This is an automated email from the ASF dual-hosted git repository.
amoghj pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/iceberg.git
The following commit(s) were added to refs/heads/main by this push:
new 07afd84080 Docs: Add BladePipe to list of vendors and blog posts
(#13510)
07afd84080 is described below
commit 07afd84080b323c37cb11cbc657fb719891ed91c
Author: ChocZoe <[email protected]>
AuthorDate: Tue Jul 15 04:58:56 2025 +0800
Docs: Add BladePipe to list of vendors and blog posts (#13510)
---
docs/docs/bladepipe.md | 119 +++++++++++++++++++++++++++++++++++++++++++++++++
docs/mkdocs.yml | 1 +
site/docs/blogs.md | 5 +++
site/docs/vendors.md | 4 ++
4 files changed, 129 insertions(+)
diff --git a/docs/docs/bladepipe.md b/docs/docs/bladepipe.md
new file mode 100644
index 0000000000..73831ad3ca
--- /dev/null
+++ b/docs/docs/bladepipe.md
@@ -0,0 +1,119 @@
+---
+title: "BladePipe"
+---
+<!--
+ - Licensed to the Apache Software Foundation (ASF) under one or more
+ - contributor license agreements. See the NOTICE file distributed with
+ - this work for additional information regarding copyright ownership.
+ - The ASF licenses this file to You under the Apache License, Version 2.0
+ - (the "License"); you may not use this file except in compliance with
+ - the License. You may obtain a copy of the License at
+ -
+ - http://www.apache.org/licenses/LICENSE-2.0
+ -
+ - Unless required by applicable law or agreed to in writing, software
+ - distributed under the License is distributed on an "AS IS" BASIS,
+ - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ - See the License for the specific language governing permissions and
+ - limitations under the License.
+ -->
+
+# BladePipe
+
+[BladePipe](https://www.bladepipe.com/) is a real-time end-to-end data
integration tool, offering 40+ out-of-the-box connectors for analytics or AI.
It allows to move data faster and easier than ever, with ultra-low latency less
than 3 seconds. It provides a one-stop data movement solution, including schema
evolution, data migration and sync, verification and correction, monitoring and
alerting.
+
+## Supported Sources
+Now BladePipe supports data integration to Iceberg from the following sources:
+
+- MySQL/MariaDB/AuroraMySQL
+- Oracle
+- PostgreSQL
+- SQL Server
+- Kafka
+
+More sources are to be supported.
+
+## Supported Catalogs and Storage
+BladePipe currently supports 3 catalogs and 2 object storage:
+
+- AWS Glue + AWS S3
+- Nessie + MinIO / AWS S3
+- REST Catalog + MinIO / AWS S3
+
+
+## Getting Started
+In this article, we will show how to load data from MySQL (self-hosted) to
Iceberg (AWS Glue + S3).
+
+### 1. Download and Run BladePipe
+Follow the instructions in [Install Worker
(Docker)](https://doc.bladepipe.com/productOP/byoc/installation/install_worker_docker)
or [Install Worker
(Binary)](https://doc.bladepipe.com/productOP/byoc/installation/install_worker_binary)
to download and install a BladePipe Worker.
+
+**Note**: Alternatively, you can choose to deploy and run [BladePipe
Enterprise](https://doc.bladepipe.com/productOP/onPremise/installation/install_all_in_one_binary).
+
+### 2. Add DataSources
+
+1. Log in to the [BladePipe Cloud](https://cloud.bladepipe.com).
+2. Click **DataSource** > **Add DataSource**.
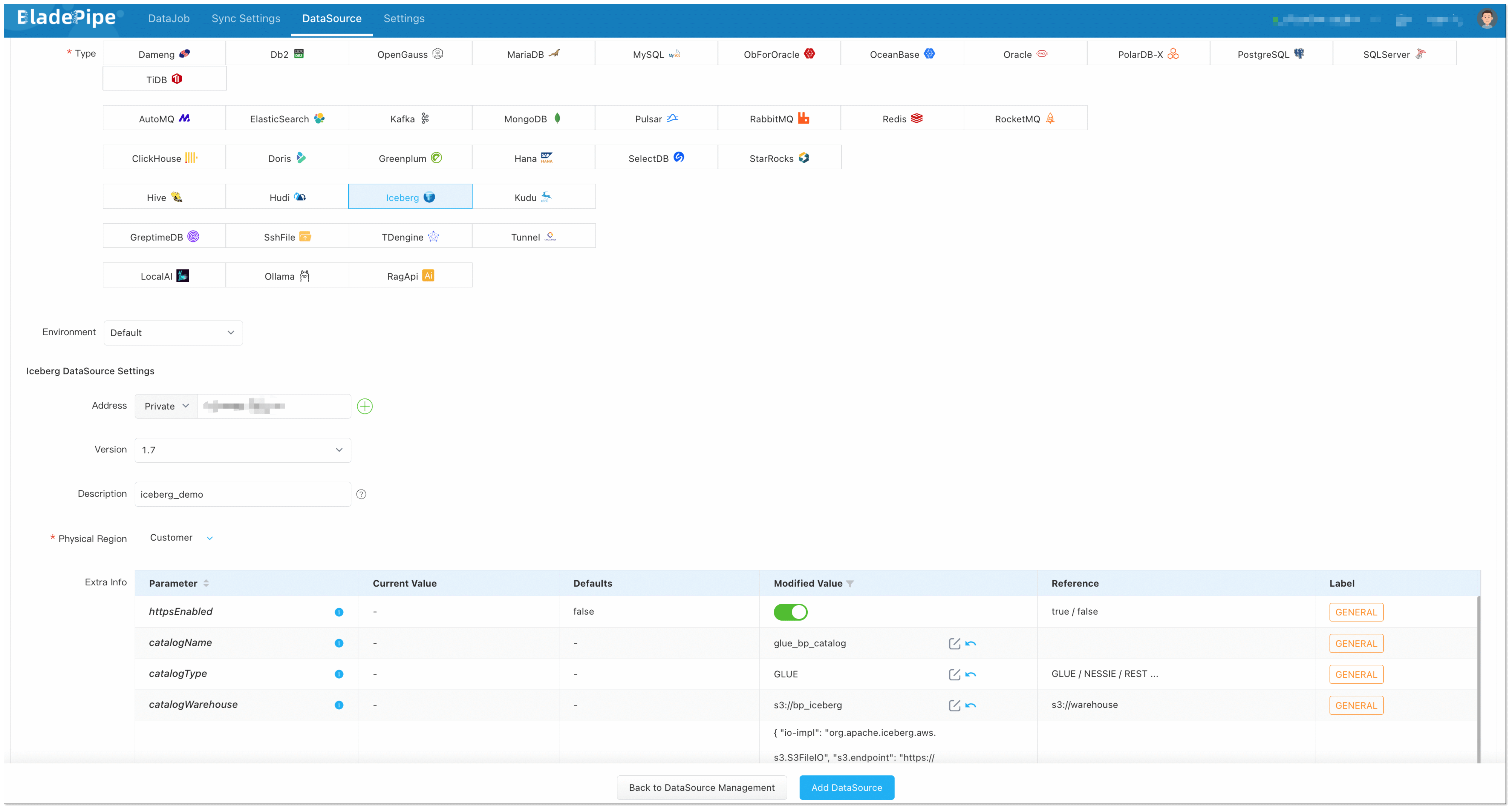
+3. Add a MySQL instance and an Iceberg instance. For Iceberg, fill in the
following content (replace `<...>` with your values):
+ - **Address**: Fill in the AWS Glue endpoint.
+
+ ```text
+ glue.<aws_glue_region_code>.amazonaws.com
+ ```
+
+ - **Version**: Leave as default.
+ - **Description**: Fill in meaningful words to help identify it.
+ - **Extra Info**:
+ - **httpsEnabled**: Enable it to set the value as true.
+ - **catalogName**: Enter a meaningful name, such as
glue_<biz_name>_catalog.
+ - **catalogType**: Fill in `GLUE`.
+ - **catalogWarehouse**: The place where metadata and files are stored,
such as s3://<biz_name>_iceberg.
+ - **catalogProps**:
+
+ ```json
+ {
+ "io-impl": "org.apache.iceberg.aws.s3.S3FileIO",
+ "s3.endpoint": "https://s3.<aws_s3_region_code>.amazonaws.com",
+ "s3.access-key-id": "<aws_s3_iam_user_access_key>",
+ "s3.secret-access-key": "<aws_s3_iam_user_secret_key>",
+ "s3.path-style-access": "true",
+ "client.region": "<aws_s3_region>",
+ "client.credentials-provider.glue.access-key-id":
"<aws_glue_iam_user_access_key>",
+ "client.credentials-provider.glue.secret-access-key":
"<aws_glue_iam_user_secret_key>",
+ "client.credentials-provider":
"com.amazonaws.glue.catalog.credentials.GlueAwsCredentialsProvider"
+ }
+ ```
+
+ 
+ See [Add an Iceberg
DataSource](https://doc.bladepipe.com/dataMigrationAndSync/datasource_func/Iceberg/props_for_iceberg_ds)
for more details.
+
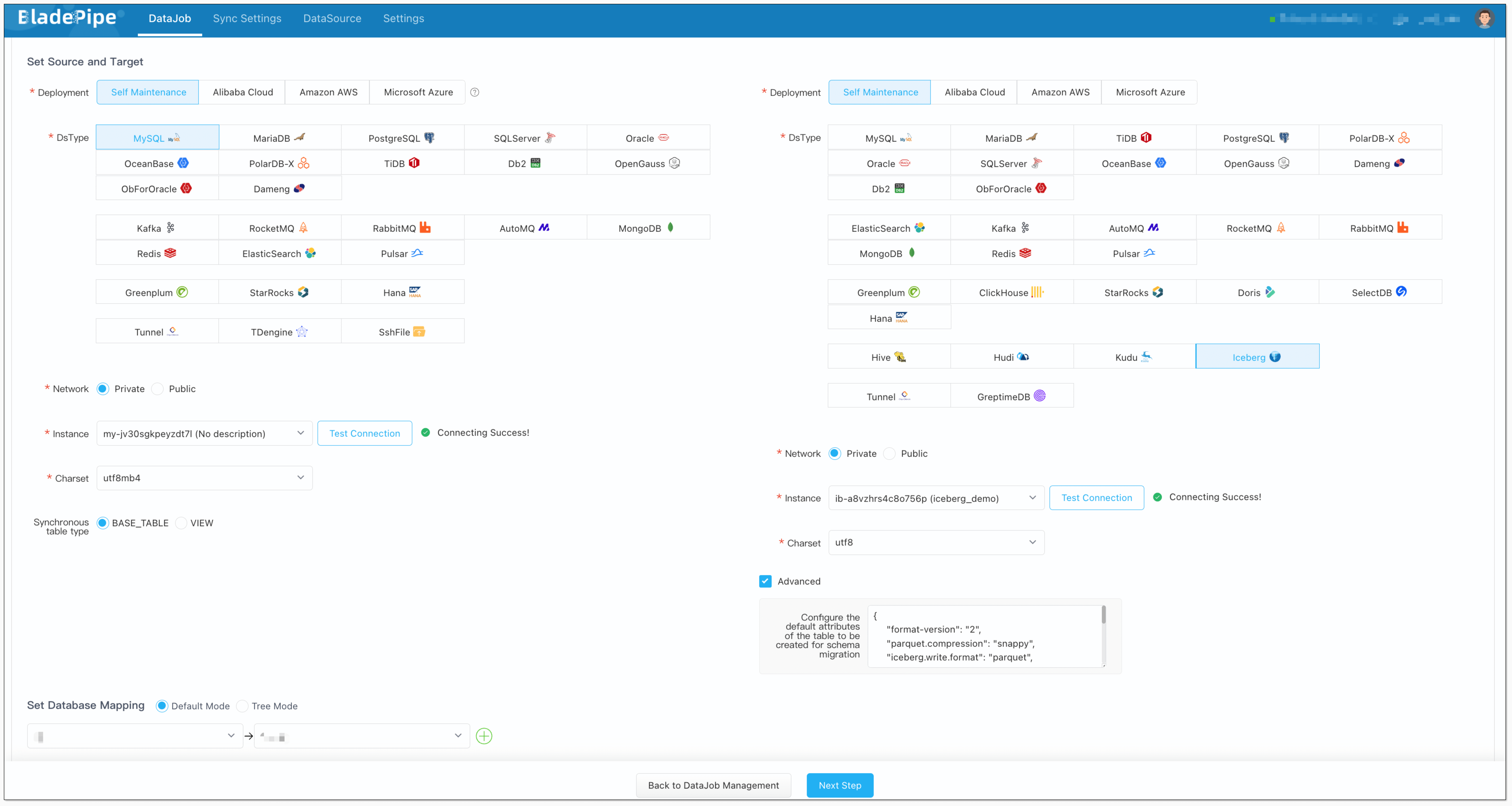
+### 3. Create a DataJob
+1. Go to **DataJob** > [**Create
DataJob**](https://doc.bladepipe.com/operation/job_manage/create_job/create_full_incre_task).
+2. Select the source and target DataSources, and click **Test Connection** for
both. Here's the recommended Iceberg structure configuration:
+ ```json
+ {
+ "format-version": "2",
+ "parquet.compression": "snappy",
+ "iceberg.write.format": "parquet",
+ "write.metadata.delete-after-commit.enabled": "true",
+ "write.metadata.previous-versions-max": "3",
+ "write.update.mode": "merge-on-read",
+ "write.delete.mode": "merge-on-read",
+ "write.merge.mode": "merge-on-read",
+ "write.distribution-mode": "hash",
+ "write.object-storage.enabled": "true",
+ "write.spark.accept-any-schema": "true"
+ }
+ ```
+ 
+
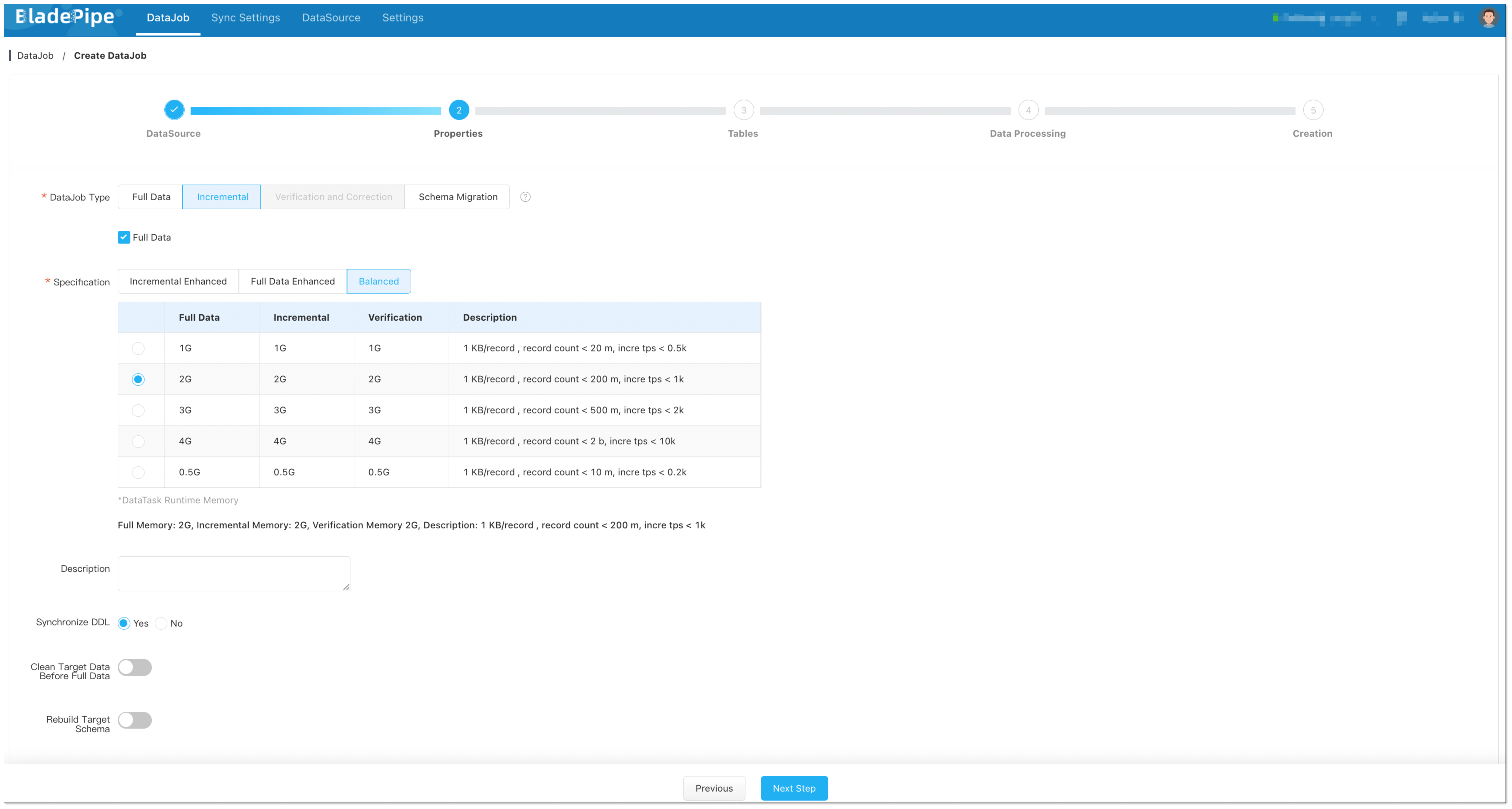
+3. Select **Incremental** for DataJob Type, together with the **Full Data**
option.
+ 
+
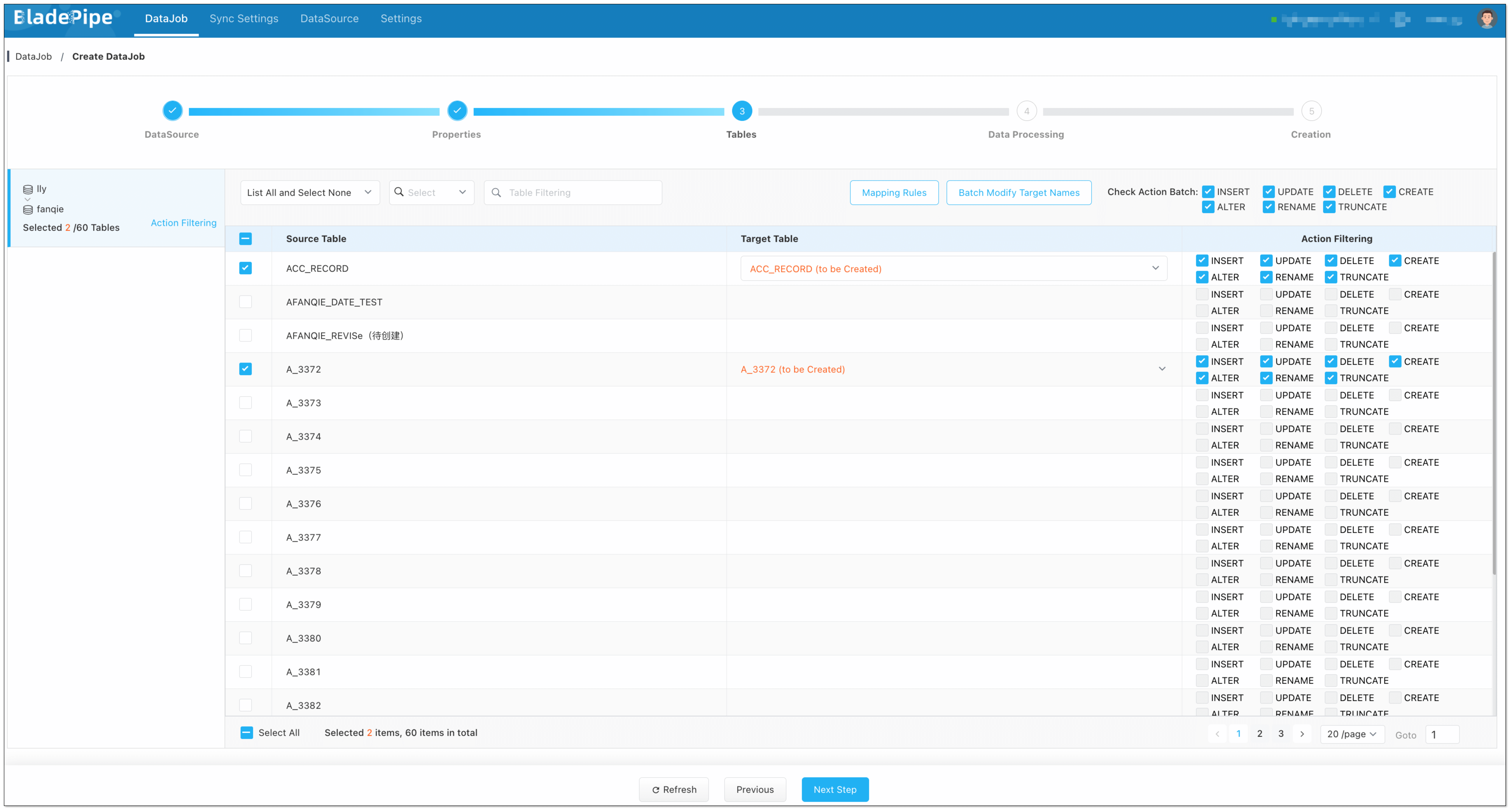
+4. Select the tables to be replicated.
+ 
+
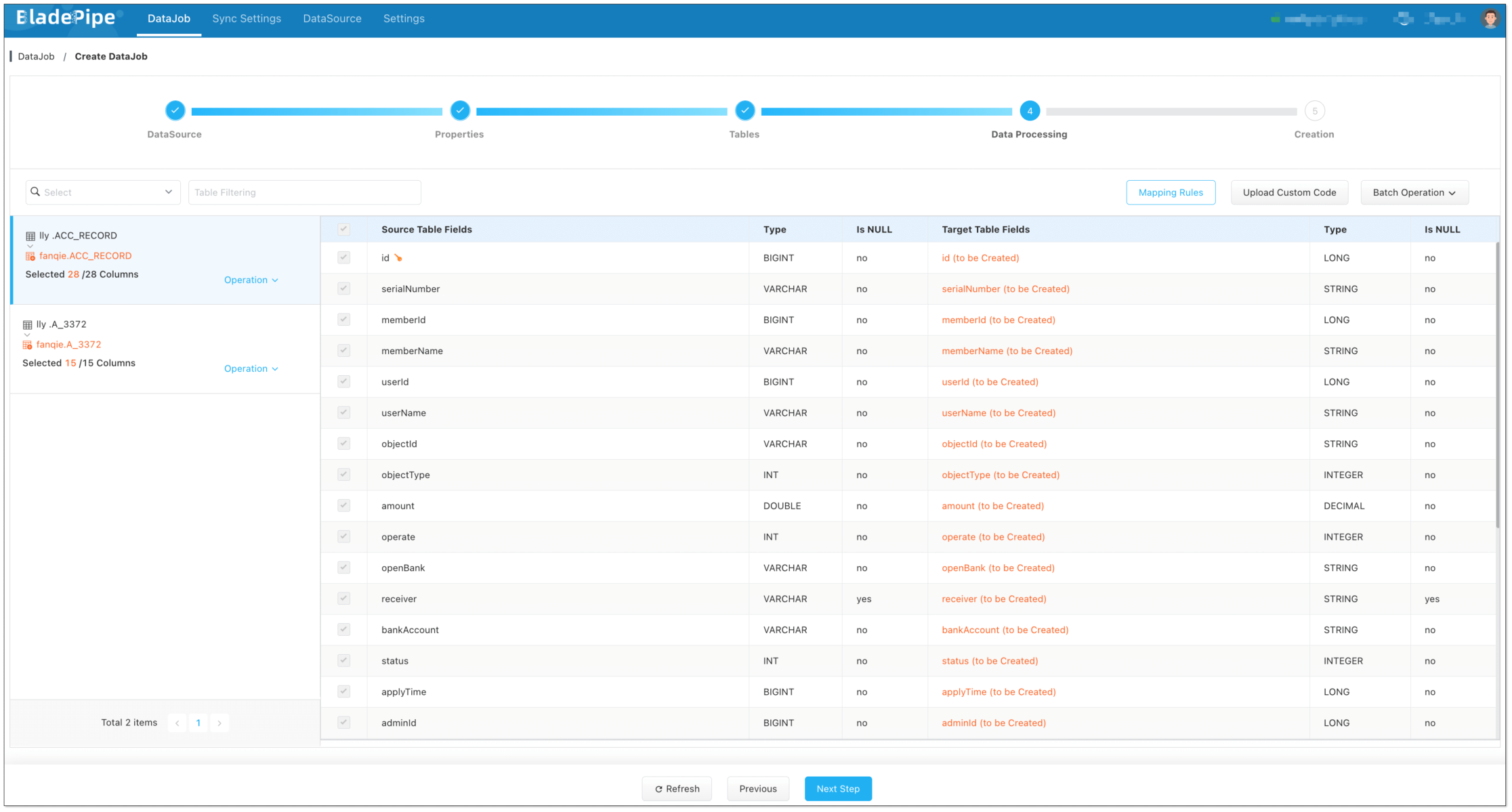
+5. Select the columns to be replicated.
+ 
+
+6. Confirm the DataJob creation, and start to run the DataJob.
+

diff --git a/docs/mkdocs.yml b/docs/mkdocs.yml
index 0d8d5e78a9..e20b0e6628 100644
--- a/docs/mkdocs.yml
+++ b/docs/mkdocs.yml
@@ -53,6 +53,7 @@ nav:
- hive.md
- Trino: https://trino.io/docs/current/connector/iceberg.html
- Daft: daft.md
+ - BladePipe: bladepipe.md
- Firebolt:
https://docs.firebolt.io/reference-sql/functions-reference/table-valued/read_iceberg
- Estuary:
https://docs.estuary.dev/reference/Connectors/materialization-connectors/apache-iceberg/
- Tinybird:
https://www.tinybird.co/docs/forward/get-data-in/table-functions/iceberg
diff --git a/site/docs/blogs.md b/site/docs/blogs.md
index b445136122..8d619f7445 100644
--- a/site/docs/blogs.md
+++ b/site/docs/blogs.md
@@ -22,6 +22,11 @@ title: "Blogs"
Here is a list of company blogs that talk about Iceberg. The blogs are ordered
from most recent to oldest.
+<!-- markdown-link-check-disable-next-line -->
+### [How to Load Data from MySQL to Iceberg in Real
Time](https://doc.bladepipe.com/blog/tech_share/mysql_iceberg_sync)
+**Date:** July 10, 2025, **Company**: BladePipe
+**Author**: [BladePipe](https://www.bladepipe.com)
+
<!-- markdown-link-check-disable-next-line -->
### [Making Sense of Apache Iceberg
Statistics](https://www.ryft.io/blog/making-sense-of-apache-iceberg-statistics)
**Date:** July 9, 2025, **Company**: Ryft
diff --git a/site/docs/vendors.md b/site/docs/vendors.md
index 31997f9a47..64ec6bd360 100644
--- a/site/docs/vendors.md
+++ b/site/docs/vendors.md
@@ -26,6 +26,10 @@ This page contains some of the vendors who are shipping and
supporting Apache Ic
AWS provides a [comprehensive suite of
services](https://aws.amazon.com/what-is/apache-iceberg/#seo-faq-pairs#what-aws-services-support-iceberg)
to support Apache Iceberg as part of its modern data architecture. [Amazon
Athena](https://aws.amazon.com/athena/) offers a serverless, interactive query
engine with native support for Iceberg, enabling fast and cost-efficient
querying of large-scale datasets. [Amazon EMR](https://aws.amazon.com/emr/)
integrates Iceberg with Apache Spark, Apache [...]
+### [BladePipe](https://bladepipe.com)
+
+BladePipe is a real-time end-to-end data integration tool, offering 40+
out-of-the-box connectors. It provides a one-stop data movement solution,
including schema evolution, data migration and sync, verification and
correction, monitoring and alerting. With sub-second latency, BladePipe
captures change data from MySQL, Oracle, PostgreSQL and other sources and
streams it to Iceberg and more, all without writing a single line of code. It
offers [on-premise and BYOC deployment options](http [...]
+
### [Bodo](https://bodo.ai)
Bodo is a high performance SQL & Python compute engine that brings HPC and
supercomputing techniques to data analytics.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}