableLoader(tableLoader)
diff --git a/docs/docs/spark-configuration.md b/docs/docs/spark-configuration.md
index 5e9c6e5d11..6ac4f1e9c8 100644
--- a/docs/docs/spark-configuration.md
+++ b/docs/docs/spark-configuration.md
@@ -78,7 +78,7 @@ Both catalogs are configured using properties nested under
the catalog name. Com
| spark.sql.catalog._catalog-name_.table-default._propertyKey_ |
| Default Iceberg table property value for property key
_propertyKey_, which will be set on tables created by this catalog if not
overridden
|
| spark.sql.catalog._catalog-name_.table-override._propertyKey_ |
| Enforced Iceberg table property value for property key
_propertyKey_, which cannot be overridden by user
|
-Additional properties can be found in common [catalog
configuration](../configuration.md#catalog-properties).
+Additional properties can be found in common [catalog
configuration](configuration.md#catalog-properties).
### Using catalogs
@@ -185,7 +185,7 @@ df.write
| fanout-enabled | false | Overrides this table's
write.spark.fanout.enabled |
| check-ordering | true | Checks if input schema and table schema
are same |
| isolation-level | null | Desired isolation level for Dataframe overwrite
operations. `null` => no checks (for idempotent writes), `serializable` =>
check for concurrent inserts or deletes in destination partitions, `snapshot`
=> checks for concurrent deletes in destination partitions. |
-| validate-from-snapshot-id | null | If isolation level is set, id of base
snapshot from which to check concurrent write conflicts into a table. Should be
the snapshot before any reads from the table. Can be obtained via [Table
API](../api.md#table-metadata) or [Snapshots
table](../spark-queries.md#snapshots). If null, the table's oldest known
snapshot is used. |
+| validate-from-snapshot-id | null | If isolation level is set, id of base
snapshot from which to check concurrent write conflicts into a table. Should be
the snapshot before any reads from the table. Can be obtained via [Table
API](api.md#table-metadata) or [Snapshots table](spark-queries.md#snapshots).
If null, the table's oldest known snapshot is used. |
| compression-codec | Table write.(fileformat).compression-codec |
Overrides this table's compression codec for this write |
| compression-level | Table write.(fileformat).compression-level |
Overrides this table's compression level for Parquet and Avro tables for this
write |
| compression-strategy | Table write.orc.compression-strategy |
Overrides this table's compression strategy for ORC tables for this write |
diff --git a/docs/docs/spark-ddl.md b/docs/docs/spark-ddl.md
index e1376ddcf6..8b30710997 100644
--- a/docs/docs/spark-ddl.md
+++ b/docs/docs/spark-ddl.md
@@ -33,14 +33,14 @@ CREATE TABLE prod.db.sample (
USING iceberg;
```
-Iceberg will convert the column type in Spark to corresponding Iceberg type.
Please check the section of [type compatibility on creating
table](../spark-getting-started.md#spark-type-to-iceberg-type) for details.
+Iceberg will convert the column type in Spark to corresponding Iceberg type.
Please check the section of [type compatibility on creating
table](spark-getting-started.md#spark-type-to-iceberg-type) for details.
Table create commands, including CTAS and RTAS, support the full range of
Spark create clauses, including:
* `PARTITIONED BY (partition-expressions)` to configure partitioning
* `LOCATION '(fully-qualified-uri)'` to set the table location
* `COMMENT 'table documentation'` to set a table description
-* `TBLPROPERTIES ('key'='value', ...)` to set [table
configuration](../configuration.md)
+* `TBLPROPERTIES ('key'='value', ...)` to set [table
configuration](configuration.md)
Create commands may also set the default format with the `USING` clause. This
is only supported for `SparkCatalog` because Spark handles the `USING` clause
differently for the built-in catalog.
@@ -59,7 +59,7 @@ USING iceberg
PARTITIONED BY (category);
```
-The `PARTITIONED BY` clause supports transform expressions to create [hidden
partitions](../partitioning.md).
+The `PARTITIONED BY` clause supports transform expressions to create [hidden
partitions](partitioning.md).
```sql
CREATE TABLE prod.db.sample (
@@ -86,7 +86,7 @@ Note: Old syntax of `years(ts)`, `months(ts)`, `days(ts)` and
`hours(ts)` are al
## `CREATE TABLE ... AS SELECT`
-Iceberg supports CTAS as an atomic operation when using a
[`SparkCatalog`](../spark-configuration.md#catalog-configuration). CTAS is
supported, but is not atomic when using
[`SparkSessionCatalog`](../spark-configuration.md#replacing-the-session-catalog).
+Iceberg supports CTAS as an atomic operation when using a
[`SparkCatalog`](spark-configuration.md#catalog-configuration). CTAS is
supported, but is not atomic when using
[`SparkSessionCatalog`](spark-configuration.md#replacing-the-session-catalog).
```sql
CREATE TABLE prod.db.sample
@@ -106,7 +106,7 @@ AS SELECT ...
## `REPLACE TABLE ... AS SELECT`
-Iceberg supports RTAS as an atomic operation when using a
[`SparkCatalog`](../spark-configuration.md#catalog-configuration). RTAS is
supported, but is not atomic when using
[`SparkSessionCatalog`](../spark-configuration.md#replacing-the-session-catalog).
+Iceberg supports RTAS as an atomic operation when using a
[`SparkCatalog`](spark-configuration.md#catalog-configuration). RTAS is
supported, but is not atomic when using
[`SparkSessionCatalog`](spark-configuration.md#replacing-the-session-catalog).
Atomic table replacement creates a new snapshot with the results of the
`SELECT` query, but keeps table history.
@@ -168,7 +168,7 @@ Iceberg has full `ALTER TABLE` support in Spark 3,
including:
* Widening the type of `int`, `float`, and `decimal` fields
* Making required columns optional
-In addition, [SQL extensions](../spark-configuration.md#sql-extensions) can be
used to add support for partition evolution and setting a table's write order
+In addition, [SQL extensions](spark-configuration.md#sql-extensions) can be
used to add support for partition evolution and setting a table's write order
### `ALTER TABLE ... RENAME TO`
@@ -184,7 +184,7 @@ ALTER TABLE prod.db.sample SET TBLPROPERTIES (
);
```
-Iceberg uses table properties to control table behavior. For a list of
available properties, see [Table configuration](../configuration.md).
+Iceberg uses table properties to control table behavior. For a list of
available properties, see [Table configuration](configuration.md).
`UNSET` is used to remove properties:
@@ -325,7 +325,7 @@ ALTER TABLE prod.db.sample DROP COLUMN point.z;
## `ALTER TABLE` SQL extensions
-These commands are available in Spark 3 when using Iceberg [SQL
extensions](../spark-configuration.md#sql-extensions).
+These commands are available in Spark 3 when using Iceberg [SQL
extensions](spark-configuration.md#sql-extensions).
### `ALTER TABLE ... ADD PARTITION FIELD`
diff --git a/docs/docs/spark-getting-started.md
b/docs/docs/spark-getting-started.md
index 72642cc6e1..2bcdbd23eb 100644
--- a/docs/docs/spark-getting-started.md
+++ b/docs/docs/spark-getting-started.md
@@ -35,12 +35,13 @@ spark-shell --packages
org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:{{ iceb
```
!!! info
+ <!-- markdown-link-check-disable-next-line -->
If you want to include Iceberg in your Spark installation, add the
[`iceberg-spark-runtime-3.5_2.12`
Jar](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/{{
icebergVersion }}/iceberg-spark-runtime-3.5_2.12-{{ icebergVersion }}.jar) to
Spark's `jars` folder.
### Adding catalogs
-Iceberg comes with [catalogs](../spark-configuration.md#catalogs) that enable
SQL commands to manage tables and load them by name. Catalogs are configured
using properties under `spark.sql.catalog.(catalog_name)`.
+Iceberg comes with [catalogs](spark-configuration.md#catalogs) that enable SQL
commands to manage tables and load them by name. Catalogs are configured using
properties under `spark.sql.catalog.(catalog_name)`.
This command creates a path-based catalog named `local` for tables under
`$PWD/warehouse` and adds support for Iceberg tables to Spark's built-in
catalog:
@@ -56,7 +57,7 @@ spark-sql --packages
org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:{{ iceber
### Creating a table
-To create your first Iceberg table in Spark, use the `spark-sql` shell or
`spark.sql(...)` to run a [`CREATE TABLE`](../spark-ddl.md#create-table)
command:
+To create your first Iceberg table in Spark, use the `spark-sql` shell or
`spark.sql(...)` to run a [`CREATE TABLE`](spark-ddl.md#create-table) command:
```sql
-- local is the path-based catalog defined above
@@ -65,21 +66,21 @@ CREATE TABLE local.db.table (id bigint, data string) USING
iceberg;
Iceberg catalogs support the full range of SQL DDL commands, including:
-* [`CREATE TABLE ... PARTITIONED BY`](../spark-ddl.md#create-table)
-* [`CREATE TABLE ... AS SELECT`](../spark-ddl.md#create-table-as-select)
-* [`ALTER TABLE`](../spark-ddl.md#alter-table)
-* [`DROP TABLE`](../spark-ddl.md#drop-table)
+* [`CREATE TABLE ... PARTITIONED BY`](spark-ddl.md#create-table)
+* [`CREATE TABLE ... AS SELECT`](spark-ddl.md#create-table-as-select)
+* [`ALTER TABLE`](spark-ddl.md#alter-table)
+* [`DROP TABLE`](spark-ddl.md#drop-table)
### Writing
-Once your table is created, insert data using [`INSERT
INTO`](../spark-writes.md#insert-into):
+Once your table is created, insert data using [`INSERT
INTO`](spark-writes.md#insert-into):
```sql
INSERT INTO local.db.table VALUES (1, 'a'), (2, 'b'), (3, 'c');
INSERT INTO local.db.table SELECT id, data FROM source WHERE length(data) = 1;
```
-Iceberg also adds row-level SQL updates to Spark, [`MERGE
INTO`](../spark-writes.md#merge-into) and [`DELETE
FROM`](../spark-writes.md#delete-from):
+Iceberg also adds row-level SQL updates to Spark, [`MERGE
INTO`](spark-writes.md#merge-into) and [`DELETE
FROM`](spark-writes.md#delete-from):
```sql
MERGE INTO local.db.target t USING (SELECT * FROM updates) u ON t.id = u.id
@@ -87,7 +88,7 @@ WHEN MATCHED THEN UPDATE SET t.count = t.count + u.count
WHEN NOT MATCHED THEN INSERT *;
```
-Iceberg supports writing DataFrames using the new [v2 DataFrame write
API](../spark-writes.md#writing-with-dataframes):
+Iceberg supports writing DataFrames using the new [v2 DataFrame write
API](spark-writes.md#writing-with-dataframes):
```scala
spark.table("source").select("id", "data")
@@ -106,7 +107,7 @@ FROM local.db.table
GROUP BY data;
```
-SQL is also the recommended way to [inspect
tables](../spark-queries.md#inspecting-tables). To view all snapshots in a
table, use the `snapshots` metadata table:
+SQL is also the recommended way to [inspect
tables](spark-queries.md#inspecting-tables). To view all snapshots in a table,
use the `snapshots` metadata table:
```sql
SELECT * FROM local.db.table.snapshots;
```
@@ -121,7 +122,7 @@ SELECT * FROM local.db.table.snapshots;
+-------------------------+----------------+-----------+-----------+----------------------------------------------------+-----+
```
-[DataFrame reads](../spark-queries.md#querying-with-dataframes) are supported
and can now reference tables by name using `spark.table`:
+[DataFrame reads](spark-queries.md#querying-with-dataframes) are supported and
can now reference tables by name using `spark.table`:
```scala
val df = spark.table("local.db.table")
@@ -192,7 +193,7 @@ This type conversion table describes how Iceberg types are
converted to the Spar
Next, you can learn more about Iceberg tables in Spark:
-* [DDL commands](../spark-ddl.md): `CREATE`, `ALTER`, and `DROP`
-* [Querying data](../spark-queries.md): `SELECT` queries and metadata tables
-* [Writing data](../spark-writes.md): `INSERT INTO` and `MERGE INTO`
-* [Maintaining tables](../spark-procedures.md) with stored procedures
+* [DDL commands](spark-ddl.md): `CREATE`, `ALTER`, and `DROP`
+* [Querying data](spark-queries.md): `SELECT` queries and metadata tables
+* [Writing data](spark-writes.md): `INSERT INTO` and `MERGE INTO`
+* [Maintaining tables](spark-procedures.md) with stored procedures
diff --git a/docs/docs/spark-procedures.md b/docs/docs/spark-procedures.md
index 7dc0d1a2aa..dc439c04c8 100644
--- a/docs/docs/spark-procedures.md
+++ b/docs/docs/spark-procedures.md
@@ -20,7 +20,7 @@ title: "Procedures"
# Spark Procedures
-To use Iceberg in Spark, first configure [Spark
catalogs](../spark-configuration.md). Stored procedures are only available when
using [Iceberg SQL extensions](../spark-configuration.md#sql-extensions) in
Spark 3.
+To use Iceberg in Spark, first configure [Spark
catalogs](spark-configuration.md). Stored procedures are only available when
using [Iceberg SQL extensions](spark-configuration.md#sql-extensions) in Spark
3.
## Usage
@@ -272,7 +272,7 @@ the `expire_snapshots` procedure will never remove files
which are still require
| `stream_results` | | boolean | When true, deletion files will be
sent to Spark driver by RDD partition (by default, all the files will be sent
to Spark driver). This option is recommended to set to `true` to prevent Spark
driver OOM from large file size |
| `snapshot_ids` | | array of long | Array of snapshot IDs to expire. |
-If `older_than` and `retain_last` are omitted, the table's [expiration
properties](../configuration.md#table-behavior-properties) will be used.
+If `older_than` and `retain_last` are omitted, the table's [expiration
properties](configuration.md#table-behavior-properties) will be used.
Snapshots that are still referenced by branches or tags won't be removed. By
default, branches and tags never expire, but their retention policy can be
changed with the table property `history.expire.max-ref-age-ms`. The `main`
branch never expires.
#### Output
@@ -357,7 +357,7 @@ Iceberg can compact data files in parallel using Spark with
the `rewriteDataFile
| `partial-progress.max-commits` | 10 | Maximum amount of commits that this
rewrite is allowed to produce if partial progress is enabled |
| `use-starting-sequence-number` | true | Use the sequence number of the
snapshot at compaction start time instead of that of the newly produced
snapshot |
| `rewrite-job-order` | none | Force the rewrite job order based on the value.
<ul><li>If rewrite-job-order=bytes-asc, then rewrite the smallest job groups
first.</li><li>If rewrite-job-order=bytes-desc, then rewrite the largest job
groups first.</li><li>If rewrite-job-order=files-asc, then rewrite the job
groups with the least files first.</li><li>If rewrite-job-order=files-desc,
then rewrite the job groups with the most files first.</li><li>If
rewrite-job-order=none, then rewrite job g [...]
-| `target-file-size-bytes` | 536870912 (512 MB, default value of
`write.target-file-size-bytes` from [table
properties](../configuration.md#write-properties)) | Target output file size |
+| `target-file-size-bytes` | 536870912 (512 MB, default value of
`write.target-file-size-bytes` from [table
properties](configuration.md#write-properties)) | Target output file size |
| `min-file-size-bytes` | 75% of target file size | Files under this threshold
will be considered for rewriting regardless of any other criteria |
| `max-file-size-bytes` | 180% of target file size | Files with sizes above
this threshold will be considered for rewriting regardless of any other
criteria |
| `min-input-files` | 5 | Any file group exceeding this number of files will
be rewritten regardless of other criteria |
@@ -480,7 +480,7 @@ Dangling deletes are always filtered out during rewriting.
| `partial-progress.enabled` | false | Enable committing groups of files prior
to the entire rewrite completing |
| `partial-progress.max-commits` | 10 | Maximum amount of commits that this
rewrite is allowed to produce if partial progress is enabled |
| `rewrite-job-order` | none | Force the rewrite job order based on the value.
<ul><li>If rewrite-job-order=bytes-asc, then rewrite the smallest job groups
first.</li><li>If rewrite-job-order=bytes-desc, then rewrite the largest job
groups first.</li><li>If rewrite-job-order=files-asc, then rewrite the job
groups with the least files first.</li><li>If rewrite-job-order=files-desc,
then rewrite the job groups with the most files first.</li><li>If
rewrite-job-order=none, then rewrite job g [...]
-| `target-file-size-bytes` | 67108864 (64MB, default value of
`write.delete.target-file-size-bytes` from [table
properties](../configuration.md#write-properties)) | Target output file size |
+| `target-file-size-bytes` | 67108864 (64MB, default value of
`write.delete.target-file-size-bytes` from [table
properties](configuration.md#write-properties)) | Target output file size |
| `min-file-size-bytes` | 75% of target file size | Files under this threshold
will be considered for rewriting regardless of any other criteria |
| `max-file-size-bytes` | 180% of target file size | Files with sizes above
this threshold will be considered for rewriting regardless of any other
criteria |
| `min-input-files` | 5 | Any file group exceeding this number of files will
be rewritten regardless of other criteria |
diff --git a/docs/docs/spark-queries.md b/docs/docs/spark-queries.md
index 092ed6b1d6..536c136d7e 100644
--- a/docs/docs/spark-queries.md
+++ b/docs/docs/spark-queries.md
@@ -20,11 +20,11 @@ title: "Queries"
# Spark Queries
-To use Iceberg in Spark, first configure [Spark
catalogs](../spark-configuration.md). Iceberg uses Apache Spark's DataSourceV2
API for data source and catalog implementations.
+To use Iceberg in Spark, first configure [Spark
catalogs](spark-configuration.md). Iceberg uses Apache Spark's DataSourceV2 API
for data source and catalog implementations.
## Querying with SQL
-In Spark 3, tables use identifiers that include a [catalog
name](../spark-configuration.md#using-catalogs).
+In Spark 3, tables use identifiers that include a [catalog
name](spark-configuration.md#using-catalogs).
```sql
SELECT * FROM prod.db.table; -- catalog: prod, namespace: db, table: table
diff --git a/docs/docs/spark-structured-streaming.md
b/docs/docs/spark-structured-streaming.md
index 5079904207..0ac753808d 100644
--- a/docs/docs/spark-structured-streaming.md
+++ b/docs/docs/spark-structured-streaming.md
@@ -68,7 +68,7 @@ Iceberg supports `append` and `complete` output modes:
* `append`: appends the rows of every micro-batch to the table
* `complete`: replaces the table contents every micro-batch
-Prior to starting the streaming query, ensure you created the table. Refer to
the [SQL create table](../spark-ddl.md#create-table) documentation to learn how
to create the Iceberg table.
+Prior to starting the streaming query, ensure you created the table. Refer to
the [SQL create table](spark-ddl.md#create-table) documentation to learn how to
create the Iceberg table.
Iceberg doesn't support experimental [continuous
processing](https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#continuous-processing),
as it doesn't provide the interface to "commit" the output.
@@ -76,7 +76,7 @@ Iceberg doesn't support experimental [continuous
processing](https://spark.apach
Iceberg requires sorting data by partition per task prior to writing the data.
In Spark tasks are split by Spark partition.
against partitioned table. For batch queries you're encouraged to do explicit
sort to fulfill the requirement
-(see [here](../spark-writes.md#writing-distribution-modes)), but the approach
would bring additional latency as
+(see [here](spark-writes.md#writing-distribution-modes)), but the approach
would bring additional latency as
repartition and sort are considered as heavy operations for streaming
workload. To avoid additional latency, you can
enable fanout writer to eliminate the requirement.
@@ -107,13 +107,13 @@ documents how to configure the interval.
### Expire old snapshots
-Each batch written to a table produces a new snapshot. Iceberg tracks
snapshots in table metadata until they are expired. Snapshots accumulate
quickly with frequent commits, so it is highly recommended that tables written
by streaming queries are [regularly
maintained](../maintenance.md#expire-snapshots). [Snapshot
expiration](../spark-procedures.md#expire_snapshots) is the procedure of
removing the metadata and any data files that are no longer needed. By default,
the procedure will exp [...]
+Each batch written to a table produces a new snapshot. Iceberg tracks
snapshots in table metadata until they are expired. Snapshots accumulate
quickly with frequent commits, so it is highly recommended that tables written
by streaming queries are [regularly
maintained](maintenance.md#expire-snapshots). [Snapshot
expiration](spark-procedures.md#expire_snapshots) is the procedure of removing
the metadata and any data files that are no longer needed. By default, the
procedure will expire th [...]
### Compacting data files
-The amount of data written from a streaming process is typically small, which
can cause the table metadata to track lots of small files. [Compacting small
files into larger files](../maintenance.md#compact-data-files) reduces the
metadata needed by the table, and increases query efficiency. Iceberg and Spark
[comes with the `rewrite_data_files`
procedure](../spark-procedures.md#rewrite_data_files).
+The amount of data written from a streaming process is typically small, which
can cause the table metadata to track lots of small files. [Compacting small
files into larger files](maintenance.md#compact-data-files) reduces the
metadata needed by the table, and increases query efficiency. Iceberg and Spark
[comes with the `rewrite_data_files`
procedure](spark-procedures.md#rewrite_data_files).
### Rewrite manifests
To optimize write latency on a streaming workload, Iceberg can write the new
snapshot with a "fast" append that does not automatically compact manifests.
-This could lead lots of small manifest files. Iceberg can [rewrite the number
of manifest files to improve query
performance](../maintenance.md#rewrite-manifests). Iceberg and Spark [come with
the `rewrite_manifests` procedure](../spark-procedures.md#rewrite_manifests).
+This could lead lots of small manifest files. Iceberg can [rewrite the number
of manifest files to improve query
performance](maintenance.md#rewrite-manifests). Iceberg and Spark [come with
the `rewrite_manifests` procedure](spark-procedures.md#rewrite_manifests).
diff --git a/docs/docs/spark-writes.md b/docs/docs/spark-writes.md
index efc15e7e35..626dee6c96 100644
--- a/docs/docs/spark-writes.md
+++ b/docs/docs/spark-writes.md
@@ -20,9 +20,9 @@ title: "Writes"
# Spark Writes
-To use Iceberg in Spark, first configure [Spark
catalogs](../spark-configuration.md).
+To use Iceberg in Spark, first configure [Spark
catalogs](spark-configuration.md).
-Some plans are only available when using [Iceberg SQL
extensions](../spark-configuration.md#sql-extensions) in Spark 3.
+Some plans are only available when using [Iceberg SQL
extensions](spark-configuration.md#sql-extensions) in Spark 3.
Iceberg uses Apache Spark's DataSourceV2 API for data source and catalog
implementations. Spark DSv2 is an evolving API with different levels of support
in Spark versions:
@@ -200,7 +200,7 @@ Branch writes can also be performed as part of a
write-audit-publish (WAP) workf
Note WAP branch and branch identifier cannot both be specified.
Also, the branch must exist before performing the write.
The operation does **not** create the branch if it does not exist.
-For more information on branches please refer to [branches](../branching.md).
+For more information on branches please refer to [branches](branching.md).
```sql
-- INSERT (1,' a') (2, 'b') into the audit branch.
@@ -364,7 +364,7 @@ There are 3 options for `write.distribution-mode`
This mode does not request any shuffles or sort to be performed automatically
by Spark. Because no work is done
automatically by Spark, the data must be *manually* sorted by partition value.
The data must be sorted either within
each spark task, or globally within the entire dataset. A global sort will
minimize the number of output files.
-A sort can be avoided by using the Spark [write
fanout](../spark-configuration.md#write-options) property but this will cause
all
+A sort can be avoided by using the Spark [write
fanout](spark-configuration.md#write-options) property but this will cause all
file handles to remain open until each write task has completed.
* `hash` - This mode is the new default and requests that Spark uses a
hash-based exchange to shuffle the incoming
write data before writing.
@@ -385,7 +385,7 @@ sort-order. Further division and coalescing of tasks may
take place because of
When writing data to Iceberg with Spark, it's important to note that Spark
cannot write a file larger than a Spark
task and a file cannot span an Iceberg partition boundary. This means although
Iceberg will always roll over a file
-when it grows to
[`write.target-file-size-bytes`](../configuration.md#write-properties), but
unless the Spark task is
+when it grows to
[`write.target-file-size-bytes`](configuration.md#write-properties), but unless
the Spark task is
large enough that will not happen. The size of the file created on disk will
also be much smaller than the Spark task
since the on disk data will be both compressed and in columnar format as
opposed to Spark's uncompressed row
representation. This means a 100 megabyte Spark task will create a file much
smaller than 100 megabytes even if that
diff --git a/format/spec.md b/format/spec.md
index 397057a974..ab6f349483 100644
--- a/format/spec.md
+++ b/format/spec.md
@@ -57,7 +57,7 @@ In addition to row-level deletes, version 2 makes some
requirements stricter for
## Overview
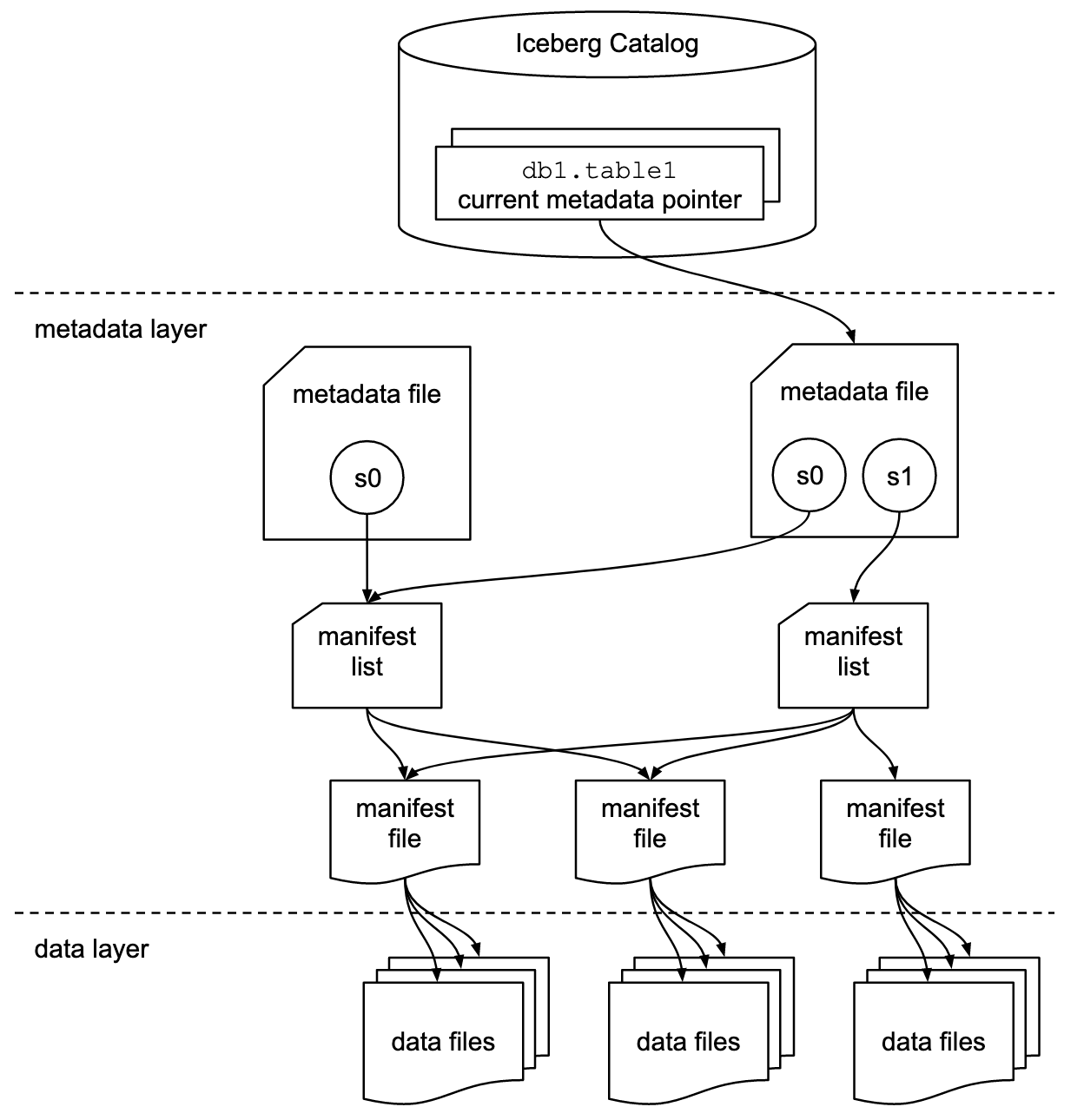
-
+
This table format tracks individual data files in a table instead of
directories. This allows writers to create data files in-place and only adds
files to the table in an explicit commit.
diff --git a/site/README.md b/site/README.md
index 6cb4f4907e..b1f9310e8b 100644
--- a/site/README.md
+++ b/site/README.md
@@ -74,7 +74,6 @@ The docs are built, run, and released using
[make](https://www.gnu.org/software/
> [clean](dev/clean.sh): Clean the local site.
> [deploy](dev/deploy.sh): Clean, build, and deploy the Iceberg docs site.
> help: Show help for each of the Makefile recipes.
-> [release](dev/release.sh): Release the current `/docs` as `ICEBERG_VERSION`
(`make release ICEBERG_VERSION=<MAJOR.MINOR.PATCH>`).
> [serve](dev/serve.sh): Clean, build, and run the site locally.
To scaffold the versioned docs and build the project, run the `build` recipe.
@@ -103,6 +102,7 @@ This step will generate the staged source code which blends
into the original so
└─.asf.yaml
```
+<!-- markdown-link-check-disable-next-line -->
To run this, run the `serve` recipe, which runs the `build` recipe and calls
`mkdocs serve`. This will run locally at <http://localhost:8000>.
```
make serve
diff --git a/site/docs/blogs.md b/site/docs/blogs.md
index 746eef97d6..1714ce5040 100644
--- a/site/docs/blogs.md
+++ b/site/docs/blogs.md
@@ -22,6 +22,7 @@ title: "Blogs"
Here is a list of company blogs that talk about Iceberg. The blogs are ordered
from most recent to oldest.
+<!-- markdown-link-check-disable-next-line -->
### [The Apache Iceberg Lakehouse: The Great Data
Equalizer](https://amdatalakehouse.substack.com/p/the-apache-iceberg-lakehouse-the)
**Date**: March 6th, 2024, **Company**: Dremio
@@ -42,6 +43,7 @@ Here is a list of company blogs that talk about Iceberg. The
blogs are ordered f
**Author**: [Alex Merced](https://www.linkedin.com/in/alexmerced/)
+<!-- markdown-link-check-disable-next-line -->
### [What is the Data Lakehouse and the Role of Apache Iceberg, Nessie and
Dremio?](https://amdatalakehouse.substack.com/p/the-apache-iceberg-lakehouse-the)
**Date**: February 21st, 2024, **Company**: Dremio
@@ -147,6 +149,7 @@ Here is a list of company blogs that talk about Iceberg.
The blogs are ordered f
**Author**: [Dipankar Mazumdar](https://www.linkedin.com/in/dipankar-mazumdar/)
+<!-- markdown-link-check-disable-next-line -->
### [Iceberg Tables: Catalog Support Now
Available](https://www.snowflake.com/blog/iceberg-tables-catalog-support-available-now/)
**Date**: March 29th, 2023, **Company**: Snowflake
@@ -362,6 +365,7 @@ Here is a list of company blogs that talk about Iceberg.
The blogs are ordered f
**Author**: [Sam Redai](https://www.linkedin.com/in/sredai/), [Kyle
Bendickson](https://www.linkedin.com/in/kylebendickson/)
+<!-- markdown-link-check-disable-next-line -->
### [Expanding the Data Cloud with Apache
Iceberg](https://www.snowflake.com/blog/expanding-the-data-cloud-with-apache-iceberg/)
**Date**: January 21st, 2022, **Company**: Snowflake
@@ -377,11 +381,6 @@ Here is a list of company blogs that talk about Iceberg.
The blogs are ordered f
**Author**: [Sam Redai](https://www.linkedin.com/in/sredai/)
-### [Using Flink CDC to synchronize data from MySQL sharding tables and build
real-time data
lake](https://ververica.github.io/flink-cdc-connectors/master/content/quickstart/build-real-time-data-lake-tutorial.html)
-**Date**: November 11th, 2021, **Company**: Ververica, Alibaba Cloud
-
-**Author**: [Yuxia Luo](https://github.com/luoyuxia), [Jark
Wu](https://github.com/wuchong), [Zheng
Hu](https://www.linkedin.com/in/zheng-hu-37017683/)
-
### [Metadata Indexing in
Iceberg](https://tabular.io/blog/iceberg-metadata-indexing/)
**Date**: October 10th, 2021, **Company**: Tabular
@@ -450,7 +449,7 @@ Here is a list of company blogs that talk about Iceberg.
The blogs are ordered f
### [High Throughput Ingestion with
Iceberg](https://medium.com/adobetech/high-throughput-ingestion-with-iceberg-ccf7877a413f)
**Date**: Dec 22nd, 2020, **Company**: Adobe
-**Author**: [Andrei Ionescu](http://linkedin.com/in/andreiionescu), [Shone
Sadler](https://www.linkedin.com/in/shonesadler/), [Anil
Malkani](https://www.linkedin.com/in/anil-malkani-52861a/)
+**Author**: [Andrei Ionescu](https://www.linkedin.com/in/andreiionescu),
[Shone Sadler](https://www.linkedin.com/in/shonesadler/), [Anil
Malkani](https://www.linkedin.com/in/anil-malkani-52861a/)
### [Optimizing data warehouse
storage](https://netflixtechblog.com/optimizing-data-warehouse-storage-7b94a48fdcbe)
**Date**: Dec 21st, 2020, **Company**: Netflix
diff --git a/site/docs/how-to-release.md b/site/docs/how-to-release.md
index de3bcf958c..f65b9d6c39 100644
--- a/site/docs/how-to-release.md
+++ b/site/docs/how-to-release.md
@@ -376,7 +376,7 @@ The last step is to update the `main` branch in
`iceberg-docs` to set the latest
A PR needs to be published in the `iceberg-docs` repository with the following
changes:
1. Update variable `latestVersions.iceberg` to the new release version in
`landing-page/config.toml`
2. Update variable `latestVersions.iceberg` to the new release version and
-`versions.nessie` to the version of `org.projectnessie.nessie:*` from
[versions.props](https://github.com/apache/iceberg/blob/master/versions.props)
in `docs/config.toml`
+`versions.nessie` to the version of `org.projectnessie.nessie:*` from
[mkdocs.yml](https://github.com/apache/iceberg/blob/main/site/mkdocs.yml) in
`docs/config.toml`
3. Update list `versions` with the new release in `landing-page/config.toml`
4. Update list `versions` with the new release in `docs/config.toml`
5. Mark the current latest release notes to past releases under
`landing-page/content/common/release-notes.md`
diff --git a/site/docs/multi-engine-support.md
b/site/docs/multi-engine-support.md
index b0667361ef..ce4de4bdc1 100644
--- a/site/docs/multi-engine-support.md
+++ b/site/docs/multi-engine-support.md
@@ -59,6 +59,8 @@ Each engine version undergoes the following lifecycle stages:
### Apache Spark
+<!-- markdown-link-check-disable -->
+
| Version | Lifecycle Stage | Initial Iceberg Support | Latest Iceberg
Support | Latest Runtime Jar |
| ---------- | ------------------ | -----------------------
|------------------------| ------------------ |
| 2.4 | End of Life | 0.7.0-incubating | 1.2.1
|
[iceberg-spark-runtime-2.4](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-spark-runtime-2.4/1.2.1/iceberg-spark-runtime-2.4-1.2.1.jar)
|
@@ -69,6 +71,8 @@ Each engine version undergoes the following lifecycle stages:
| 3.4 | Maintained | 1.3.0 | {{
icebergVersion }} |
[iceberg-spark-runtime-3.4_2.12](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-spark-runtime-3.4_2.12/{{
icebergVersion }}/iceberg-spark-runtime-3.4_2.12-{{ icebergVersion }}.jar) |
| 3.5 | Maintained | 1.4.0 | {{
icebergVersion }} |
[iceberg-spark-runtime-3.5_2.12](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/{{
icebergVersion }}/iceberg-spark-runtime-3.5_2.12-{{ icebergVersion }}.jar) |
+<!-- markdown-link-check-enable -->
+
* [1] Spark 3.1 shares the same runtime jar `iceberg-spark3-runtime` with
Spark 3.0 before Iceberg 0.13.0
### Apache Flink
@@ -76,6 +80,8 @@ Each engine version undergoes the following lifecycle stages:
Based on the guideline of the Flink community, only the latest 2 minor
versions are actively maintained.
Users should continuously upgrade their Flink version to stay up-to-date.
+<!-- markdown-link-check-disable -->
+
| Version | Lifecycle Stage | Initial Iceberg Support | Latest Iceberg Support
| Latest Runtime Jar
|
| ------- | --------------- | -----------------------
|------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1.11 | End of Life | 0.9.0 | 0.12.1
|
[iceberg-flink-runtime](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-flink-runtime/0.12.1/iceberg-flink-runtime-0.12.1.jar)
|
@@ -87,15 +93,21 @@ Users should continuously upgrade their Flink version to
stay up-to-date.
| 1.17 | Maintained | 1.3.0 | {{ icebergVersion }}
|
[iceberg-flink-runtime-1.17](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-flink-runtime-1.17/{{
icebergVersion }}/iceberg-flink-runtime-1.17-{{ icebergVersion }}.jar) |
| 1.18 | Maintained | 1.5.0 | {{ icebergVersion }}
|
[iceberg-flink-runtime-1.18](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-flink-runtime-1.18/{{
icebergVersion }}/iceberg-flink-runtime-1.18-{{ icebergVersion }}.jar) |
+<!-- markdown-link-check-enable -->
+
* [3] Flink 1.12 shares the same runtime jar `iceberg-flink-runtime` with
Flink 1.11 before Iceberg 0.13.0
### Apache Hive
+<!-- markdown-link-check-disable -->
+
| Version | Recommended minor version | Lifecycle Stage | Initial
Iceberg Support | Latest Iceberg Support | Latest Runtime Jar |
| -------------- | ------------------------- | ----------------- |
----------------------- | ---------------------- | ------------------ |
| 2 | 2.3.8 | Maintained |
0.8.0-incubating | {{ icebergVersion }} |
[iceberg-hive-runtime](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-hive-runtime/{{
icebergVersion }}/iceberg-hive-runtime-{{ icebergVersion }}.jar) |
| 3 | 3.1.2 | Maintained | 0.10.0
| {{ icebergVersion }} |
[iceberg-hive-runtime](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-hive-runtime/{{
icebergVersion }}/iceberg-hive-runtime-{{ icebergVersion }}.jar) |
+<!-- markdown-link-check-enable -->
+
## Developer Guide
### Maintaining existing engine versions
diff --git a/site/docs/releases.md b/site/docs/releases.md
index 89c963f25a..09b7f43938 100644
--- a/site/docs/releases.md
+++ b/site/docs/releases.md
@@ -20,6 +20,8 @@ title: "Releases"
## Downloads
+<!-- markdown-link-check-disable -->
+
The latest version of Iceberg is [{{ icebergVersion
}}](https://github.com/apache/iceberg/releases/tag/apache-iceberg-{{
icebergVersion }}).
* [{{ icebergVersion }} source
tar.gz](https://www.apache.org/dyn/closer.cgi/iceberg/apache-iceberg-{{
icebergVersion }}/apache-iceberg-{{ icebergVersion }}.tar.gz) --
[signature](https://downloads.apache.org/iceberg/apache-iceberg-{{
icebergVersion }}/apache-iceberg-{{ icebergVersion }}.tar.gz.asc) --
[sha512](https://downloads.apache.org/iceberg/apache-iceberg-{{ icebergVersion
}}/apache-iceberg-{{ icebergVersion }}.tar.gz.sha512)
@@ -34,6 +36,8 @@ The latest version of Iceberg is [{{ icebergVersion
}}](https://github.com/apach
* [{{ icebergVersion }} gcp-bundle
Jar](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-gcp-bundle/{{
icebergVersion }}/iceberg-gcp-bundle-{{ icebergVersion }}.jar)
* [{{ icebergVersion }} azure-bundle
Jar](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-azure-bundle/{{
icebergVersion }}/iceberg-azure-bundle-{{ icebergVersion }}.jar)
+<!-- markdown-link-check-enable -->
+
To use Iceberg in Spark or Flink, download the runtime JAR for your engine
version and add it to the jars folder of your installation.
To use Iceberg in Hive 2 or Hive 3, download the Hive runtime JAR and add it
to Hive using `ADD JAR`.
@@ -970,6 +974,3 @@ A more exhaustive list of changes is available under the
[0.10.0 release milesto
### 0.7.0
* Git tag:
[apache-iceberg-0.7.0-incubating](https://github.com/apache/iceberg/releases/tag/apache-iceberg-0.7.0-incubating)
-* [0.7.0-incubating source
tar.gz](https://www.apache.org/dyn/closer.cgi/incubator/iceberg/apache-iceberg-0.7.0-incubating/apache-iceberg-0.7.0-incubating.tar.gz)
--
[signature](https://dist.apache.org/repos/dist/release/incubator/iceberg/apache-iceberg-0.7.0-incubating/apache-iceberg-0.7.0-incubating.tar.gz.asc)
--
[sha512](https://dist.apache.org/repos/dist/release/incubator/iceberg/apache-iceberg-0.7.0-incubating/apache-iceberg-0.7.0-incubating.tar.gz.sha512)
-* [0.7.0-incubating Spark 2.4 runtime
Jar](https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-spark-runtime/0.7.0-incubating/iceberg-spark-runtime-0.7.0-incubating.jar)
-
diff --git a/site/docs/spark-quickstart.md b/site/docs/spark-quickstart.md
index 9601bcbdb0..5a940009f9 100644
--- a/site/docs/spark-quickstart.md
+++ b/site/docs/spark-quickstart.md
@@ -335,6 +335,7 @@ If you already have a Spark environment, you can add
Iceberg, using the `--packa
If you want to include Iceberg in your Spark installation, add the Iceberg
Spark runtime to Spark's `jars` folder.
You can download the runtime by visiting to the [Releases](releases.md)
page.
+<!-- markdown-link-check-disable-next-line -->
[spark-runtime-jar]:
https://search.maven.org/remotecontent?filepath=org/apache/iceberg/iceberg-spark-runtime-3.5_2.12/{{
icebergVersion }}/iceberg-spark-runtime-3.5_2.12-{{ icebergVersion }}.jar
#### Learn More
diff --git a/site/docs/vendors.md b/site/docs/vendors.md
index 7609dcdf19..d549219e5c 100644
--- a/site/docs/vendors.md
+++ b/site/docs/vendors.md
@@ -58,10 +58,13 @@ IOMETE is a fully-managed ready to use, batteries included
Data Platform. IOMETE
PuppyGraph is a cloud-native graph analytics engine that enables users to
query one or more relational data stores as a unified graph model. This
eliminates the overhead of deploying and maintaining a siloed graph database
system, with no ETL required. [PuppyGraph’s native Apache Iceberg
integration](https://docs.puppygraph.com/user-manual/getting-started/iceberg)
adds native graph capabilities to your existing data lake in an easy and
performant way.
-### [Snowflake](http://snowflake.com/)
-[Snowflake](https://www.snowflake.com/en/) is a single, cross-cloud platform
that enables every organization to mobilize their data with Snowflake’s Data
Cloud. Snowflake supports Apache Iceberg by offering [Snowflake-managed Iceberg
Tables](https://docs.snowflake.com/en/user-guide/tables-iceberg#use-snowflake-as-the-iceberg-catalog)
for full DML as well as [externally managed Iceberg Tables with catalog
integrations](https://docs.snowflake.com/en/user-guide/tables-iceberg#use-a-catalog-
[...]
+<!-- markdown-link-check-disable-next-line -->
+### [Snowflake](https://snowflake.com/)
-### [Starburst](http://starburst.io)
+<!-- markdown-link-check-disable-next-line -->
+[Snowflake](https://www.snowflake.com/) is a single, cross-cloud platform that
enables every organization to mobilize their data with Snowflake’s Data Cloud.
Snowflake supports Apache Iceberg by offering [Snowflake-managed Iceberg
Tables](https://docs.snowflake.com/en/user-guide/tables-iceberg#use-snowflake-as-the-iceberg-catalog)
for full DML as well as [externally managed Iceberg Tables with catalog
integrations](https://docs.snowflake.com/en/user-guide/tables-iceberg#use-a-catalog-int
[...]
+
+### [Starburst](https://starburst.io)
Starburst is a commercial offering for the [Trino query
engine](https://trino.io). Trino is a distributed MPP SQL query engine that can
query data in Iceberg at interactive speeds. Trino also enables you to join
Iceberg tables with an [array of other
systems](https://trino.io/docs/current/connector.html). Starburst offers both
an [enterprise
deployment](https://www.starburst.io/platform/starburst-enterprise/) and a
[fully managed service](https://www.starburst.io/platform/starburst-galax [...]
diff --git a/site/link-checker-config.json b/site/link-checker-config.json
new file mode 100644
index 0000000000..8eed0c1634
--- /dev/null
+++ b/site/link-checker-config.json
@@ -0,0 +1,23 @@
+{
+ "ignorePatterns": [
+ {
+ "pattern": "^https://www.linkedin.com/";
+ },
+ {
+ "pattern": "^https://mvnrepository.com/";
+ },
+ {
+ "pattern": "^../../javadoc"
+ }
+ ],
+ "replacementPatterns": [
+ {
+ "pattern": "^docs/latest/",
+ "replacement": "{{BASEURL}}/docs/docs/"
+ },
+ {
+ "pattern": "^../../",
+ "replacement": "{{BASEURL}}/site/docs/"
+ }
+ ]
+}
\ No newline at end of file
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}