This is an automated email from the ASF dual-hosted git repository.
qiaojialin pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/iotdb-docs.git
The following commit(s) were added to refs/heads/main by this push:
new bfbf784 update the doc of data sync (#116)
bfbf784 is described below
commit bfbf78416a1b7d126dcf72cab7b92f281f30734c
Author: wanghui42 <105700158+wanghu...@users.noreply.github.com>
AuthorDate: Thu Nov 16 16:19:40 2023 +0800
update the doc of data sync (#116)
---
.../V1.2.x/User-Manual/Data-Sync_timecho.md | 593 ++++++++-------------
...-Sync_timecho.md => Stage_Data-Sync_timecho.md} | 0
2 files changed, 223 insertions(+), 370 deletions(-)
diff --git a/src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
b/src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
index 4799744..7acf914 100644
--- a/src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
+++ b/src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
@@ -7,9 +7,9 @@
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
-
+
http://www.apache.org/licenses/LICENSE-2.0
-
+
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
@@ -19,451 +19,283 @@
-->
-# IoTDB 数据同步
+# 数据同步
+数据同步是工业物联网的典型需求,通过数据同步机制,可实现IoTDB之间的数据共享,搭建完整的数据链路来满足内网外网数据互通、端边云同步、数据迁移、数据备份等需求。
-**IoTDB 数据同步功能可以将 IoTDB 的数据传输到另一个数据平台,我们将<font color=RED>一个数据同步任务称为
Pipe</font>。**
+## 功能介绍
-**一个 Pipe 包含三个子任务(插件):**
+### 同步任务概述
-- 抽取(Extract)
-- 处理(Process)
-- 发送(Connect)
+一个数据同步任务包含2个阶段:
-**Pipe 允许用户自定义三个子任务的处理逻辑,通过类似 UDF 的方式处理数据。** 在一个 Pipe
中,上述的子任务分别由三种插件执行实现,数据会依次经过这三个插件进行处理:Pipe Extractor 用于抽取数据,Pipe Processor
用于处理数据,Pipe Connector 用于发送数据,最终数据将被发至外部系统。
+- 抽取(Extract)阶段:该部分用于从源 IoTDB 抽取数据,在SQL语句中的 Extractor 部分定义
+- 发送(Connect)阶段:该部分用于向目标 IoTDB 发送数据,在SQL语句中的 Connector 部分定义
-**Pipe 任务的模型如下:**
-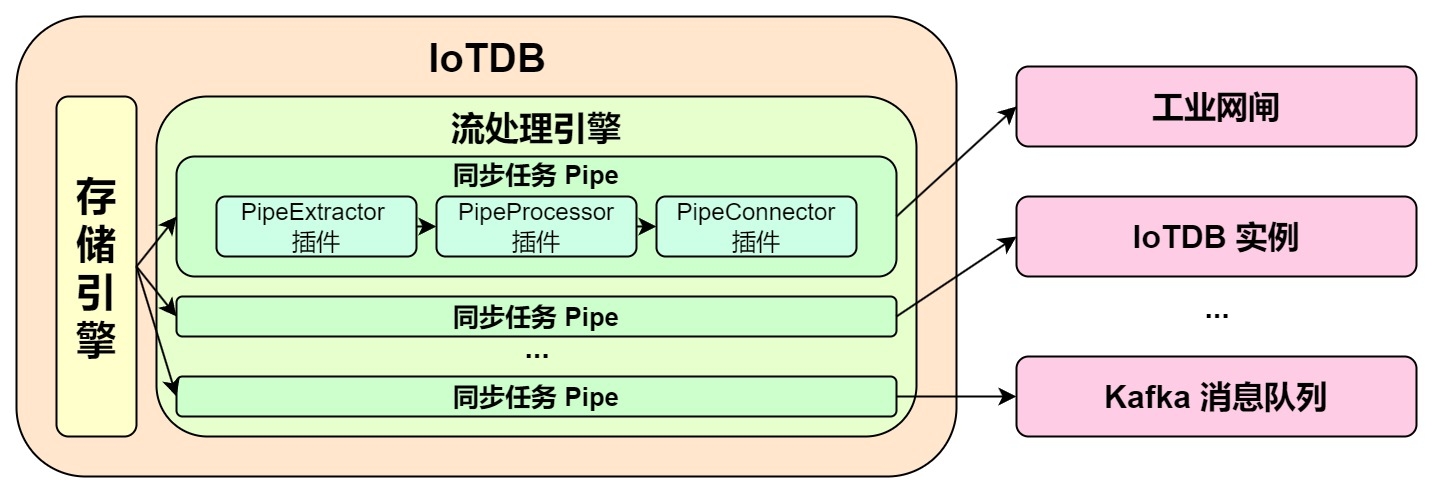
-描述一个数据同步任务,本质就是描述 Pipe Extractor、Pipe Processor 和 Pipe Connector 插件的属性。用户可以通过
SQL 语句声明式地配置三个子任务的具体属性,通过组合不同的属性,实现灵活的数据 ETL 能力。
+通过 SQL 语句声明式地配置2个部分的具体内容,可实现灵活的数据同步能力。
-利用数据同步功能,可以搭建完整的数据链路来满足端*边云同步、异地灾备、读写负载分库*等需求。
+### 同步任务 - 创建
-## 快速开始
+使用 `CREATE PIPE`
语句来创建一条数据同步任务,下列属性中`PipeId`和`connector`为必填项,`extractor`和`processor`为选填项,输入SQL时注意
`EXTRACTOR `与 `CONNECTOR` 插件顺序不能替换。
-**🎯 目标:实现 IoTDB A -> IoTDB B 的全量数据同步**
+SQL 示例如下:
-- 启动两个 IoTDB,A(datanode -> 127.0.0.1:6667) B(datanode -> 127.0.0.1:6668)
-- 创建 A -> B 的 Pipe,在 A 上执行
-
- ```sql
- create pipe a2b
- with connector (
- 'connector'='iotdb-thrift-connector',
- 'connector.ip'='127.0.0.1',
- 'connector.port'='6668'
- )
- ```
-- 启动 A -> B 的 Pipe,在 A 上执行
-
- ```sql
- start pipe a2b
- ```
-- 向 A 写入数据
-
- ```sql
- INSERT INTO root.db.d(time, m) values (1, 1)
- ```
-- 在 B 检查由 A 同步过来的数据
-
- ```sql
- SELECT ** FROM root
- ```
-
-> ❗️**注:目前的 IoTDB -> IoTDB 的数据同步实现并不支持 DDL 同步**
->
-> 即:不支持 ttl,trigger,别名,模板,视图,创建/删除序列,创建/删除存储组等操作
->
-> **IoTDB -> IoTDB 的数据同步要求目标端 IoTDB:**
->
-> * 开启自动创建元数据:需要人工配置数据类型的编码和压缩与发送端保持一致
-> * 不开启自动创建元数据:手工创建与源端一致的元数据
-
-## 同步任务管理
-
-### 创建同步任务
-
-可以使用 `CREATE PIPE` 语句来创建一条数据同步任务,示例 SQL 语句如下所示:
-
-```sql
-CREATE PIPE <PipeId> -- PipeId 是能够唯一标定同步任务任务的名字
-WITH EXTRACTOR (
- -- 默认的 IoTDB 数据抽取插件
- 'extractor' = 'iotdb-extractor',
- -- 路径前缀,只有能够匹配该路径前缀的数据才会被抽取,用作后续的处理和发送
- 'extractor.pattern' = 'root.timecho',
- -- 是否抽取历史数据
- 'extractor.history.enable' = 'true',
- -- 描述被抽取的历史数据的时间范围,表示最早时间
- 'extractor.history.start-time' = '2011.12.03T10:15:30+01:00',
- -- 描述被抽取的历史数据的时间范围,表示最晚时间
- 'extractor.history.end-time' = '2022.12.03T10:15:30+01:00',
- -- 是否抽取实时数据
- 'extractor.realtime.enable' = 'true',
- -- 描述实时数据的抽取方式
- 'extractor.realtime.mode' = 'hybrid',
-)
-WITH PROCESSOR (
- -- 默认的数据处理插件,即不做任何处理
- 'processor' = 'do-nothing-processor',
-)
-WITH CONNECTOR (
- -- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
- -- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
- -- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
-)
-```
-
-**创建同步任务时需要配置 PipeId 以及三个插件部分的参数:**
-
-
-| 配置项 | 说明 | 是否必填
| 默认实现 | 默认实现说明 |
是否允许自定义实现 |
-| --------- | ------------------------------------------------- |
--------------------------- | -------------------- |
------------------------------------------------------ |
------------------------- |
-| PipeId | 全局唯一标定一个同步任务的名称 | <font color=red>必填</font> |
- | - |
- |
-| extractor | Pipe Extractor 插件,负责在数据库底层抽取同步数据 | 选填 |
iotdb-extractor | 将数据库的全量历史数据和后续到达的实时数据接入同步任务 | 否 |
-| processor | Pipe Processor 插件,负责处理数据 | 选填
| do-nothing-processor | 对传入的数据不做任何处理 | <font
color=red>是</font> |
-| connector | Pipe Connector 插件,负责发送数据 | <font
color=red>必填</font> | - | -
| <font color=red>是</font> |
-
-示例中,使用了 iotdb-extractor、do-nothing-processor 和 iotdb-thrift-connector
插件构建数据同步任务。IoTDB 还内置了其他的数据同步插件,**请查看“系统预置数据同步插件”一节**。
-
-**一个最简的 CREATE PIPE 语句示例如下:**
-
-```sql
+```SQL
CREATE PIPE <PipeId> -- PipeId 是能够唯一标定任务任务的名字
+-- 数据抽取插件,必填插件
+WITH EXTRACTOR (
+ [<parameter> = <value>,],
+-- 数据连接插件,必填插件
WITH CONNECTOR (
- -- IoTDB 数据发送插件,目标端为 IoTDB
- 'connector' = 'iotdb-thrift-connector',
- -- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
- 'connector.ip' = '127.0.0.1',
- -- 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
- 'connector.port' = '6667',
+ [<parameter> = <value>,],
)
```
+> 📌 注:使用数据同步功能,请保证接收端开启自动创建元数据
-其表达的语义是:将本数据库实例中的全量历史数据和后续到达的实时数据,同步到目标为 127.0.0.1:6667 的 IoTDB 实例上。
-
-**注意:**
-- EXTRACTOR 和 PROCESSOR 为选填配置,若不填写配置参数,系统则会采用相应的默认实现
-- CONNECTOR 为必填配置,需要在 CREATE PIPE 语句中声明式配置
-- CONNECTOR 具备自复用能力。对于不同的任务,如果他们的 CONNECTOR 具备完全相同 KV 属性的(所有属性的 key 对应的 value
都相同),**那么系统最终只会创建一个 CONNECTOR 实例**,以实现对连接资源的复用。
- - 例如,有下面 pipe1, pipe2 两个任务的声明:
+### 同步任务 - 管理
- ```sql
- CREATE PIPE pipe1
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.host' = 'localhost',
- 'connector.thrift.port' = '9999',
- )
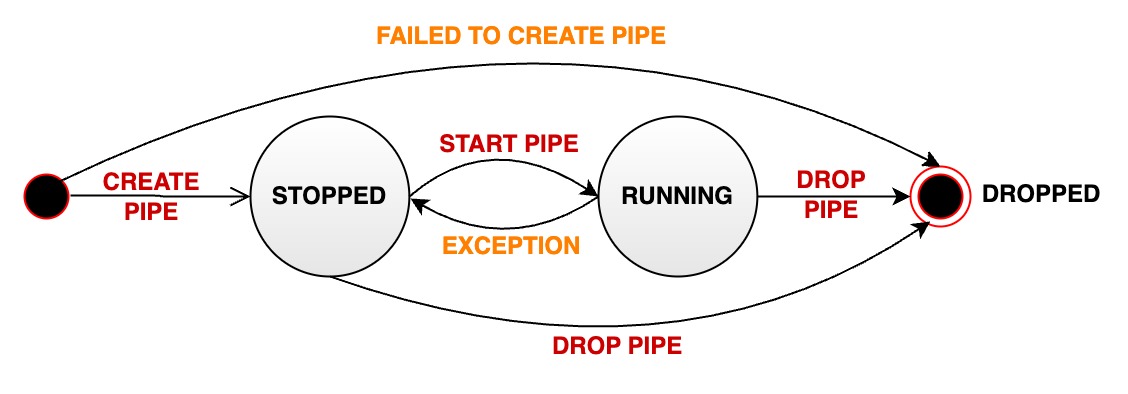
+数据同步任务有三种状态:RUNNING、STOPPED和DROPPED。任务状态转换如下图所示:
- CREATE PIPE pipe2
- WITH CONNECTOR (
- 'connector' = 'iotdb-thrift-connector',
- 'connector.thrift.port' = '9999',
- 'connector.thrift.host' = 'localhost',
- )
- ```
+
- - 因为它们对 CONNECTOR 的声明完全相同(**即使某些属性声明时的顺序不同**),所以框架会自动对它们声明的 CONNECTOR
进行复用,最终 pipe1, pipe2 的CONNECTOR 将会是同一个实例。
-- 在 extractor 为默认的 iotdb-extractor,且 extractor.forwarding-pipe-requests 为默认值
true 时,请不要构建出包含数据循环同步的应用场景(会导致无限循环):
+一个数据同步任务在生命周期中会经过多种状态:
- - IoTDB A -> IoTDB B -> IoTDB A
- - IoTDB A -> IoTDB A
+- RUNNING: 运行状态。
+- STOPPED: 停止状态。
+ - 说明1:任务的初始状态为停止状态,需要使用SQL语句启动任务
+ - 说明2:用户也可以使用SQL语句手动将一个处于运行状态的任务停止,此时状态会从 RUNNING 变为 STOPPED
+ - 说明3:当一个任务出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
+- DROPPED:删除状态。
-### 启动任务
+我们提供以下SQL语句对同步任务进行状态管理。
-CREATE PIPE 语句成功执行后,任务相关实例会被创建,但整个任务的运行状态会被置为 STOPPED,即任务不会立刻处理数据。
+#### 启动任务
-可以使用 START PIPE 语句使任务开始处理数据:
+创建之后,任务不会立即被处理,需要启动任务。使用`START PIPE`语句来启动任务,从而开始处理数据:
-```sql
-START PIPE <PipeId>
+```Go
+START PIPE<PipeId>
```
-### 停止任务
+#### 停止任务
-使用 STOP PIPE 语句使任务停止处理数据:
+停止处理数据:
-```sql
+```Go
STOP PIPE <PipeId>
```
-### 删除任务
+#### 删除任务
-使用 DROP PIPE 语句使任务停止处理数据(当任务状态为 RUNNING 时),然后删除整个任务同步任务:
+删除指定任务:
-```sql
+```Go
DROP PIPE <PipeId>
```
+删除任务不需要先停止同步任务。
+#### 查看任务
-用户在删除任务前,不需要执行 STOP 操作。
+查看全部任务:
-### 展示任务
-
-使用 SHOW PIPES 语句查看所有任务:
-
-```sql
+```Go
SHOW PIPES
```
-查询结果如下:
+查看指定任务:
-```sql
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-| ID| CreationTime |
State|PipeExtractor|PipeProcessor|PipeConnector|ExceptionMessage|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-kafka|2022-03-30T20:58:30.689|RUNNING| ...| ...|
...| None|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-|iotdb-iotdb|2022-03-31T12:55:28.129|STOPPED| ...| ...|
...| TException: ...|
-+-----------+-----------------------+-------+-------------+-------------+-------------+----------------+
-```
-
-可以使用 `<PipeId>` 指定想看的某个同步任务状态:
-
-```sql
+```Go
SHOW PIPE <PipeId>
```
-您也可以通过 where 子句,判断某个 \<PipeId\> 使用的 Pipe Connector 被复用的情况。
+### 插件
-```sql
-SHOW PIPES
-WHERE CONNECTOR USED BY <PipeId>
-```
+为了使得整体架构更加灵活以匹配不同的同步场景需求,在上述同步任务框架中IoTDB支持进行插件组装。系统为您预置了一些常用插件可直接使用,同时您也可以自定义
connector 插件,并加载至IoTDB系统进行使用。
-### 任务运行状态迁移
+| 模块 | 插件 | 预置插件 | 自定义插件 |
+| --- | --- | --- | --- |
+| 抽取(Extract) | Extractor 插件 | iotdb-extractor | 不支持 |
+| 发送(Connect) | Connector 插件 | iotdb-thrift-connector、iotdb-air-gap-connector|
支持 |
-一个数据同步 pipe 在其被管理的生命周期中会经过多种状态:
+#### 预置插件
-- **STOPPED:** pipe 处于停止运行状态。当管道处于该状态时,有如下几种可能:
- - 当一个 pipe 被成功创建之后,其初始状态为暂停状态
- - 用户手动将一个处于正常运行状态的 pipe 暂停,其状态会被动从 RUNNING 变为 STOPPED
- - 当一个 pipe 运行过程中出现无法恢复的错误时,其状态会自动从 RUNNING 变为 STOPPED
-- **RUNNING:** pipe 正在正常工作
-- **DROPPED:** pipe 任务被永久删除
+预置插件如下:
-下图表明了所有状态以及状态的迁移:
+| 插件名称 | 类型 | 介绍
| 适用版本 |
+| ---------------------------- | ---- |
------------------------------------------------------------ | --------- |
+| iotdb-extractor | extractor 插件 | 默认的extractor插件,用于抽取 IoTDB
历史或实时数据 | 1.2.x |
+| iotdb-thrift-connector | connector 插件 | 用于 IoTDB(v1.2.0及以上)与
IoTDB(v1.2.0及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO
模型,传输性能高,尤其适用于目标端为分布式时的场景 | 1.2.x |
+| iotdb-air-gap-connector | connector 插件 | 用于 IoTDB(v1.2.2+)向
IoTDB(v1.2.2+)跨单向数据网闸的数据同步。支持的网闸型号包括南瑞 Syskeeper 2000 等 | 1.2.1以上 |
-
-
-## 系统预置数据同步插件
+每个插件的详细参数可参考本文[参数说明](#connector-参数)章节。
-### 查看预置插件
+#### 查看插件
-用户可以按需查看系统中的插件。查看插件的语句如图所示。
+查看系统中的插件(含自定义与内置插件)可以用以下语句:
-```sql
+```Go
SHOW PIPEPLUGINS
```
-### 预置 extractor 插件
-
-#### iotdb-extractor
-
-作用:抽取 IoTDB 内部的历史或实时数据进入 pipe。
-
-
-| key | value
| value 取值范围 | required or optional with
default |
-| ---------------------------------- |
------------------------------------------------ |
-------------------------------------- | --------------------------------- |
-| extractor | iotdb-extractor
| String: iotdb-extractor | required
|
-| extractor.pattern | 用于筛选时间序列的路径前缀 |
String: 任意的时间序列前缀 | optional: root |
-| extractor.history.enable | 是否同步历史数据
| Boolean: true, false | optional: true |
-| extractor.history.start-time | 同步历史数据的开始 event time,包含 start-time |
Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MIN_VALUE |
-| extractor.history.end-time | 同步历史数据的结束 event time,包含 end-time |
Long: [Long.MIN_VALUE, Long.MAX_VALUE] | optional: Long.MAX_VALUE |
-| extractor.realtime.enable | 是否同步实时数据
| Boolean: true, false | optional: true |
-| extractor.realtime.mode | 实时数据的抽取模式
| String: hybrid, log, file | optional: hybrid |
-| extractor.forwarding-pipe-requests | 是否转发由其他 Pipe (通常是数据同步)写入的数据 | Boolean:
true, false | optional: true |
-
-> 🚫 **extractor.pattern 参数说明**
->
-> * Pattern 需用反引号修饰不合法字符或者是不合法路径节点,例如如果希望筛选 root.\`a@b\` 或者 root.\`123\`,应设置
pattern 为 root.\`a@b\` 或者 root.\`123\`(具体参考
[单双引号和反引号的使用时机](https://iotdb.apache.org/zh/Download/#_1-0-版本不兼容的语法详细说明))
-> * 在底层实现中,当检测到 pattern 为 root(默认值)时,同步效率较高,其他任意格式都将降低性能
-> * 路径前缀不需要能够构成完整的路径。例如,当创建一个包含参数为 'extractor.pattern'='root.aligned.1' 的 pipe
时:
->
-> * root.aligned.1TS
-> * root.aligned.1TS.\`1\`
-> * root.aligned.100TS
->
-> 的数据会被同步;
->
-> * root.aligned.\`1\`
-> * root.aligned.\`123\`
->
-> 的数据不会被同步。
-> * root.\_\_system 的数据不会被 pipe 抽取,即不会被同步到目标端。用户虽然可以在 extractor.pattern
中包含任意前缀,包括带有(或覆盖) root.\__system 的前缀,但是 root.__system 下的数据总是会被 pipe 忽略的
-
-> ❗️**extractor.history 的 start-time,end-time 参数说明**
->
-> * start-time,end-time 应为 ISO 格式,例如 2011-12-03T10:15:30 或
2011-12-03T10:15:30+01:00
-
-> ✅ **一条数据从生产到落库 IoTDB,包含两个关键的时间概念**
->
-> * **event time:** 数据实际生产时的时间(或者数据生产系统给数据赋予的生成时间,是数据点中的时间项),也称为事件时间。
-> * **arrival time:** 数据到达 IoTDB 系统内的时间。
->
-> 我们常说的乱序数据,指的是数据到达时,其 **event time** 远落后于当前系统时间(或者已经落库的最大 **event
time**)的数据。另一方面,不论是乱序数据还是顺序数据,只要它们是新到达系统的,那它们的 **arrival time** 都是会随着数据到达 IoTDB
的顺序递增的。
-
-> 💎 **iotdb-extractor 的工作可以拆分成两个阶段**
->
-> 1. 历史数据抽取:所有 **arrival time** < 创建 pipe 时**当前系统时间**的数据称为历史数据
-> 2. 实时数据抽取:所有 **arrival time** >= 创建 pipe 时**当前系统时间**的数据称为实时数据
->
-> 历史数据传输阶段和实时数据传输阶段,**两阶段串行执行,只有当历史数据传输阶段完成后,才执行实时数据传输阶段。**
->
-> 用户可以指定 iotdb-extractor 进行:
->
-> * 历史数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable'
= 'false'` )
-> * 实时数据抽取(`'extractor.history.enable' = 'false'`,
`'extractor.realtime.enable' = 'true'` )
-> * 全量数据抽取(`'extractor.history.enable' = 'true'`, `'extractor.realtime.enable'
= 'true'` )
-> * 禁止同时设置 `extractor.history.enable` 和 `extractor.realtime.enable` 为 `false`
+返回结果如下(其中部分插件为系统内部插件,将在1.3.0版本中删除):
+
+```Go
+IoTDB> SHOW PIPEPLUGINS
++----------------------------+----------+--------------------------------------------------------------------------------+----------------------------------------------------+
+| PluginName|PluginType|
ClassName|
PluginJar|
++----------------------------+----------+--------------------------------------------------------------------------------+----------------------------------------------------+
+| DO-NOTHING-CONNECTOR| Builtin|
org.apache.iotdb.commons.pipe.plugin.builtin.connector.DoNothingConnector|
|
+| DO-NOTHING-PROCESSOR| Builtin|
org.apache.iotdb.commons.pipe.plugin.builtin.processor.DoNothingProcessor|
|
+| IOTDB-AIR-GAP-CONNECTOR| Builtin|
org.apache.iotdb.commons.pipe.plugin.builtin.connector.IoTDBAirGapConnector|
|
+| IOTDB-EXTRACTOR| Builtin|
org.apache.iotdb.commons.pipe.plugin.builtin.extractor.IoTDBExtractor|
|
+| IOTDB-LEGACY-PIPE-CONNECTOR| Builtin|
org.apache.iotdb.commons.pipe.plugin.builtin.connector.IoTDBLegacyPipeConnector|
|
+|IOTDB-THRIFT-ASYNC-CONNECTOR|
Builtin|org.apache.iotdb.commons.pipe.plugin.builtin.connector.IoTDBThriftAsyncConnector|
|
+| IOTDB-THRIFT-CONNECTOR| Builtin|
org.apache.iotdb.commons.pipe.plugin.builtin.connector.IoTDBThriftConnector|
|
+| IOTDB-THRIFT-SYNC-CONNECTOR| Builtin|
org.apache.iotdb.commons.pipe.plugin.builtin.connector.IoTDBThriftSyncConnector|
|
++----------------------------+----------+--------------------------------------------------------------------------------+----------------------------------------------------+
+```
-> 📌 **extractor.realtime.mode:数据抽取的模式**
->
-> * log:该模式下,任务仅使用操作日志进行数据处理、发送
-> * file:该模式下,任务仅使用数据文件进行数据处理、发送
-> *
hybrid:该模式,考虑了按操作日志逐条目发送数据时延迟低但吞吐低的特点,以及按数据文件批量发送时发送吞吐高但延迟高的特点,能够在不同的写入负载下自动切换适合的数据抽取方式,首先采取基于操作日志的数据抽取方式以保证低发送延迟,当产生数据积压时自动切换成基于数据文件的数据抽取方式以保证高发送吞吐,积压消除时自动切换回基于操作日志的数据抽取方式,避免了采用单一数据抽取算法难以平衡数据发送延迟或吞吐的问题。
+## 使用示例
-> 🍕 **extractor.forwarding-pipe-requests:是否允许转发从另一 pipe 传输而来的数据**
->
-> * 如果要使用 pipe 构建 A -> B -> C 的数据同步,那么 B -> C 的 pipe 需要将该参数为 true 后,A -> B 中 A
通过 pipe 写入 B 的数据才能被正确转发到 C
-> * 如果要使用 pipe 构建 A \<-> B 的双向数据同步(双活),那么 A -> B 和 B -> A 的 pipe 都需要将该参数设置为
false,否则将会造成数据无休止的集群间循环转发
+### 全量数据同步
-### 预置 processor 插件
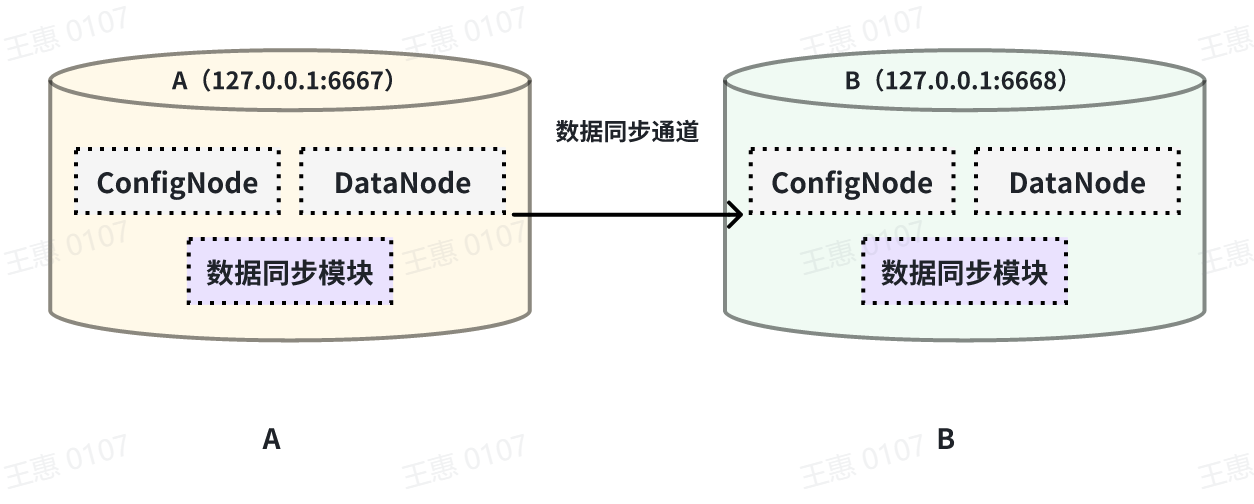
+本例子用来演示将一个 IoTDB 的所有数据同步至另一个IoTDB,数据链路如下图所示:
-#### do-nothing-processor
+
-作用:不对 extractor 传入的事件做任何的处理。
+在这个例子中,我们可以创建一个名为 A2B 的同步任务,用来同步 A IoTDB 到 B IoTDB 间的全量数据,这里需要用到用到 connector 的
iotdb-thrift-connector
插件(内置插件),需指定接收端地址,这个例子中指定了'connector.ip'和'connector.port',也可指定'connector.node-urls',如下面的示例语句:
+```Go
+create pipe A2B
+with connector (
+ 'connector'='iotdb-thrift-connector',
+ 'connector.ip'='127.0.0.1',
+ 'connector.port'='6668'
+)
+```
-| key | value | value 取值范围 | required or
optional with default |
-| --------- | -------------------- | ---------------------------- |
--------------------------------- |
-| processor | do-nothing-processor | String: do-nothing-processor | required
|
-### 预置 connector 插件
+### 历史数据同步
-#### iotdb-thrift-sync-connector(别名:iotdb-thrift-connector)
+本例子用来演示同步某个历史时间范围(2023年8月23日8点到2023年10月23日8点)的数据至另一个IoTDB,数据链路如下图所示:
-作用:主要用于 IoTDB(v1.2.0+)与 IoTDB(v1.2.0+)之间的数据传输。
-使用 Thrift RPC 框架传输数据,单线程 blocking IO 模型。
-保证接收端 apply 数据的顺序与发送端接受写入请求的顺序一致。
+
-限制:源端 IoTDB 与 目标端 IoTDB 版本都需要在 v1.2.0+。
+在这个例子中,我们可以创建一个名为 A2B 的同步任务。首先我们需要在 extractor
中定义传输数据的范围,由于传输的是历史数据(历史数据是指同步任务创建之前存在的数据),所以需要将extractor.realtime.enable参数配置为false;同时需要配置数据的起止时间start-time和end-time以及传输的模式mode,此处推荐mode设置为
hybrid 模式(hybrid模式为混合传输,在无数据积压时采用实时传输方式,有数据积压时采用批量传输方式,并根据系统内部情况自动切换)。
+详细语句如下:
-| key | value
| value 取值范围
| required or optional with default
|
-| --------------------------------- |
--------------------------------------------------------------------------- |
---------------------------------------------------------------------------- |
----------------------------------------------------- |
-| connector | iotdb-thrift-connector 或
iotdb-thrift-sync-connector | String:
iotdb-thrift-connector 或 iotdb-thrift-sync-connector | required
|
-| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
| String
| optional: 与 connector.node-urls 任选其一填写 |
-| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
| Integer
| optional: 与 connector.node-urls 任选其一填写 |
-| connector.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url
| String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669',
'127.0.0.1:6667' | optional: 与 connector.ip:connector.port 任选其一填写 |
-| connector.batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS
| Boolean: true, false
| optional: true |
-| connector.batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) |
Integer |
optional: 1 |
-| connector.batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte)
| Long
| optional: 16 * 1024 * 1024 (16MiB) |
-
-> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
-
-#### iotdb-thrift-async-connector
-
-作用:主要用于 IoTDB(v1.2.0+)与 IoTDB(v1.2.0+)之间的数据传输。
-使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景。
-不保证接收端 apply 数据的顺序与发送端接受写入请求的顺序一致,但是保证数据发送的完整性(at-least-once)。
-
-限制:源端 IoTDB 与 目标端 IoTDB 版本都需要在 v1.2.0+。
-
-
-| key | value
| value 取值范围
| required or optional with default
|
-| --------------------------------- |
--------------------------------------------------------------------------- |
---------------------------------------------------------------------------- |
----------------------------------------------------- |
-| connector | iotdb-thrift-async-connector
| String: iotdb-thrift-async-connector
| required
|
-| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
| String
| optional: 与 connector.node-urls 任选其一填写 |
-| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
| Integer
| optional: 与 connector.node-urls 任选其一填写 |
-| connector.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url
| String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669',
'127.0.0.1:6667' | optional: 与 connector.ip:connector.port 任选其一填写 |
-| connector.batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS
| Boolean: true, false
| optional: true |
-| connector.batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) |
Integer |
optional: 1 |
-| connector.batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte)
| Long
| optional: 16 * 1024 * 1024 (16MiB) |
+```SQL
+create pipe A2B
+WITH EXTRACTOR (
+'extractor'= 'iotdb-extractor',
+'extractor.realtime.enable' = 'false',
+'extractor.realtime.mode'='hybrid',
+'extractor.history.start-time' = '2023.08.23T08:00:00+00:00',
+'extractor.history.end-time' = '2023.10.23T08:00:00+00:00')
+with connector (
+'connector'='iotdb-thrift-async-connector',
+'connector.node-urls'='xxxx:6668',
+'connector.batch.enable'='false')
+```
-> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
-#### iotdb-legacy-pipe-connector
+### 双向数据传输
-作用:主要用于 IoTDB(v1.2.0+)向更低版本的 IoTDB 传输数据,使用 v1.2.0 版本前的数据同步(Sync)协议。
-使用 Thrift RPC 框架传输数据。单线程 sync blocking IO 模型,传输性能较弱。
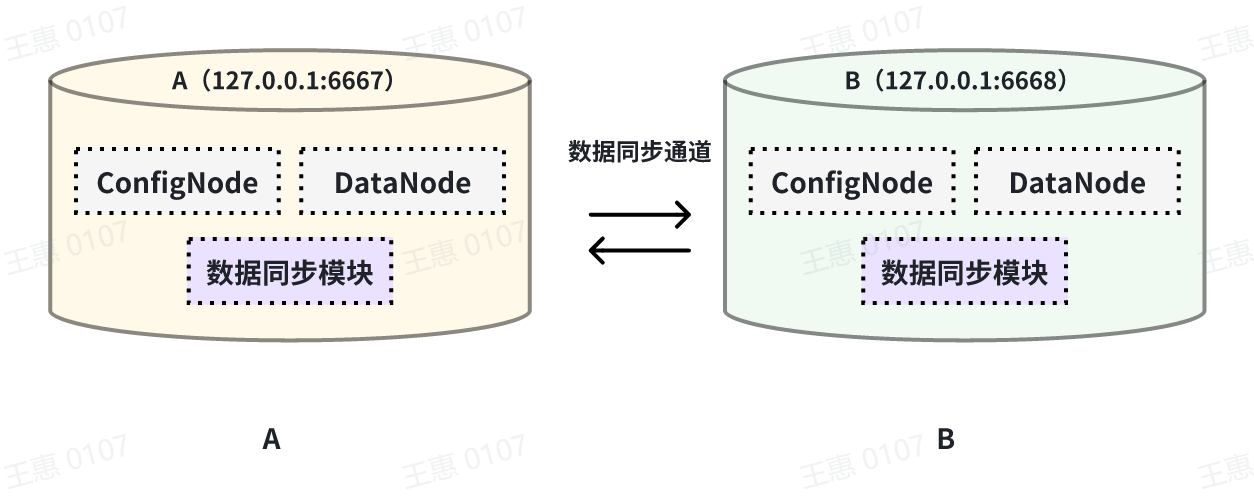
+本例子用来演示两个 IoTDB 之间互为双活的场景,数据链路如下图所示:
-限制:源端 IoTDB 版本需要在 v1.2.0+,目标端 IoTDB 版本可以是 v1.2.0+、v1.1.x(更低版本的 IoTDB
理论上也支持,但是未经测试)。
+
-注意:理论上 v1.2.0+ IoTDB 可作为 v1.2.0 版本前的任意版本的数据同步(Sync)接收端。
+在这个例子中,为了避免数据无限循环,需要将A和B上的参数`extractor.forwarding-pipe-requests` 均设置为
`false`,表示不转发从另一pipe传输而来的数据。同时将`'extractor.history.enable'` 设置为
`false`,表示不传输历史数据,即不同步创建该任务前的数据。
+
+详细语句如下:
+在 A IoTDB 上执行下列语句:
-| key | value
| value 取值范围 | required or optional with
default |
-| ------------------ |
--------------------------------------------------------------------- |
----------------------------------- | --------------------------------- |
-| connector | iotdb-legacy-pipe-connector
| String: iotdb-legacy-pipe-connector | required
|
-| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
| String | required |
-| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 port
| Integer | required |
-| connector.user | 目标端 IoTDB 的用户名,注意该用户需要支持数据写入、TsFile Load 的权限 | String
| optional: root |
-| connector.password | 目标端 IoTDB 的密码,注意该用户需要支持数据写入、TsFile Load 的权限 | String
| optional: root |
-| connector.version | 目标端 IoTDB 的版本,用于伪装自身实际版本,绕过目标端的版本一致性检查 | String
| optional: 1.1 |
+```Go
+create pipe AB
+with extractor (
+ 'extractor.history.enable' = 'false',
+ 'extractor.forwarding-pipe-requests' = 'false',
+with connector (
+ 'connector'='iotdb-thrift-connector',
+ 'connector.ip'='127.0.0.1',
+ 'connector.port'='6668'
+)
+```
-> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
+在 B IoTDB 上执行下列语句:
+
+```Go
+create pipe BA
+with extractor (
+ 'extractor.history.enable' = 'false',
+ 'extractor.forwarding-pipe-requests' = 'false',
+with connector (
+ 'connector'='iotdb-thrift-connector',
+ 'connector.ip'='127.0.0.1',
+ 'connector.port'='6667'
+)
+```
-#### iotdb-air-gap-connector
-作用:用于 IoTDB(v1.2.2+)向 IoTDB(v1.2.2+)跨单向数据网闸的数据同步。支持的网闸型号包括南瑞 Syskeeper 2000 等。
-该 Connector 使用 Java 自带的 Socket 实现数据传输,单线程 blocking IO 模型,其性能与
iotdb-thrift-sync-connector 相当。
-保证接收端 apply 数据的顺序与发送端接受写入请求的顺序一致。
+### 级联数据传输
-场景:例如,在电力系统的规范中
-> 1.I/II 区与 III 区之间的应用程序禁止采用 SQL 命令访问数据库和基于 B/S 方式的双向数据传输
->
-> 2.I/II 区与 III 区之间的数据通信,传输的启动端由内网发起,反向的应答报文不容许携带数据,应用层的应答报文最多为 1 个字节,并且 1
个字节为全 0 或者全 1 两种状态
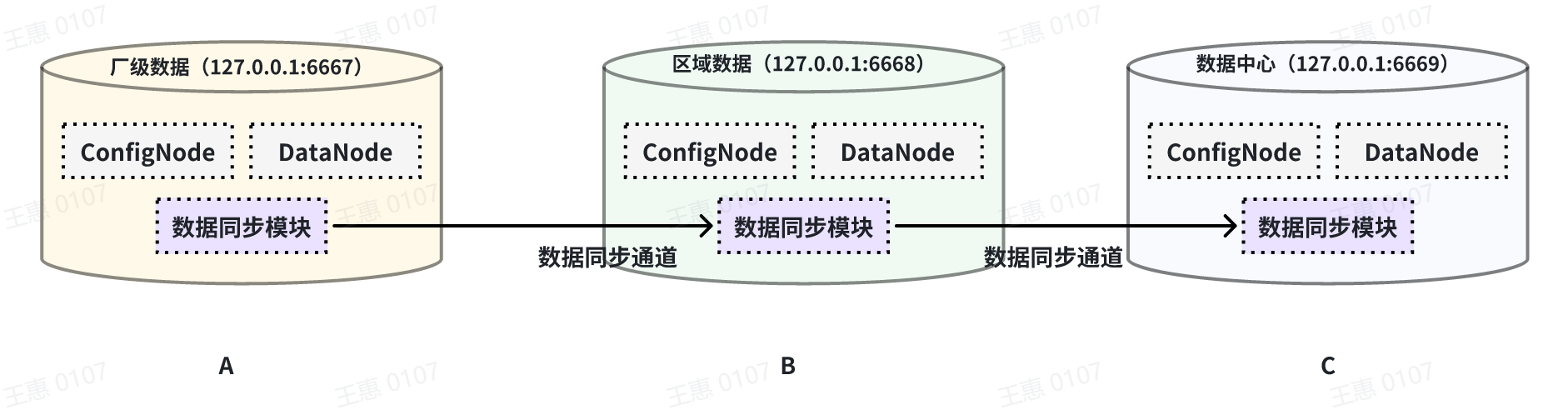
+本例子用来演示多个 IoTDB 之间级联传输数据的场景,数据由A集群同步至B集群,再同步至C集群,数据链路如下图所示:
-限制:
+
-1. 源端 IoTDB 与 目标端 IoTDB 版本都需要在 v1.2.2+。
-2. 单向数据网闸需要允许 TCP 请求跨越,且每一个请求可返回一个全 1 或全 0 的 byte。
-3. 目标端 IoTDB 需要在 iotdb-common.properties 内,配置
- a. pipe_air_gap_receiver_enabled=true
- b. pipe_air_gap_receiver_port 配置 receiver 的接收端口
+在这个例子中,为了将A集群的数据同步至C,在BC之间的pipe需要将 `extractor.forwarding-pipe-requests`
配置为`true`,详细语句如下:
+在A IoTDB上执行下列语句,将A中数据同步至B:
-| key | value
| value 取值范围
| required or optional with default
|
-| -------------------------------------- |
---------------------------------------------------------------- |
---------------------------------------------------------------------------- |
----------------------------------------------------- |
-| connector | iotdb-air-gap-connector
| String: iotdb-air-gap-connector
| required
|
-| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
| String
| optional: 与 connector.node-urls 任选其一填写 |
-| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务
port | Integer
| optional: 与 connector.node-urls 任选其一填写 |
-| connector.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的
url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669',
'127.0.0.1:6667' | optional: 与 connector.ip:connector.port 任选其一填写 |
-| connector.air-gap.handshake-timeout-ms | 发送端与接收端在首次尝试建立连接时握手请求的超时时长,单位:毫秒 |
Integer |
optional: 5000 |
+```Go
+create pipe AB
+with connector (
+ 'connector'='iotdb-thrift-connector',
+ 'connector.ip'='127.0.0.1',
+ 'connector.port'='6668'
+)
+```
-> 📌 请确保接收端已经创建了发送端的所有时间序列,或是开启了自动创建元数据,否则将会导致 pipe 运行失败。
+在B IoTDB上执行下列语句,将B中数据同步至C:
-#### do-nothing-connector
+```Go
+create pipe BC
+with extractor (
+ 'extractor.forwarding-pipe-requests' = 'true',
+with connector (
+ 'connector'='iotdb-thrift-connector',
+ 'connector.ip'='127.0.0.1',
+ 'connector.port'='6669'
+)
+```
-作用:不对 processor 传入的事件做任何的处理。
+### 跨网闸数据传输
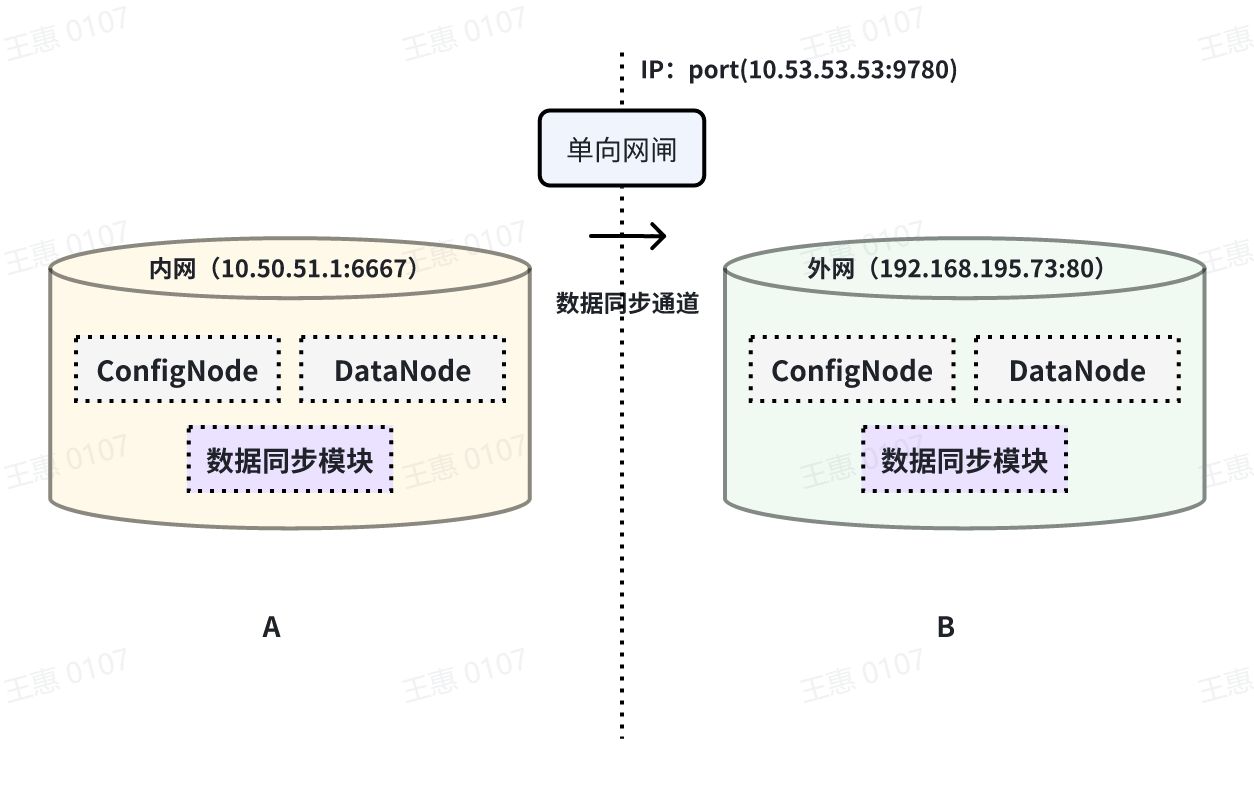
+本例子用来演示将一个 IoTDB 的数据,经过单向网闸,同步至另一个IoTDB的场景,数据链路如下图所示:
-| key | value | value 取值范围 | required or
optional with default |
-| --------- | -------------------- | ---------------------------- |
--------------------------------- |
-| connector | do-nothing-connector | String: do-nothing-connector | required
|
+
-## 权限管理
+在这个例子中,需要使用 connector 任务中的iotdb-air-gap-connector
插件(目前支持部分型号网闸,具体型号请联系天谋科技工作人员确认),配置网闸后,在 A IoTDB 上执行下列语句,其中ip和port填写网闸信息,详细语句如下:
-| 权限名称 | 描述 |
-| ----------- | -------------------- |
-| CREATE_PIPE | 注册任务。路径无关。 |
-| START_PIPE | 开启任务。路径无关。 |
-| STOP_PIPE | 停止任务。路径无关。 |
-| DROP_PIPE | 卸载任务。路径无关。 |
-| SHOW_PIPES | 查询任务。路径无关。 |
+```Go
+create pipe A2B
+with connector (
+ 'connector'='iotdb-air-gap-connector',
+ 'connector.ip'='10.53.53.53',
+ 'connector.port'='9780'
+)
+```
-## 配置参数
+## 参考:注意事项
-在 iotdb-common.properties 中:
+可通过修改 IoTDB 配置文件(iotdb-common.properties)以调整数据同步的参数,如同步数据存储目录等。完整配置如下:
-```Properties
+```Go
####################
### Pipe Configuration
####################
@@ -501,36 +333,57 @@ SHOW PIPEPLUGINS
# pipe_air_gap_receiver_port=9780
```
-## 功能特性
-
-### 最少一次语义保证 **at-least-once**
+## 参考:参数说明
-数据同步功能向外部系统传输数据时,提供 at-least-once 的传输语义。在大部分场景下,同步功能可提供 exactly-once
保证,即所有数据被恰好同步一次。
+### extractor 参数
-但是在以下场景中,可能存在部分数据被同步多次 **(断点续传)** 的情况:
+| key | value
| value 取值范围 | 是否必填 |默认取值|
+| ---------------------------------- |
------------------------------------------------ |
-------------------------------------- | -------- |------|
+| extractor | iotdb-extractor
| String: iotdb-extractor | 必填 | - |
+| extractor.pattern | 用于筛选时间序列的路径前缀 |
String: 任意的时间序列前缀 | 选填 | root |
+| extractor.history.enable | 是否同步历史数据
| Boolean: true, false | 选填 | true |
+| extractor.history.start-time | 同步历史数据的开始 event time,包含 start-time |
Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MIN_VALUE |
+| extractor.history.end-time | 同步历史数据的结束 event time,包含 end-time |
Long: [Long.MIN_VALUE, Long.MAX_VALUE] | 选填 | Long.MAX_VALUE |
+| extractor.realtime.enable | 是否同步实时数据
| Boolean: true, false | 选填 | true |
+| extractor.realtime.mode | 实时数据的抽取模式
| String: hybrid, log, file | 选填 | hybrid |
+| extractor.forwarding-pipe-requests | 是否转发由其他 Pipe (通常是数据同步)写入的数据 | Boolean:
true, false | 选填 | true |
-- 临时的网络故障:某次数据传输请求失败后,系统会进行重试发送,直至到达最大尝试次数
-- Pipe 插件逻辑实现异常:插件运行中抛出错误,系统会进行重试发送,直至到达最大尝试次数
-- 数据节点宕机、重启等导致的数据分区切主:分区变更完成后,受影响的数据会被重新传输
-- 集群不可用:集群可用后,受影响的数据会重新传输
+> 💎 **说明:历史数据与实时数据的差异**
+>
+> * **历史数据**:所有 arrival time < 创建 pipe 时当前系统时间的数据称为历史数据
+> * **实时数据**:所有 arrival time >= 创建 pipe 时当前系统时间的数据称为实时数据
+> * **全量数据**: 全量数据 = 历史数据 + 实时数据
-### 源端:数据写入与 Pipe 处理、发送数据异步解耦
-数据同步功能中,数据传输采用的是异步复制模式。
+> 💎 **说明:数据抽取模式hybrid, log和file的差异**
+>
+> -
**hybrid(推荐)**:该模式下,任务将优先对数据进行实时处理、发送,当数据产生积压时自动切换至批量发送模式,其特点是平衡了数据同步的时效性和吞吐量
+> - **log**:该模式下,任务将对数据进行实时处理、发送,其特点是高时效、低吞吐
+> - **file**:该模式下,任务将对数据进行批量(按底层数据文件)处理、发送,其特点是低时效、高吞吐
-数据同步与写入操作完全脱钩,不存在对写入关键路径的影响。该机制允许框架在保证持续数据同步的前提下,保持时序数据库的写入速度。
-### 源端:可自适应数据写入负载的数据传输策略
+### connector 参数
-支持根据写入负载,动态调整数据传输方式,同步默认使用 TsFile
文件与操作流动态混合传输(`'extractor.realtime.mode'='hybrid'`)。
+#### iotdb-thrift-connector
-在数据写入负载高时,优先选择 TsFile 传输的方式。TsFile 压缩比高,节省网络带宽。
+| key | value
| value 取值范围
| 是否必填 | 默认取值 |
+| --------------------------------- |
------------------------------------------------------------ |
------------------------------------------------------------ | -------- |
------------------------------------------- |
+| connector | iotdb-thrift-connector 或
iotdb-thrift-sync-connector | String: iotdb-thrift-connector 或
iotdb-thrift-sync-connector | 必填 |
|
+| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务
ip(请注意同步任务不支持向自身服务进行转发) | String
| 选填 | 与 connector.node-urls 任选其一填写 |
+| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务
port(请注意同步任务不支持向自身服务进行转发) | Integer
| 选填 | 与 connector.node-urls 任选其一填写 |
+| connector.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的
url(请注意同步任务不支持向自身服务进行转发) |
String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 选填
| 与 connector.ip:connector.port 任选其一填写 |
+| connector.batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS |
Boolean: true, false | 选填 | true
|
+| connector.batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) |
Integer | 选填 | 1
|
+| connector.batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte)
| Long
| 选填
-在数据写入负载低时,优先选择操作流同步传输的方式。操作流传输实时性高。
-### 源端:高可用集群部署时,Pipe 服务高可用
-当发送端 IoTDB 为高可用集群部署模式时,数据同步服务也将是高可用的。
数据同步框架将监控每个数据节点的数据同步进度,并定期做轻量级的分布式一致性快照以保存同步状态。
+#### iotdb-air-gap-connector
-- 当发送端集群某数据节点宕机时,数据同步框架可以利用一致性快照以及保存在副本上的数据快速恢复同步,以此实现数据同步服务的高可用。
-- 当发送端集群整体宕机并重启时,数据同步框架也能使用快照恢复同步服务。
+| key | value
| value 取值范围
| 是否必填 | 默认取值 |
+| -------------------------------------- |
------------------------------------------------------------ |
------------------------------------------------------------ | -------- |
------------------------------------------- |
+| connector | iotdb-air-gap-connector
| String: iotdb-air-gap-connector
| 必填 | |
+| connector.ip | 目标端 IoTDB 其中一个 DataNode 节点的数据服务 ip
| String | 选填
| 与 connector.node-urls 任选其一填写 |
+| connector.port | 目标端 IoTDB 其中一个 DataNode 节点的数据服务
port | Integer |
选填 | 与 connector.node-urls 任选其一填写 |
+| connector.node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的
url | String。例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669',
'127.0.0.1:6667' | 选填 | 与 connector.ip:connector.port 任选其一填写 |
+| connector.air-gap.handshake-timeout-ms | 发送端与接收端在首次尝试建立连接时握手请求的超时时长,单位:毫秒 |
Integer | 选填 | 5000
|
\ No newline at end of file
diff --git a/src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
b/src/zh/UserGuide/V1.2.x/User-Manual/Stage_Data-Sync_timecho.md
similarity index 100%
copy from src/zh/UserGuide/V1.2.x/User-Manual/Data-Sync_timecho.md
copy to src/zh/UserGuide/V1.2.x/User-Manual/Stage_Data-Sync_timecho.md
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}