This is an automated email from the ASF dual-hosted git repository.
qiaojialin pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/iotdb-docs.git
The following commit(s) were added to refs/heads/main by this push:
new e9261a4 fix the doc bug of the lastest English version (#229)
e9261a4 is described below
commit e9261a4aa2ed908d3b79dfc3fa58847bf4d23941
Author: wanghui42 <[email protected]>
AuthorDate: Fri May 17 16:00:53 2024 +0800
fix the doc bug of the lastest English version (#229)
---
.../Basic-Concept/Cluster-data-partitioning.md | 2 +-
.../Basic-Concept/Encoding-and-Compression.md | 2 +-
.../Deployment-and-Maintenance/Deployment-Guide.md | 18 +++++------
.../Deployment-Guide_timecho.md | 36 +++++++++++-----------
.../Monitoring-Board-Install-and-Deploy.md | 6 ++--
.../Master/FAQ/Frequently-asked-questions.md | 16 +++++-----
src/UserGuide/Master/QuickStart/QuickStart.md | 10 +++---
src/UserGuide/Master/Tools-System/Benchmark.md | 2 +-
src/UserGuide/Master/User-Manual/Syntax-Rule.md | 6 ++--
.../Basic-Concept/Cluster-data-partitioning.md | 2 +-
.../Basic-Concept/Encoding-and-Compression.md | 2 +-
.../Deployment-and-Maintenance/Deployment-Guide.md | 18 +++++------
.../Deployment-Guide_timecho.md | 36 +++++++++++-----------
.../Monitoring-Board-Install-and-Deploy.md | 6 ++--
.../latest/FAQ/Frequently-asked-questions.md | 16 +++++-----
src/UserGuide/latest/QuickStart/QuickStart.md | 10 +++---
src/UserGuide/latest/Tools-System/Benchmark.md | 2 +-
src/UserGuide/latest/User-Manual/Syntax-Rule.md | 6 ++--
.../Basic-Concept/Encoding-and-Compression.md | 2 +-
.../Master/FAQ/Frequently-asked-questions.md | 14 ++++-----
src/zh/UserGuide/Master/QuickStart/QuickStart.md | 10 +++---
src/zh/UserGuide/Master/Tools-System/Benchmark.md | 2 +-
src/zh/UserGuide/Master/User-Manual/Syntax-Rule.md | 6 ++--
.../Basic-Concept/Encoding-and-Compression.md | 2 +-
.../latest/FAQ/Frequently-asked-questions.md | 22 ++++++-------
src/zh/UserGuide/latest/QuickStart/QuickStart.md | 10 +++---
src/zh/UserGuide/latest/Tools-System/Benchmark.md | 2 +-
src/zh/UserGuide/latest/User-Manual/Syntax-Rule.md | 6 ++--
28 files changed, 136 insertions(+), 136 deletions(-)
diff --git a/src/UserGuide/Master/Basic-Concept/Cluster-data-partitioning.md
b/src/UserGuide/Master/Basic-Concept/Cluster-data-partitioning.md
index 838f379..030f86e 100644
--- a/src/UserGuide/Master/Basic-Concept/Cluster-data-partitioning.md
+++ b/src/UserGuide/Master/Basic-Concept/Cluster-data-partitioning.md
@@ -23,7 +23,7 @@
IoTDB manages metadata and data based on data partitions (DataRegion),
dividing the data from both the sequence and time dimensions.
-<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto;
margin-right:auto; display:block;"
src="https://alioss.timecho.com/docs/img/%E5%88%86%E5%8C%BA%E6%A7%BD%E4%B8%8E%E6%95%B0%E6%8D%AE%E5%88%86%E5%8C%BA.png?raw=true";>
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto;
margin-right:auto; display:block;"
src="https://alioss.timecho.com/upload/data-region.jpg";>
## Partition Slots
diff --git a/src/UserGuide/Master/Basic-Concept/Encoding-and-Compression.md
b/src/UserGuide/Master/Basic-Concept/Encoding-and-Compression.md
index 36a5b6e..57d55a8 100644
--- a/src/UserGuide/Master/Basic-Concept/Encoding-and-Compression.md
+++ b/src/UserGuide/Master/Basic-Concept/Encoding-and-Compression.md
@@ -120,7 +120,7 @@ The specified syntax for compression is detailed in [Create
Timeseries Statement
### Compression Ratio Statistics
-Compression ratio statistics file:
data/system/compression_ratio/Ratio-{ratio_sum}-{memtable_flush_time}
+Compression ratio statistics file: data/datanode/system/compression_ratio
* ratio_sum: sum of memtable compression ratios
* memtable_flush_time: memtable flush times
diff --git
a/src/UserGuide/Master/Deployment-and-Maintenance/Deployment-Guide.md
b/src/UserGuide/Master/Deployment-and-Maintenance/Deployment-Guide.md
index 5560179..89c95a4 100644
--- a/src/UserGuide/Master/Deployment-and-Maintenance/Deployment-Guide.md
+++ b/src/UserGuide/Master/Deployment-and-Maintenance/Deployment-Guide.md
@@ -269,7 +269,7 @@ You can either download the binary release files (see Chap
3.1) or compile with
1. Open our website [Download Page](https://iotdb.apache.org/Download/).
2. Download the binary distribution.
-3. Decompress to get the apache-iotdb-1.0.0-all-bin directory.
+3. Decompress to get the apache-iotdb-1.3.x-all-bin directory.
#### Compile with source code
@@ -279,14 +279,14 @@ You can either download the binary release files (see
Chap 3.1) or compile with
```
git clone https://github.com/apache/iotdb.git
-git checkout v1.0.0
+git checkout v1.3.x
```
**Website**
1. Open our website [Download Page](https://iotdb.apache.org/Download/).
2. Download the source code.
-3. Decompress to get the apache-iotdb-1.0.0 directory.
+3. Decompress to get the apache-iotdb-1.3.x directory.
##### Compile source code
@@ -297,7 +297,7 @@ mvn clean package -pl distribution -am -DskipTests
```
Then you will get the binary distribution under
-**distribution/target/apache-iotdb-1.0.0-SNAPSHOT-all-bin/apache-iotdb-1.0.0-SNAPSHOT-all-bin**.
+**distribution/target/apache-iotdb-1.3.x-SNAPSHOT-all-bin/apache-iotdb-1.3.x-SNAPSHOT-all-bin**.
### Binary Distribution Content
@@ -320,7 +320,7 @@ Please deploy the files to all servers of your target
cluster.
A best practice is deploying the files into the same directory in all servers.
If you want to try the cluster mode on one server, please read
-[Cluster Quick
Start](https://iotdb.apache.org/UserGuide/Master/QuickStart/ClusterQuickStart.html).
+[Cluster Quick Start](../QuickStart/ClusterQuickStart.md).
#### Cluster Configuration
@@ -439,7 +439,7 @@ nohup bash ./sbin/start-confignode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of ConfigNode, see the
-[ConfigNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/ConfigNode-Config-Manual.html).
+[ConfigNode Configurations](../Reference/ConfigNode-Config-Manual.md).
##### Add more ConfigNodes (Optional)
@@ -484,7 +484,7 @@ nohup bash ./sbin/start-confignode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of ConfigNode, see the
-[ConfigNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/ConfigNode-Config-Manual.html).
+[ConfigNode Configurations](../Reference/ConfigNode-Config-Manual.md).
##### Start DataNode
@@ -526,7 +526,7 @@ nohup bash ./sbin/start-datanode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of DataNode, see the
-[DataNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/DataNode-Config-Manual.html).
+[DataNode Configurations](../Reference/DataNode-Config-Manual.md).
**Notice: The cluster can provide services only if the number of its DataNodes
is no less than the number of replicas(max{schema\_replication\_factor,
data\_replication\_factor}).**
@@ -671,4 +671,4 @@ Run the remove-datanode script on an active DataNode:
### FAQ
-See
[FAQ](https://iotdb.apache.org/UserGuide/Master/FAQ/FAQ-for-cluster-setup.html).
\ No newline at end of file
+See [FAQ](../FAQ/Frequently-asked-questions.md).
\ No newline at end of file
diff --git
a/src/UserGuide/Master/Deployment-and-Maintenance/Deployment-Guide_timecho.md
b/src/UserGuide/Master/Deployment-and-Maintenance/Deployment-Guide_timecho.md
index cde1133..3bfc0cf 100644
---
a/src/UserGuide/Master/Deployment-and-Maintenance/Deployment-Guide_timecho.md
+++
b/src/UserGuide/Master/Deployment-and-Maintenance/Deployment-Guide_timecho.md
@@ -124,8 +124,8 @@ iotdbctl cluster check example
* `global` is a general configuration that mainly configures machine username
and password, IoTDB local installation files, Jdk configuration, etc. A
`default_cluster.yaml` sample data is provided in the `iotdbctl/config`
directory,
Users can copy and modify it to their own cluster name and refer to the
instructions inside to configure the IoTDB cluster. In the
`default_cluster.yaml` sample, all uncommented items are required, and those
that have been commented are non-required.
-例如要执行`default_cluster.yaml`检查命令则需要执行命令`iotdbctl cluster check
default_cluster`即可,
-更多详细命令请参考下面命令列表。
+For example, to execute the `default_cluster.yaml` check command you need to
execute the command `iotdbctl cluster check default_cluster`.
+See further details in the following list of commands.
| parameter name | parameter describe
|
required |
@@ -278,7 +278,7 @@ iotdbctl cluster scalein default_cluster
* Configure the server's `user`, `passwod` or `pkey`, `ssh_port`
* Modify the IoTDB deployment path in config/xxx.yaml, `deploy_dir` (IoTDB
deployment directory), `iotdb_dir_name` (IoTDB decompression directory name,
the default is iotdb)
- For example, if the full path of IoTDB deployment is
`/home/data/apache-iotdb-1.1.1`, you need to modify the yaml files
`deploy_dir:/home/data/` and `iotdb_dir_name:apache-iotdb-1.1.1`
+ For example, if the full path of IoTDB deployment is
`/home/data/apache-iotdb-1.1.1`, you need to modify the yaml files
`deploy_dir:/home/data/` and `iotdb_dir_name:apache-iotdb-1.3.x`
* If the server is not using java_home, modify `jdk_deploy_dir` (jdk
deployment directory) and `jdk_dir_name` (the directory name after jdk
decompression, the default is jdk_iotdb). If java_home is used, there is no
need to modify the configuration.
For example, the full path of jdk deployment is `/home/data/jdk_1.8.2`, you
need to modify the yaml files `jdk_deploy_dir:/home/data/`,
`jdk_dir_name:jdk_1.8.2`
* Configure `cn_internal_address`, `dn_internal_address`
@@ -754,13 +754,13 @@ In the cluster deployment tool installation directory
config/example, there are
### Get the Installation Package
-You can either download the binary release files (see Chap 3.1) or compile
with source code (see Chap 3.2).
+You can either download the binary release files or compile with source code.
#### Download the binary distribution
1. Open our website [Download Page](https://iotdb.apache.org/Download/).
2. Download the binary distribution.
-3. Decompress to get the apache-iotdb-1.0.0-all-bin directory.
+3. Decompress to get the apache-iotdb-1.3.x-all-bin directory.
#### Compile with source code
@@ -770,14 +770,14 @@ You can either download the binary release files (see
Chap 3.1) or compile with
```
git clone https://github.com/apache/iotdb.git
-git checkout v1.0.0
+git checkout v1.3.x
```
**Website**
1. Open our website [Download Page](https://iotdb.apache.org/Download/).
2. Download the source code.
-3. Decompress to get the apache-iotdb-1.0.0 directory.
+3. Decompress to get the apache-iotdb-1.3.x directory.
##### Compile source code
@@ -788,7 +788,7 @@ mvn clean package -pl distribution -am -DskipTests
```
Then you will get the binary distribution under
-**distribution/target/apache-iotdb-1.0.0-SNAPSHOT-all-bin/apache-iotdb-1.0.0-SNAPSHOT-all-bin**.
+**distribution/target/apache-iotdb-1.3.x-SNAPSHOT-all-bin/apache-iotdb-1.3.x-SNAPSHOT-all-bin**.
### Binary Distribution Content
@@ -811,7 +811,7 @@ Please deploy the files to all servers of your target
cluster.
A best practice is deploying the files into the same directory in all servers.
If you want to try the cluster mode on one server, please read
-[Cluster Quick
Start](https://iotdb.apache.org/UserGuide/Master/QuickStart/ClusterQuickStart.html).
+[Cluster Quick Start](../QuickStart/ClusterQuickStart.md).
#### Cluster Configuration
@@ -819,11 +819,11 @@ We need to modify the configurations on each server.
Therefore, login each server and switch the working directory to
`apache-iotdb-1.0.0-SNAPSHOT-all-bin`.
The configuration files are stored in the `./conf` directory.
-For all ConfigNode servers, we need to modify the common configuration (see
Chap 5.2.1)
-and ConfigNode configuration (see Chap 5.2.2).
+For all ConfigNode servers, we need to modify the common configuration
+and ConfigNode configuration.
-For all DataNode servers, we need to modify the common configuration (see Chap
5.2.1)
-and DataNode configuration (see Chap 5.2.3).
+For all DataNode servers, we need to modify the common configuration
+and DataNode configuration.
##### Common configuration
@@ -930,7 +930,7 @@ nohup bash ./sbin/start-confignode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of ConfigNode, see the
-[ConfigNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/ConfigNode-Config-Manual.html).
+[ConfigNode Configurations](../Reference/ConfigNode-Config-Manual.md).
##### Add more ConfigNodes (Optional)
@@ -975,7 +975,7 @@ nohup bash ./sbin/start-confignode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of ConfigNode, see the
-[ConfigNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/ConfigNode-Config-Manual.html).
+[ConfigNode Configurations](../Reference/ConfigNode-Config-Manual.md).
##### Start DataNode
@@ -1017,7 +1017,7 @@ nohup bash ./sbin/start-datanode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of DataNode, see the
-[DataNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/DataNode-Config-Manual.html).
+[DataNode Configurations](../Reference/DataNode-Config-Manual.md).
**Notice: The cluster can provide services only if the number of its DataNodes
is no less than the number of replicas(max{schema\_replication\_factor,
data\_replication\_factor}).**
@@ -1034,7 +1034,7 @@ If the cluster is in local environment, you can directly
run the Cli startup scr
```
If you want to use the Cli to connect to a cluster in the production
environment,
-Please read the [Cli
manual](https://iotdb.apache.org/UserGuide/Master/QuickStart/Command-Line-Interface.html).
+Please read the [Cli manual](../Tools-System/CLI.md).
#### Verify Cluster
@@ -1162,7 +1162,7 @@ Run the remove-datanode script on an active DataNode:
### FAQ
-See
[FAQ](https://iotdb.apache.org/UserGuide/Master/FAQ/FAQ-for-cluster-setup.html).
+See [FAQ](../FAQ/Frequently-asked-questions.md).
## AINode deployment
diff --git
a/src/UserGuide/Master/Deployment-and-Maintenance/Monitoring-Board-Install-and-Deploy.md
b/src/UserGuide/Master/Deployment-and-Maintenance/Monitoring-Board-Install-and-Deploy.md
index b5e8f86..7dfe97f 100644
---
a/src/UserGuide/Master/Deployment-and-Maintenance/Monitoring-Board-Install-and-Deploy.md
+++
b/src/UserGuide/Master/Deployment-and-Maintenance/Monitoring-Board-Install-and-Deploy.md
@@ -150,11 +150,11 @@ cd grafana-*
3. Enter http://localhost:3000 in your browser to access Grafana, the default
initial username and password are both admin.
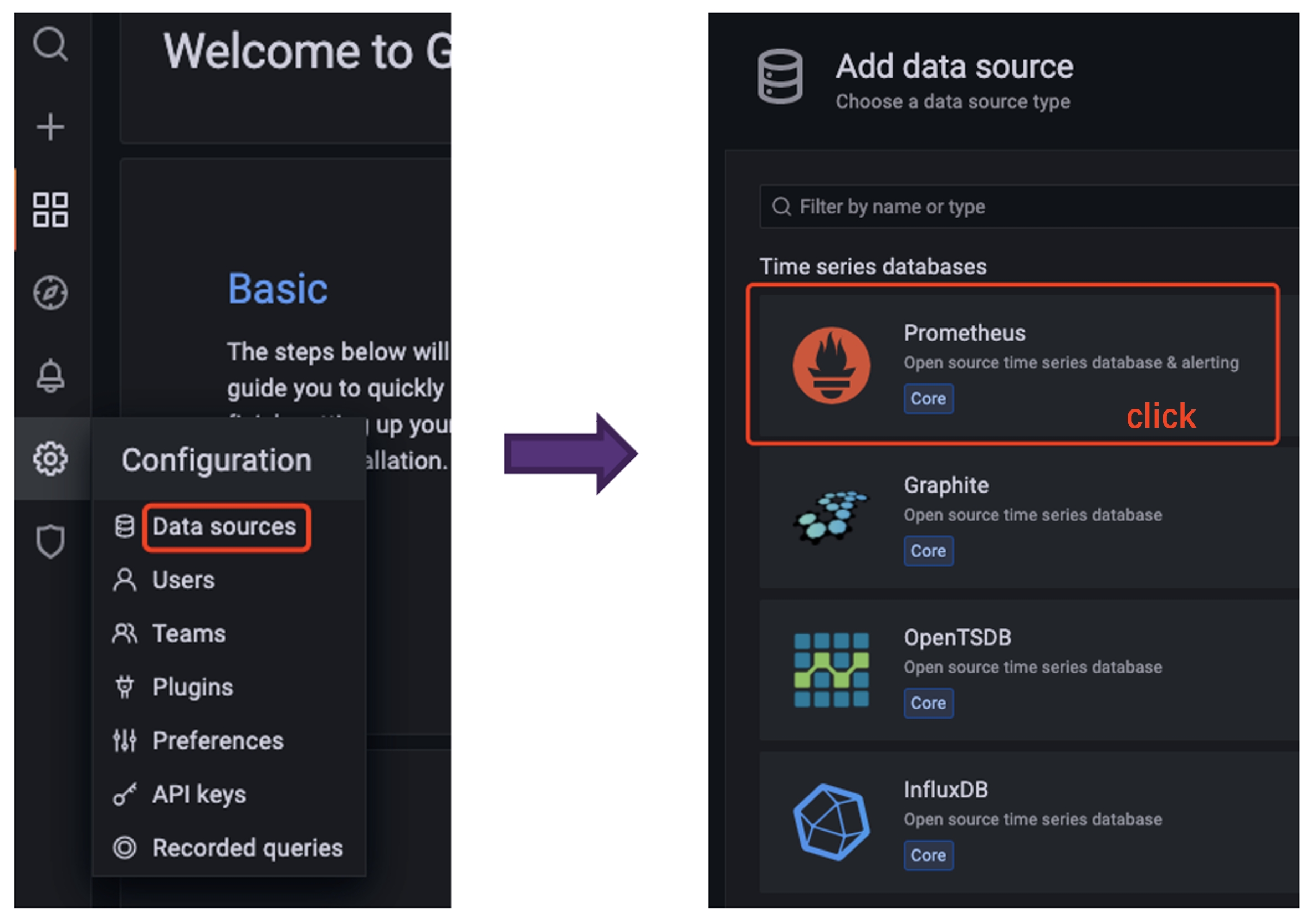
4. First we configure the Data Source in Configuration to be Prometheus.
-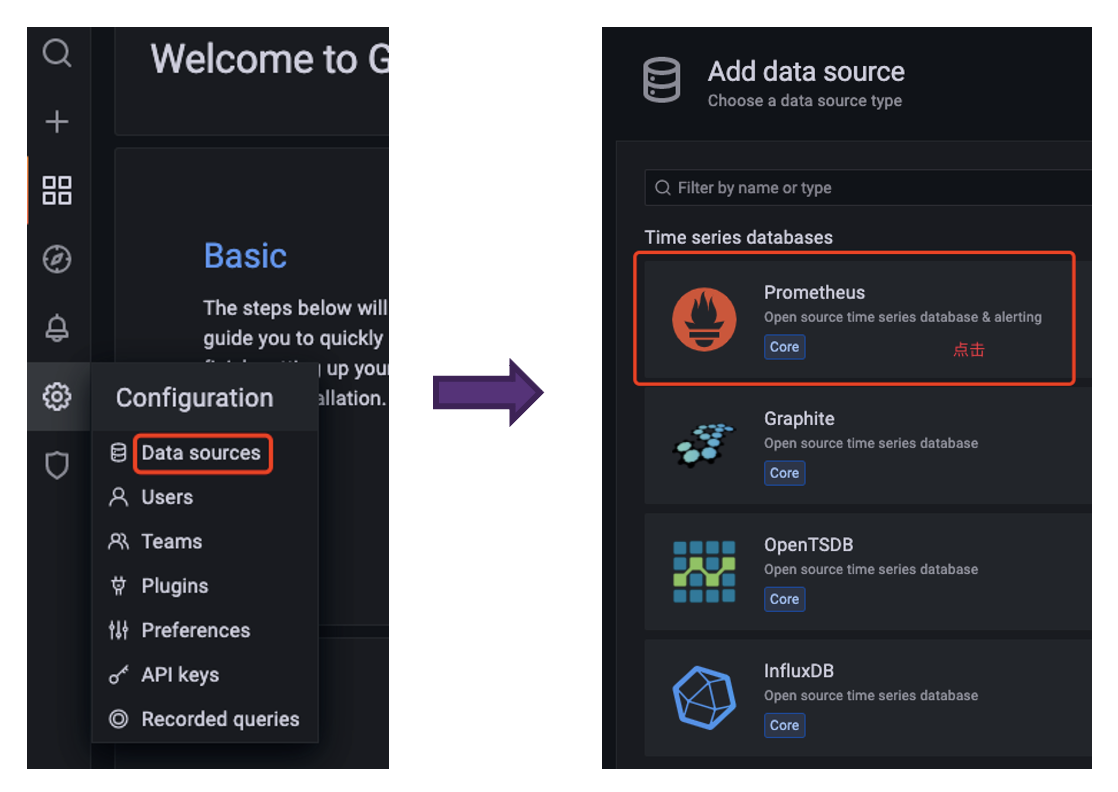
+
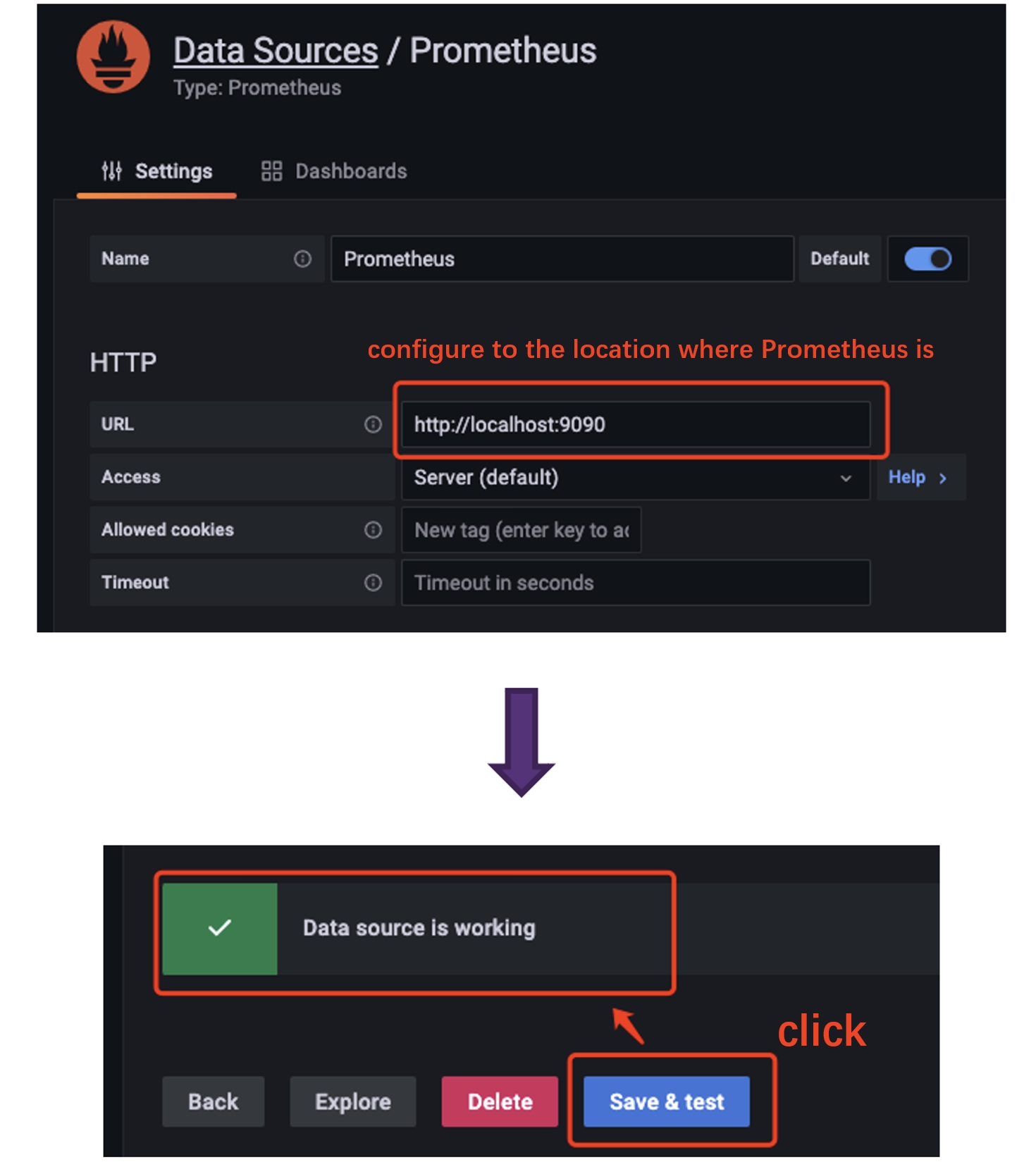
5. When configuring the Data Source, pay attention to the URL where Prometheus
is located, and click Save & Test after configuration, the Data source is
working prompt appears, then the configuration is successful.
-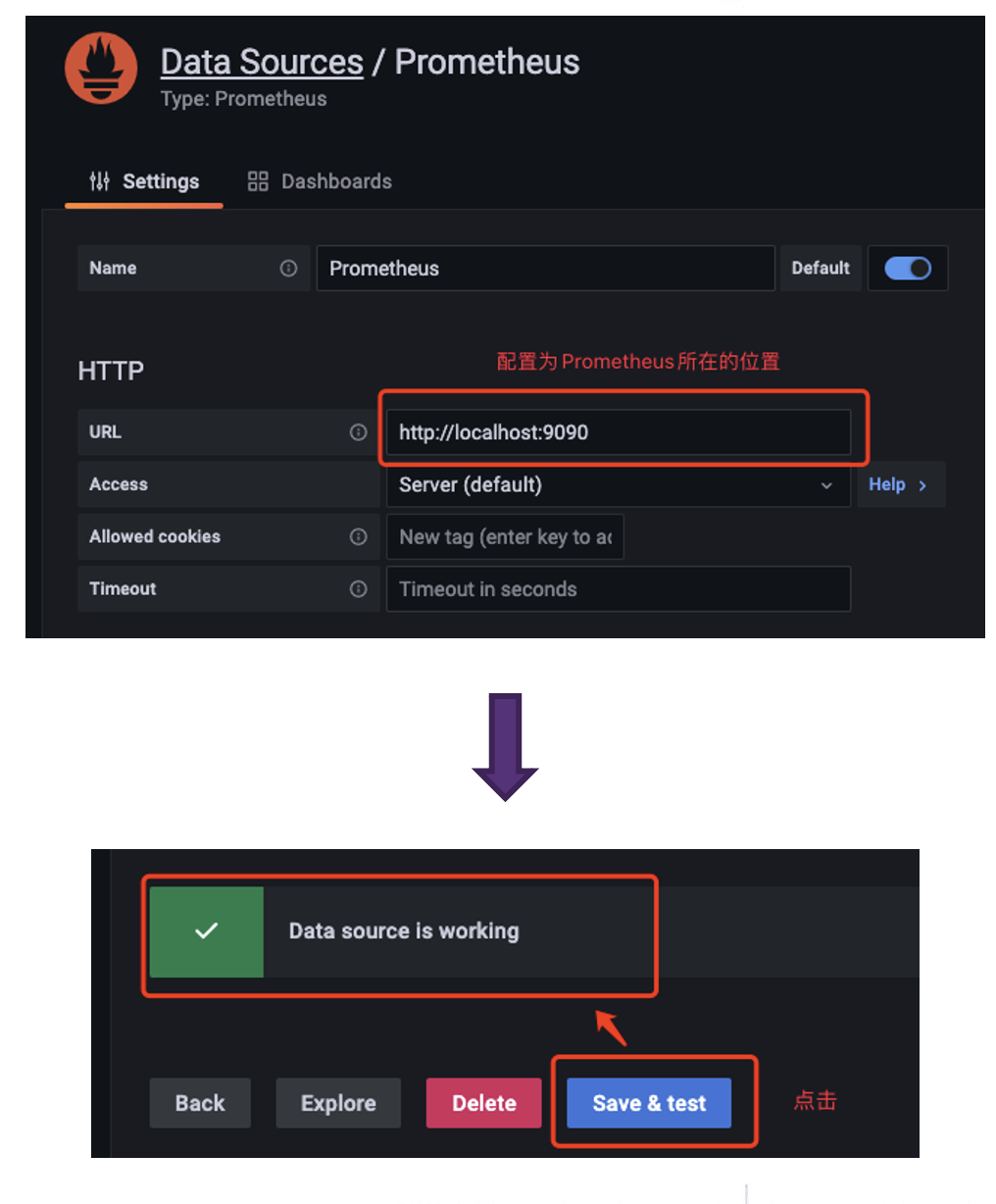
+
### 1.3.2 Step2:Import the IoTDB Dashboards
@@ -200,7 +200,7 @@ cd grafana-*
2. After that, you can visualize the monitoring-related data in the panel
according to your needs (all relevant monitoring metrics can be filtered by
selecting confignode/datanode in the job first).
-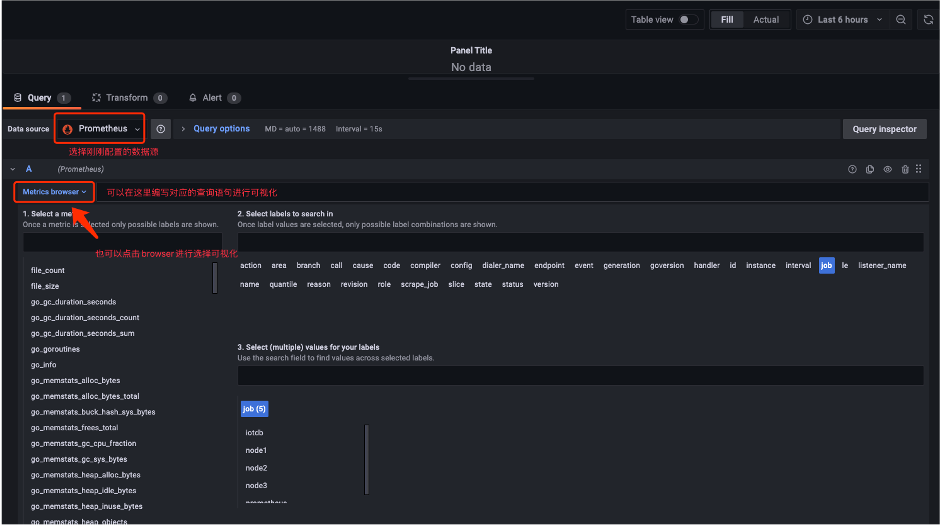
+
3. Once the visualisation of the monitoring metrics selected for attention is
complete, we get a panel like this:
diff --git a/src/UserGuide/Master/FAQ/Frequently-asked-questions.md
b/src/UserGuide/Master/FAQ/Frequently-asked-questions.md
index 5e4b2d9..7352976 100644
--- a/src/UserGuide/Master/FAQ/Frequently-asked-questions.md
+++ b/src/UserGuide/Master/FAQ/Frequently-asked-questions.md
@@ -116,7 +116,7 @@ If you are using Linux, you can use the following shell
command:
### 5. Can I use Hadoop and Spark to read TsFile in IoTDB?
-Yes. IoTDB has intense integration with Open Source Ecosystem. IoTDB supports
[Hadoop](https://github.com/apache/iotdb/tree/master/iotdb-connector/hadoop),
[Spark](https://github.com/apache/iotdb/tree/master/iotdb-connector/spark-iotdb-connector)
and
[Grafana](https://github.com/apache/iotdb/tree/master/iotdb-connector/grafana-connector)
visualization tool.
+Yes. IoTDB has intense integration with Open Source Ecosystem. IoTDB supports
[Hadoop](https://github.com/apache/iotdb-extras/tree/master/connectors/hadoop),
[Spark](https://github.com/apache/iotdb-extras/tree/master/connectors/spark-iotdb-connector)
and
[Grafana](https://github.com/apache/iotdb-extras/tree/master/connectors/grafana-connector)
visualization tool.
### 6. How does IoTDB handle duplicate points?
@@ -202,7 +202,7 @@ not affect normal operations. We will fix this message in
the incoming releases.
#### 4. Failed to remove DataNode, how to find the reason?
-- Examine whether the parameter of remove-datanode.sh is correct, only
rpcIp:rpcPort and dataNodeId are correct parameter.
+- Examine whether the parameter of `remove-datanode.sh` is correct, only
rpcIp:rpcPort and dataNodeId are correct parameter.
- Only when the number of available DataNodes in the cluster is greater than
max(schema_replication_factor, data_replication_factor), removing operation can
be executed.
- Removing DataNode will migrate the data from the removing DataNode to other
alive DataNodes. Data migration is based on Region, if some regions are
migrated failed, the removing DataNode will always in the status of `Removing`.
- If the DataNode is in the status of `Removing`, the regions in the removing
DataNode will also in the status of `Removing` or `Unknown`, which are
unavailable status. Besides, the removing DataNode will not receive new write
requests from client.
@@ -226,13 +226,13 @@ not affect normal operations. We will fix this message in
the incoming releases.
#### 1. How to restart any ConfigNode in the cluster?
-- First step: stop the process by stop-confignode.sh or kill PID of ConfigNode.
-- Second step: execute start-confignode.sh to restart ConfigNode.
+- First step: stop the process by `stop-confignode.sh` or kill PID of
ConfigNode.
+- Second step: execute `start-confignode.sh` to restart ConfigNode.
#### 2. How to restart any DataNode in the cluster?
-- First step: stop the process by stop-datanode.sh or kill PID of DataNode.
-- Second step: execute start-datanode.sh to restart DataNode.
+- First step: stop the process by `stop-datanode.sh` or kill PID of DataNode.
+- Second step: execute `start-datanode.sh` to restart DataNode.
#### 3. If it's possible to restart ConfigNode using the old data directory
when it's removed?
@@ -242,7 +242,7 @@ not affect normal operations. We will fix this message in
the incoming releases.
- Can't. The running result will be "Reject DataNode restart. Because there
are no corresponding DataNode(whose nodeId=xx) in the cluster. Possible
solutions are as follows:...".
-#### 5. Can we execute start-confignode.sh/start-datanode.sh successfully when
delete the data directory of given ConfigNode/DataNode without killing the PID?
+#### 5. Can we execute `start-confignode.sh`/`start-datanode.sh` successfully
when delete the data directory of given ConfigNode/DataNode without killing the
PID?
- Can't. The running result will be "The port is already occupied".
@@ -255,7 +255,7 @@ not affect normal operations. We will fix this message in
the incoming releases.
#### 2. How to fix one DataNode when the disk file is broken?
-- We can use remove-datanode.sh to fix it. Remove-datanode will migrate the
data in the removing DataNode to other alive DataNodes.
+- We can use `remove-datanode.sh` to fix it. Remove-datanode will migrate the
data in the removing DataNode to other alive DataNodes.
- IoTDB will publish Node-Fix tools in the next version.
#### 3. How to decrease the memory usage of ConfigNode/DataNode?
diff --git a/src/UserGuide/Master/QuickStart/QuickStart.md
b/src/UserGuide/Master/QuickStart/QuickStart.md
index 24606d1..7cfcc52 100644
--- a/src/UserGuide/Master/QuickStart/QuickStart.md
+++ b/src/UserGuide/Master/QuickStart/QuickStart.md
@@ -111,11 +111,11 @@ We can also use SHOW DATABASES to check created databases:
```
IoTDB> SHOW DATABASES
-+-----------------------------------+
-| Database|
-+-----------------------------------+
-| root.ln|
-+-----------------------------------+
++---------------+----+-----------------------+---------------------+---------------------+
+| Database|
TTL|SchemaReplicationFactor|DataReplicationFactor|TimePartitionInterval|
++---------------+----+-----------------------+---------------------+---------------------+
+| root.ln|null| 1| 1|
604800000|
++---------------+----+-----------------------+---------------------+---------------------+
Database number = 1
```
diff --git a/src/UserGuide/Master/Tools-System/Benchmark.md
b/src/UserGuide/Master/Tools-System/Benchmark.md
index ce889b8..2bd6c46 100644
--- a/src/UserGuide/Master/Tools-System/Benchmark.md
+++ b/src/UserGuide/Master/Tools-System/Benchmark.md
@@ -333,4 +333,4 @@ Table 2-5 Configuration parameter information
| STRING_LENGTH | 10
| String length |
|
| DOUBLE_LENGTH | 2
| Decimal places |
|
| Three machines simulate data writing of 300 devices |
BENCHMARK_CLUSTER | true
| Enable multi-benchmark mode |
-| BENCHMARK_INDEX | 0, 1, 3
| Take the writing parameters in the previous chapter as an
example: No. 0 is responsible for writing data of device numbers 0-99; No. 1 is
responsible for writing data of device numbers 100-199; No. 2 is responsible
for writing data of device numbers 200-299. |
|
\ No newline at end of file
+| BENCHMARK_INDEX | 0, 1, 3
| Take the writing parameters in the [write
test](./Benchmark.md#write-test) as an example: No. 0 is responsible for
writing data of device numbers 0-99; No. 1 is responsible for writing data of
device numbers 100-199; No. 2 is responsible for writing data of device numbers
200-299. | |
\ No newline at end of file
diff --git a/src/UserGuide/Master/User-Manual/Syntax-Rule.md
b/src/UserGuide/Master/User-Manual/Syntax-Rule.md
index 83ec978..30ac234 100644
--- a/src/UserGuide/Master/User-Manual/Syntax-Rule.md
+++ b/src/UserGuide/Master/User-Manual/Syntax-Rule.md
@@ -188,11 +188,11 @@ Below are basic constraints of identifiers, specific
identifiers may have other
```sql
# create template t1't"t
-create schema template `t1't"t`
+create device template `t1't"t`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
# create template t1`t
-create schema template `t1``t`
+create device template `t1``t`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
```
@@ -225,7 +225,7 @@ Examples of case in which quoted identifier is used :
```sql
# create a template named 111, 111 is a real number.
- create schema template `111`
+ create device template `111`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
```
diff --git a/src/UserGuide/latest/Basic-Concept/Cluster-data-partitioning.md
b/src/UserGuide/latest/Basic-Concept/Cluster-data-partitioning.md
index 838f379..030f86e 100644
--- a/src/UserGuide/latest/Basic-Concept/Cluster-data-partitioning.md
+++ b/src/UserGuide/latest/Basic-Concept/Cluster-data-partitioning.md
@@ -23,7 +23,7 @@
IoTDB manages metadata and data based on data partitions (DataRegion),
dividing the data from both the sequence and time dimensions.
-<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto;
margin-right:auto; display:block;"
src="https://alioss.timecho.com/docs/img/%E5%88%86%E5%8C%BA%E6%A7%BD%E4%B8%8E%E6%95%B0%E6%8D%AE%E5%88%86%E5%8C%BA.png?raw=true";>
+<img style="width:100%; max-width:800px; max-height:600px; margin-left:auto;
margin-right:auto; display:block;"
src="https://alioss.timecho.com/upload/data-region.jpg";>
## Partition Slots
diff --git a/src/UserGuide/latest/Basic-Concept/Encoding-and-Compression.md
b/src/UserGuide/latest/Basic-Concept/Encoding-and-Compression.md
index 36a5b6e..57d55a8 100644
--- a/src/UserGuide/latest/Basic-Concept/Encoding-and-Compression.md
+++ b/src/UserGuide/latest/Basic-Concept/Encoding-and-Compression.md
@@ -120,7 +120,7 @@ The specified syntax for compression is detailed in [Create
Timeseries Statement
### Compression Ratio Statistics
-Compression ratio statistics file:
data/system/compression_ratio/Ratio-{ratio_sum}-{memtable_flush_time}
+Compression ratio statistics file: data/datanode/system/compression_ratio
* ratio_sum: sum of memtable compression ratios
* memtable_flush_time: memtable flush times
diff --git
a/src/UserGuide/latest/Deployment-and-Maintenance/Deployment-Guide.md
b/src/UserGuide/latest/Deployment-and-Maintenance/Deployment-Guide.md
index 3df2116..2d00df9 100644
--- a/src/UserGuide/latest/Deployment-and-Maintenance/Deployment-Guide.md
+++ b/src/UserGuide/latest/Deployment-and-Maintenance/Deployment-Guide.md
@@ -266,7 +266,7 @@ You can either download the binary release files (see Chap
3.1) or compile with
1. Open our website [Download Page](https://iotdb.apache.org/Download/).
2. Download the binary distribution.
-3. Decompress to get the apache-iotdb-1.0.0-all-bin directory.
+3. Decompress to get the apache-iotdb-1.3.x-all-bin directory.
#### Compile with source code
@@ -276,14 +276,14 @@ You can either download the binary release files (see
Chap 3.1) or compile with
```
git clone https://github.com/apache/iotdb.git
-git checkout v1.0.0
+git checkout v1.3.x
```
**Website**
1. Open our website [Download Page](https://iotdb.apache.org/Download/).
2. Download the source code.
-3. Decompress to get the apache-iotdb-1.0.0 directory.
+3. Decompress to get the apache-iotdb-1.3.x directory.
##### Compile source code
@@ -294,7 +294,7 @@ mvn clean package -pl distribution -am -DskipTests
```
Then you will get the binary distribution under
-**distribution/target/apache-iotdb-1.0.0-SNAPSHOT-all-bin/apache-iotdb-1.0.0-SNAPSHOT-all-bin**.
+**distribution/target/apache-iotdb-1.3.x-SNAPSHOT-all-bin/apache-iotdb-1.3.x-SNAPSHOT-all-bin**.
### Binary Distribution Content
@@ -317,7 +317,7 @@ Please deploy the files to all servers of your target
cluster.
A best practice is deploying the files into the same directory in all servers.
If you want to try the cluster mode on one server, please read
-[Cluster Quick
Start](https://iotdb.apache.org/UserGuide/Master/QuickStart/ClusterQuickStart.html).
+[Cluster Quick Start](../QuickStart/ClusterQuickStart.md).
#### Cluster Configuration
@@ -436,7 +436,7 @@ nohup bash ./sbin/start-confignode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of ConfigNode, see the
-[ConfigNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/ConfigNode-Config-Manual.html).
+[ConfigNode Configurations](../Reference/ConfigNode-Config-Manual.md).
##### Add more ConfigNodes (Optional)
@@ -481,7 +481,7 @@ nohup bash ./sbin/start-confignode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of ConfigNode, see the
-[ConfigNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/ConfigNode-Config-Manual.html).
+[ConfigNode Configurations](../Reference/ConfigNode-Config-Manual.md).
##### Start DataNode
@@ -523,7 +523,7 @@ nohup bash ./sbin/start-datanode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of DataNode, see the
-[DataNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/DataNode-Config-Manual.html).
+[DataNode Configurations](../Reference/DataNode-Config-Manual.md).
**Notice: The cluster can provide services only if the number of its DataNodes
is no less than the number of replicas(max{schema\_replication\_factor,
data\_replication\_factor}).**
@@ -668,4 +668,4 @@ Run the remove-datanode script on an active DataNode:
### FAQ
-See
[FAQ](https://iotdb.apache.org/UserGuide/Master/FAQ/FAQ-for-cluster-setup.html).
\ No newline at end of file
+See [FAQ](../FAQ/Frequently-asked-questions.md).
\ No newline at end of file
diff --git
a/src/UserGuide/latest/Deployment-and-Maintenance/Deployment-Guide_timecho.md
b/src/UserGuide/latest/Deployment-and-Maintenance/Deployment-Guide_timecho.md
index cde1133..b4e49b7 100644
---
a/src/UserGuide/latest/Deployment-and-Maintenance/Deployment-Guide_timecho.md
+++
b/src/UserGuide/latest/Deployment-and-Maintenance/Deployment-Guide_timecho.md
@@ -124,8 +124,8 @@ iotdbctl cluster check example
* `global` is a general configuration that mainly configures machine username
and password, IoTDB local installation files, Jdk configuration, etc. A
`default_cluster.yaml` sample data is provided in the `iotdbctl/config`
directory,
Users can copy and modify it to their own cluster name and refer to the
instructions inside to configure the IoTDB cluster. In the
`default_cluster.yaml` sample, all uncommented items are required, and those
that have been commented are non-required.
-例如要执行`default_cluster.yaml`检查命令则需要执行命令`iotdbctl cluster check
default_cluster`即可,
-更多详细命令请参考下面命令列表。
+For example, to execute the `default_cluster.yaml` check command you need to
execute the command `iotdbctl cluster check default_cluster`.
+See further details in the following list of commands.
| parameter name | parameter describe
|
required |
@@ -278,7 +278,7 @@ iotdbctl cluster scalein default_cluster
* Configure the server's `user`, `passwod` or `pkey`, `ssh_port`
* Modify the IoTDB deployment path in config/xxx.yaml, `deploy_dir` (IoTDB
deployment directory), `iotdb_dir_name` (IoTDB decompression directory name,
the default is iotdb)
- For example, if the full path of IoTDB deployment is
`/home/data/apache-iotdb-1.1.1`, you need to modify the yaml files
`deploy_dir:/home/data/` and `iotdb_dir_name:apache-iotdb-1.1.1`
+ For example, if the full path of IoTDB deployment is
`/home/data/apache-iotdb-1.1.1`, you need to modify the yaml files
`deploy_dir:/home/data/` and `iotdb_dir_name:apache-iotdb-1.3.x`
* If the server is not using java_home, modify `jdk_deploy_dir` (jdk
deployment directory) and `jdk_dir_name` (the directory name after jdk
decompression, the default is jdk_iotdb). If java_home is used, there is no
need to modify the configuration.
For example, the full path of jdk deployment is `/home/data/jdk_1.8.2`, you
need to modify the yaml files `jdk_deploy_dir:/home/data/`,
`jdk_dir_name:jdk_1.8.2`
* Configure `cn_internal_address`, `dn_internal_address`
@@ -754,13 +754,13 @@ In the cluster deployment tool installation directory
config/example, there are
### Get the Installation Package
-You can either download the binary release files (see Chap 3.1) or compile
with source code (see Chap 3.2).
+You can either download the binary release files or compile with source code.
#### Download the binary distribution
1. Open our website [Download Page](https://iotdb.apache.org/Download/).
2. Download the binary distribution.
-3. Decompress to get the apache-iotdb-1.0.0-all-bin directory.
+3. Decompress to get the apache-iotdb-1.3.x-all-bin directory.
#### Compile with source code
@@ -770,14 +770,14 @@ You can either download the binary release files (see
Chap 3.1) or compile with
```
git clone https://github.com/apache/iotdb.git
-git checkout v1.0.0
+git checkout v1.3.x
```
**Website**
1. Open our website [Download Page](https://iotdb.apache.org/Download/).
2. Download the source code.
-3. Decompress to get the apache-iotdb-1.0.0 directory.
+3. Decompress to get the apache-iotdb-1.3.x directory.
##### Compile source code
@@ -788,7 +788,7 @@ mvn clean package -pl distribution -am -DskipTests
```
Then you will get the binary distribution under
-**distribution/target/apache-iotdb-1.0.0-SNAPSHOT-all-bin/apache-iotdb-1.0.0-SNAPSHOT-all-bin**.
+**distribution/target/apache-iotdb-1.3.x-SNAPSHOT-all-bin/apache-iotdb-1.3.x-SNAPSHOT-all-bin**.
### Binary Distribution Content
@@ -811,7 +811,7 @@ Please deploy the files to all servers of your target
cluster.
A best practice is deploying the files into the same directory in all servers.
If you want to try the cluster mode on one server, please read
-[Cluster Quick
Start](https://iotdb.apache.org/UserGuide/Master/QuickStart/ClusterQuickStart.html).
+[Cluster Quick Start](../QuickStart/ClusterQuickStart.md).
#### Cluster Configuration
@@ -819,11 +819,11 @@ We need to modify the configurations on each server.
Therefore, login each server and switch the working directory to
`apache-iotdb-1.0.0-SNAPSHOT-all-bin`.
The configuration files are stored in the `./conf` directory.
-For all ConfigNode servers, we need to modify the common configuration (see
Chap 5.2.1)
-and ConfigNode configuration (see Chap 5.2.2).
+For all ConfigNode servers, we need to modify the common configuration
+and ConfigNode configuration .
-For all DataNode servers, we need to modify the common configuration (see Chap
5.2.1)
-and DataNode configuration (see Chap 5.2.3).
+For all DataNode servers, we need to modify the common configuration
+and DataNode configuration.
##### Common configuration
@@ -930,7 +930,7 @@ nohup bash ./sbin/start-confignode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of ConfigNode, see the
-[ConfigNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/ConfigNode-Config-Manual.html).
+[ConfigNode Configurations](../Reference/ConfigNode-Config-Manual.md).
##### Add more ConfigNodes (Optional)
@@ -975,7 +975,7 @@ nohup bash ./sbin/start-confignode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of ConfigNode, see the
-[ConfigNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/ConfigNode-Config-Manual.html).
+[ConfigNode Configurations](../Reference/ConfigNode-Config-Manual.md).
##### Start DataNode
@@ -1017,7 +1017,7 @@ nohup bash ./sbin/start-datanode.sh >/dev/null 2>&1 &
```
For more details about other configuration parameters of DataNode, see the
-[DataNode
Configurations](https://iotdb.apache.org/UserGuide/Master/Reference/DataNode-Config-Manual.html).
+[DataNode Configurations](../Reference/DataNode-Config-Manual.md).
**Notice: The cluster can provide services only if the number of its DataNodes
is no less than the number of replicas(max{schema\_replication\_factor,
data\_replication\_factor}).**
@@ -1034,7 +1034,7 @@ If the cluster is in local environment, you can directly
run the Cli startup scr
```
If you want to use the Cli to connect to a cluster in the production
environment,
-Please read the [Cli
manual](https://iotdb.apache.org/UserGuide/Master/QuickStart/Command-Line-Interface.html).
+Please read the [Cli manual](../Tools-System/CLI.md).
#### Verify Cluster
@@ -1162,7 +1162,7 @@ Run the remove-datanode script on an active DataNode:
### FAQ
-See
[FAQ](https://iotdb.apache.org/UserGuide/Master/FAQ/FAQ-for-cluster-setup.html).
+See [FAQ](../FAQ/Frequently-asked-questions.md).
## AINode deployment
diff --git
a/src/UserGuide/latest/Deployment-and-Maintenance/Monitoring-Board-Install-and-Deploy.md
b/src/UserGuide/latest/Deployment-and-Maintenance/Monitoring-Board-Install-and-Deploy.md
index b5e8f86..7dfe97f 100644
---
a/src/UserGuide/latest/Deployment-and-Maintenance/Monitoring-Board-Install-and-Deploy.md
+++
b/src/UserGuide/latest/Deployment-and-Maintenance/Monitoring-Board-Install-and-Deploy.md
@@ -150,11 +150,11 @@ cd grafana-*
3. Enter http://localhost:3000 in your browser to access Grafana, the default
initial username and password are both admin.
4. First we configure the Data Source in Configuration to be Prometheus.
-
+
5. When configuring the Data Source, pay attention to the URL where Prometheus
is located, and click Save & Test after configuration, the Data source is
working prompt appears, then the configuration is successful.
-
+
### 1.3.2 Step2:Import the IoTDB Dashboards
@@ -200,7 +200,7 @@ cd grafana-*
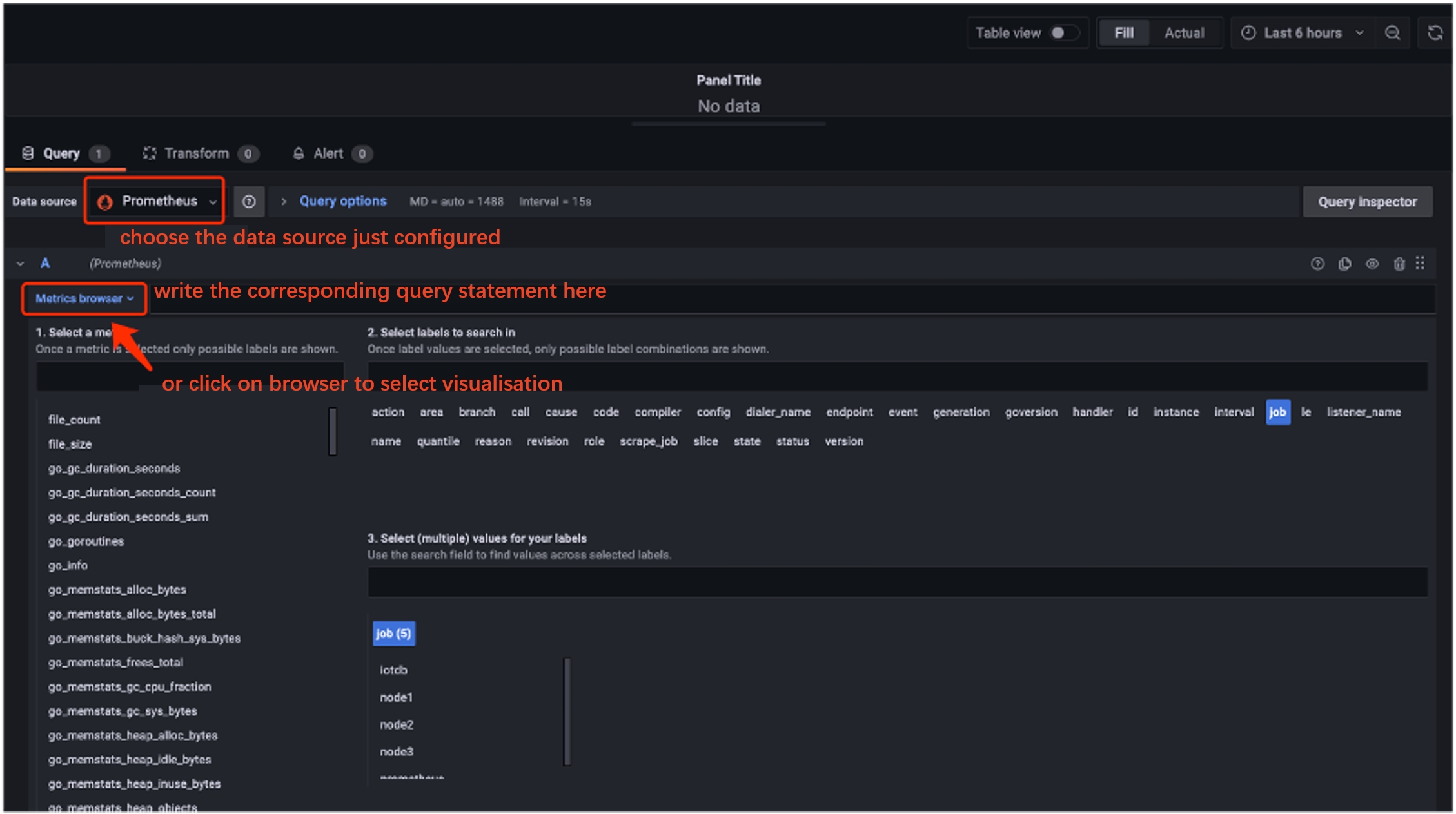
2. After that, you can visualize the monitoring-related data in the panel
according to your needs (all relevant monitoring metrics can be filtered by
selecting confignode/datanode in the job first).
-
+
3. Once the visualisation of the monitoring metrics selected for attention is
complete, we get a panel like this:
diff --git a/src/UserGuide/latest/FAQ/Frequently-asked-questions.md
b/src/UserGuide/latest/FAQ/Frequently-asked-questions.md
index f718599..1a431b9 100644
--- a/src/UserGuide/latest/FAQ/Frequently-asked-questions.md
+++ b/src/UserGuide/latest/FAQ/Frequently-asked-questions.md
@@ -116,7 +116,7 @@ If you are using Linux, you can use the following shell
command:
### 5. Can I use Hadoop and Spark to read TsFile in IoTDB?
-Yes. IoTDB has intense integration with Open Source Ecosystem. IoTDB supports
[Hadoop](https://github.com/apache/iotdb/tree/master/iotdb-connector/hadoop),
[Spark](https://github.com/apache/iotdb/tree/master/iotdb-connector/spark-iotdb-connector)
and
[Grafana](https://github.com/apache/iotdb/tree/master/iotdb-connector/grafana-connector)
visualization tool.
+Yes. IoTDB has intense integration with Open Source Ecosystem. IoTDB supports
[Hadoop](https://github.com/apache/iotdb-extras/tree/master/connectors/hadoop),
[Spark](https://github.com/apache/iotdb-extras/tree/master/connectors/spark-iotdb-connector)
and
[Grafana](https://github.com/apache/iotdb-extras/tree/master/connectors/grafana-connector)
visualization tool.
### 6. How does IoTDB handle duplicate points?
@@ -202,7 +202,7 @@ not affect normal operations. We will fix this message in
the incoming releases.
#### 4. Failed to remove DataNode, how to find the reason?
-- Examine whether the parameter of remove-datanode.sh is correct, only
rpcIp:rpcPort and dataNodeId are correct parameter.
+- Examine whether the parameter of `remove-datanode.sh` is correct, only
rpcIp:rpcPort and dataNodeId are correct parameter.
- Only when the number of available DataNodes in the cluster is greater than
max(schema_replication_factor, data_replication_factor), removing operation can
be executed.
- Removing DataNode will migrate the data from the removing DataNode to other
alive DataNodes. Data migration is based on Region, if some regions are
migrated failed, the removing DataNode will always in the status of `Removing`.
- If the DataNode is in the status of `Removing`, the regions in the removing
DataNode will also in the status of `Removing` or `Unknown`, which are
unavailable status. Besides, the removing DataNode will not receive new write
requests from client.
@@ -226,13 +226,13 @@ not affect normal operations. We will fix this message in
the incoming releases.
#### 1. How to restart any ConfigNode in the cluster?
-- First step: stop the process by stop-confignode.sh or kill PID of ConfigNode.
-- Second step: execute start-confignode.sh to restart ConfigNode.
+- First step: stop the process by `stop-confignode.sh` or kill PID of
ConfigNode.
+- Second step: execute `start-confignode.sh` to restart ConfigNode.
#### 2. How to restart any DataNode in the cluster?
-- First step: stop the process by stop-datanode.sh or kill PID of DataNode.
-- Second step: execute start-datanode.sh to restart DataNode.
+- First step: stop the process by `stop-datanode.sh` or kill PID of DataNode.
+- Second step: execute `s`tart-datanode.sh` to restart DataNode.
#### 3. If it's possible to restart ConfigNode using the old data directory
when it's removed?
@@ -242,7 +242,7 @@ not affect normal operations. We will fix this message in
the incoming releases.
- Can't. The running result will be "Reject DataNode restart. Because there
are no corresponding DataNode(whose nodeId=xx) in the cluster. Possible
solutions are as follows:...".
-#### 5. Can we execute start-confignode.sh/start-datanode.sh successfully when
delete the data directory of given ConfigNode/DataNode without killing the PID?
+#### 5. Can we execute `start-confignode.sh`/`start-datanode.sh` successfully
when delete the data directory of given ConfigNode/DataNode without killing the
PID?
- Can't. The running result will be "The port is already occupied".
@@ -255,7 +255,7 @@ not affect normal operations. We will fix this message in
the incoming releases.
#### 2. How to fix one DataNode when the disk file is broken?
-- We can use remove-datanode.sh to fix it. Remove-datanode will migrate the
data in the removing DataNode to other alive DataNodes.
+- We can use `remove-datanode.sh` to fix it. Remove-datanode will migrate the
data in the removing DataNode to other alive DataNodes.
- IoTDB will publish Node-Fix tools in the next version.
#### 3. How to decrease the memory usage of ConfigNode/DataNode?
diff --git a/src/UserGuide/latest/QuickStart/QuickStart.md
b/src/UserGuide/latest/QuickStart/QuickStart.md
index a5fc87a..4c2f867 100644
--- a/src/UserGuide/latest/QuickStart/QuickStart.md
+++ b/src/UserGuide/latest/QuickStart/QuickStart.md
@@ -111,11 +111,11 @@ We can also use SHOW DATABASES to check created databases:
```
IoTDB> SHOW DATABASES
-+-----------------------------------+
-| Database|
-+-----------------------------------+
-| root.ln|
-+-----------------------------------+
++---------------+----+-----------------------+---------------------+---------------------+
+| Database|
TTL|SchemaReplicationFactor|DataReplicationFactor|TimePartitionInterval|
++---------------+----+-----------------------+---------------------+---------------------+
+| root.ln|null| 1| 1|
604800000|
++---------------+----+-----------------------+---------------------+---------------------+
Database number = 1
```
diff --git a/src/UserGuide/latest/Tools-System/Benchmark.md
b/src/UserGuide/latest/Tools-System/Benchmark.md
index 2dd6e3e..e067702 100644
--- a/src/UserGuide/latest/Tools-System/Benchmark.md
+++ b/src/UserGuide/latest/Tools-System/Benchmark.md
@@ -331,4 +331,4 @@ Table 2-5 Configuration parameter information
| STRING_LENGTH | 10
| String length |
|
| DOUBLE_LENGTH | 2
| Decimal places |
|
| Three machines simulate data writing of 300 devices |
BENCHMARK_CLUSTER | true
| Enable multi-benchmark mode |
-| BENCHMARK_INDEX | 0, 1, 3
| Take the writing parameters in the previous chapter as an
example: No. 0 is responsible for writing data of device numbers 0-99; No. 1 is
responsible for writing data of device numbers 100-199; No. 2 is responsible
for writing data of device numbers 200-299. |
|
\ No newline at end of file
+| BENCHMARK_INDEX | 0, 1, 3
| Take the writing parameters in the [write
test](./Benchmark.md#write-test) as an example: No. 0 is responsible for
writing data of device numbers 0-99; No. 1 is responsible for writing data of
device numbers 100-199; No. 2 is responsible for writing data of device numbers
200-299. | |
\ No newline at end of file
diff --git a/src/UserGuide/latest/User-Manual/Syntax-Rule.md
b/src/UserGuide/latest/User-Manual/Syntax-Rule.md
index 83ec978..30ac234 100644
--- a/src/UserGuide/latest/User-Manual/Syntax-Rule.md
+++ b/src/UserGuide/latest/User-Manual/Syntax-Rule.md
@@ -188,11 +188,11 @@ Below are basic constraints of identifiers, specific
identifiers may have other
```sql
# create template t1't"t
-create schema template `t1't"t`
+create device template `t1't"t`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
# create template t1`t
-create schema template `t1``t`
+create device template `t1``t`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
```
@@ -225,7 +225,7 @@ Examples of case in which quoted identifier is used :
```sql
# create a template named 111, 111 is a real number.
- create schema template `111`
+ create device template `111`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
```
diff --git a/src/zh/UserGuide/Master/Basic-Concept/Encoding-and-Compression.md
b/src/zh/UserGuide/Master/Basic-Concept/Encoding-and-Compression.md
index 96c033c..800432e 100644
--- a/src/zh/UserGuide/Master/Basic-Concept/Encoding-and-Compression.md
+++ b/src/zh/UserGuide/Master/Basic-Concept/Encoding-and-Compression.md
@@ -115,7 +115,7 @@ IoTDB 允许在创建一个时间序列的时候指定该列的压缩方式。
### 压缩比统计信息
-压缩比统计信息文件:data/system/compression_ratio/Ratio-{ratio_sum}-{memtable_flush_time}
+压缩比统计信息文件:data/datanode/system/compression_ratio
* ratio_sum: memtable压缩比的总和
* memtable_flush_time: memtable刷盘的总次数
diff --git a/src/zh/UserGuide/Master/FAQ/Frequently-asked-questions.md
b/src/zh/UserGuide/Master/FAQ/Frequently-asked-questions.md
index f569c40..aae25f4 100644
--- a/src/zh/UserGuide/Master/FAQ/Frequently-asked-questions.md
+++ b/src/zh/UserGuide/Master/FAQ/Frequently-asked-questions.md
@@ -118,7 +118,7 @@ IoTDB> count timeseries
### 5. 可以使用Hadoop和Spark读取IoTDB中的TsFile吗?
-是的。IoTDB 与开源生态紧密结合。IoTDB 支持
[Hadoop](https://github.com/apache/iotdb/tree/master/iotdb-connector/hadoop),
[Spark](https://github.com/apache/iotdb/tree/master/iotdb-connector/spark-iotdb-connector)
和
[Grafana](https://github.com/apache/iotdb/tree/master/iotdb-connector/grafana-connector)
可视化工具。
+是的。IoTDB 与开源生态紧密结合。IoTDB 支持
[Hadoop](https://github.com/apache/iotdb-extras/tree/master/connectors/iotdb-connector/hadoop),
[Spark](https://github.com/apache/iotdb-extras/tree/master/connectors/spark-iotdb-connector)
和
[Grafana](https://github.com/apache/iotdb-extras/tree/master/connectors/grafana-connector)
可视化工具。
### 6. IoTDB如何处理重复的数据点?
@@ -205,7 +205,7 @@ datanode_memory_proportion参数控制分给查询的内存,chunk_timeseriesme
- 检查remove-datanode脚本的参数是否正确,是否传入了正确的ip:port或正确的dataNodeId
- 只有集群可用节点数量 > max(元数据副本数量, 数据副本数量)时,移除操作才允许被执行
-
执行移除DataNode的过程会将该DataNode上的数据迁移到其他存活的DataNode,数据迁移以Region为粒度,如果某个Region迁移失败,则被移除的DataNode会一直处于Removing状态
-- 补充:处于Removing状态的节点,其节点上的Region也是Removing或Unknown状态,即不可用状态。
该Remvoing状态的节点也不会接受客户端的请求。如果要使Removing状态的节点变为可用,用户可以使用set system status to
running 命令将该节点设置为Running状态;如果要使迁移失败的Region处于可用状态,可以使用migrate region from
datanodeId1 to datanodeId2
命令将该不可用的Region迁移到其他存活的节点。另外IoTDB后续也会提供remove-datanode.sh
-f命令,来强制移除节点(迁移失败的Region会直接丢弃)
+- 补充:处于Removing状态的节点,其节点上的Region也是Removing或Unknown状态,即不可用状态。
该Remvoing状态的节点也不会接受客户端的请求。如果要使Removing状态的节点变为可用,用户可以使用set system status to
running 命令将该节点设置为Running状态;如果要使迁移失败的Region处于可用状态,可以使用migrate region from
datanodeId1 to datanodeId2 命令将该不可用的Region迁移到其他存活的节点。另外IoTDB后续也会提供
`remove-datanode.sh -f` 命令,来强制移除节点(迁移失败的Region会直接丢弃)
#### 5. 挂掉的DataNode是否支持移除?
@@ -221,14 +221,14 @@ datanode_memory_proportion参数控制分给查询的内存,chunk_timeseriesme
#### 1. 如何重启集群中的某个ConfigNode?
-- 第一步:通过stop-confignode.sh或kill进程方式关闭ConfigNode进程
-- 第二步:通过执行start-confignode.sh启动ConfigNode进程实现重启
+- 第一步:通过`stop-confignode.sh`或kill进程方式关闭ConfigNode进程
+- 第二步:通过执行`start-confignode.sh`启动ConfigNode进程实现重启
- 下个版本IoTDB会提供一键重启的操作
#### 2. 如何重启集群中的某个DataNode?
-- 第一步:通过stop-datanode.sh或kill进程方式关闭DataNode进程
-- 第二步:通过执行start-datanode.sh启动DataNode进程实现重启
+- 第一步:通过`stop-datanode.sh`或kill进程方式关闭DataNode进程
+- 第二步:通过执行`start-datanode.sh`启动DataNode进程实现重启
- 下个版本IoTDB会提供一键重启的操作
#### 3. 将某个ConfigNode移除后(remove-confignode),能否再利用该ConfigNode的data目录重启?
@@ -239,7 +239,7 @@ datanode_memory_proportion参数控制分给查询的内存,chunk_timeseriesme
- 不能正常重启,启动结果为“Reject DataNode restart. Because there are no corresponding
DataNode(whose nodeId=xx) in the cluster. Possible solutions are as follows:...”
-#### 5.
用户看到某个ConfigNode/DataNode变成了Unknown状态,在没有kill对应进程的情况下,直接删除掉ConfigNode/DataNode对应的data目录,然后执行start-confignode.sh/start-datanode.sh,这种情况下能成功吗?
+#### 5.
用户看到某个ConfigNode/DataNode变成了Unknown状态,在没有kill对应进程的情况下,直接删除掉ConfigNode/DataNode对应的data目录,然后执行`start-confignode.sh`/`start-datanode.sh`,这种情况下能成功吗?
- 无法启动成功,会报错端口已被占用
diff --git a/src/zh/UserGuide/Master/QuickStart/QuickStart.md
b/src/zh/UserGuide/Master/QuickStart/QuickStart.md
index 553aa7f..8cb9cfe 100644
--- a/src/zh/UserGuide/Master/QuickStart/QuickStart.md
+++ b/src/zh/UserGuide/Master/QuickStart/QuickStart.md
@@ -122,11 +122,11 @@ IoTDB> SHOW DATABASES
执行结果为:
```
-+-------------+
-| database|
-+-------------+
-| root.ln|
-+-------------+
++---------------+----+-----------------------+---------------------+---------------------+
+| Database|
TTL|SchemaReplicationFactor|DataReplicationFactor|TimePartitionInterval|
++---------------+----+-----------------------+---------------------+---------------------+
+| root.ln|null| 1| 1|
604800000|
++---------------+----+-----------------------+---------------------+---------------------+
Total line number = 1
```
diff --git a/src/zh/UserGuide/Master/Tools-System/Benchmark.md
b/src/zh/UserGuide/Master/Tools-System/Benchmark.md
index 52d094c..080148b 100644
--- a/src/zh/UserGuide/Master/Tools-System/Benchmark.md
+++ b/src/zh/UserGuide/Master/Tools-System/Benchmark.md
@@ -349,4 +349,4 @@ IoT-benchmark目前支持通过配置参数“TEST_DATA_PERSISTENCE”将测试
| STRING_LENGTH | 10
| 字符串长度 |
|
| DOUBLE_LENGTH | 2
| 小数位数 |
|
| 三台机器模拟300台设备数据写入 | BENCHMARK_CLUSTER
| true | 开启多benchmark模式
|
-| BENCHMARK_INDEX | 0、1、3
|
以2.3章节写入参数为例:0号负责设备编号0-99数据写入;1号负责设备编号100-199数据写入;2号负责设备编号200-299数据写入; |
|
\ No newline at end of file
+| BENCHMARK_INDEX | 0、1、3
|
以[写入测试](./Benchmark.md#写入测试)写入参数为例:0号负责设备编号0-99数据写入;1号负责设备编号100-199数据写入;2号负责设备编号200-299数据写入;
| |
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/User-Manual/Syntax-Rule.md
b/src/zh/UserGuide/Master/User-Manual/Syntax-Rule.md
index f131d73..379bc26 100644
--- a/src/zh/UserGuide/Master/User-Manual/Syntax-Rule.md
+++ b/src/zh/UserGuide/Master/User-Manual/Syntax-Rule.md
@@ -185,11 +185,11 @@
```SQL
# 创建模板 t1`t
-create schema template `t1``t`
+create device template `t1``t`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
# 创建模板 t1't"t
-create schema template `t1't"t`
+create device template `t1't"t`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
```
@@ -222,7 +222,7 @@ create schema template `t1't"t`
```sql
# 创建名为 111 的元数据模板,111 为实数,需要用反引号引用。
- create schema template `111`
+ create device template `111`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
```
diff --git a/src/zh/UserGuide/latest/Basic-Concept/Encoding-and-Compression.md
b/src/zh/UserGuide/latest/Basic-Concept/Encoding-and-Compression.md
index 8be0d4e..71dba0f 100644
--- a/src/zh/UserGuide/latest/Basic-Concept/Encoding-and-Compression.md
+++ b/src/zh/UserGuide/latest/Basic-Concept/Encoding-and-Compression.md
@@ -115,7 +115,7 @@ IoTDB 允许在创建一个时间序列的时候指定该列的压缩方式。
### 压缩比统计信息
-压缩比统计信息文件:data/datanode/system/compression_ratio/Ratio-{ratio_sum}-{memtable_flush_time}
+压缩比统计信息文件:data/datanode/system/compression_ratio
* ratio_sum: memtable压缩比的总和
* memtable_flush_time: memtable刷盘的总次数
diff --git a/src/zh/UserGuide/latest/FAQ/Frequently-asked-questions.md
b/src/zh/UserGuide/latest/FAQ/Frequently-asked-questions.md
index f569c40..f70ee95 100644
--- a/src/zh/UserGuide/latest/FAQ/Frequently-asked-questions.md
+++ b/src/zh/UserGuide/latest/FAQ/Frequently-asked-questions.md
@@ -91,7 +91,7 @@ Readme.md
### 3. 在哪里可以找到IoTDB的数据文件?
-在默认的设置里,数据文件(包含 TsFile,metadata,WAL)被存储在```IOTDB_HOME/data/datanode```文件夹。
+在默认的设置里,数据文件(包含 TsFile,metadata,WAL)被存储在```IOTDB_HOME/data/dtanode```文件夹。
### 4. 如何知道IoTDB中存储了多少时间序列?
@@ -102,7 +102,7 @@ IoTDB> show timeseries
```
在返回的结果里,会展示`Total timeseries number`,这个数据就是 IoTDB 中 timeseries 的数量。
-
+a
在当前版本中,IoTDB 支持直接使用命令行接口查询时间序列的数量:
```
@@ -118,7 +118,7 @@ IoTDB> count timeseries
### 5. 可以使用Hadoop和Spark读取IoTDB中的TsFile吗?
-是的。IoTDB 与开源生态紧密结合。IoTDB 支持
[Hadoop](https://github.com/apache/iotdb/tree/master/iotdb-connector/hadoop),
[Spark](https://github.com/apache/iotdb/tree/master/iotdb-connector/spark-iotdb-connector)
和
[Grafana](https://github.com/apache/iotdb/tree/master/iotdb-connector/grafana-connector)
可视化工具。
+是的。IoTDB 与开源生态紧密结合。IoTDB 支持
[Hadoop](https://github.com/apache/iotdb-extras/tree/master/connectors/hadoop),
[Spark](https://github.com/apache/iotdb-extras/tree/master/connectors/spark-iotdb-connector)
和
[Grafana](https://github.com/apache/iotdb-extras/tree/master/connectors/grafana-connector)
可视化工具。
### 6. IoTDB如何处理重复的数据点?
@@ -202,10 +202,10 @@ datanode_memory_proportion参数控制分给查询的内存,chunk_timeseriesme
#### 4. 移除DataNode执行失败,如何排查?
-- 检查remove-datanode脚本的参数是否正确,是否传入了正确的ip:port或正确的dataNodeId
+- 检查`remove-datanode`脚本的参数是否正确,是否传入了正确的ip:port或正确的dataNodeId
- 只有集群可用节点数量 > max(元数据副本数量, 数据副本数量)时,移除操作才允许被执行
-
执行移除DataNode的过程会将该DataNode上的数据迁移到其他存活的DataNode,数据迁移以Region为粒度,如果某个Region迁移失败,则被移除的DataNode会一直处于Removing状态
-- 补充:处于Removing状态的节点,其节点上的Region也是Removing或Unknown状态,即不可用状态。
该Remvoing状态的节点也不会接受客户端的请求。如果要使Removing状态的节点变为可用,用户可以使用set system status to
running 命令将该节点设置为Running状态;如果要使迁移失败的Region处于可用状态,可以使用migrate region from
datanodeId1 to datanodeId2
命令将该不可用的Region迁移到其他存活的节点。另外IoTDB后续也会提供remove-datanode.sh
-f命令,来强制移除节点(迁移失败的Region会直接丢弃)
+- 补充:处于Removing状态的节点,其节点上的Region也是Removing或Unknown状态,即不可用状态。
该Remvoing状态的节点也不会接受客户端的请求。如果要使Removing状态的节点变为可用,用户可以使用set system status to
running 命令将该节点设置为Running状态;如果要使迁移失败的Region处于可用状态,可以使用migrate region from
datanodeId1 to datanodeId2
命令将该不可用的Region迁移到其他存活的节点。另外IoTDB后续也会提供`remove-datanode.sh
-f`命令,来强制移除节点(迁移失败的Region会直接丢弃)
#### 5. 挂掉的DataNode是否支持移除?
@@ -221,14 +221,14 @@ datanode_memory_proportion参数控制分给查询的内存,chunk_timeseriesme
#### 1. 如何重启集群中的某个ConfigNode?
-- 第一步:通过stop-confignode.sh或kill进程方式关闭ConfigNode进程
-- 第二步:通过执行start-confignode.sh启动ConfigNode进程实现重启
+- 第一步:通过`stop-confignode.sh`或kill进程方式关闭ConfigNode进程
+- 第二步:通过执行`start-confignode.sh`启动ConfigNode进程实现重启
- 下个版本IoTDB会提供一键重启的操作
#### 2. 如何重启集群中的某个DataNode?
-- 第一步:通过stop-datanode.sh或kill进程方式关闭DataNode进程
-- 第二步:通过执行start-datanode.sh启动DataNode进程实现重启
+- 第一步:通过`stop-datanode.sh`或kill进程方式关闭DataNode进程
+- 第二步:通过执行`start-datanode.sh`启动DataNode进程实现重启
- 下个版本IoTDB会提供一键重启的操作
#### 3. 将某个ConfigNode移除后(remove-confignode),能否再利用该ConfigNode的data目录重启?
@@ -239,7 +239,7 @@ datanode_memory_proportion参数控制分给查询的内存,chunk_timeseriesme
- 不能正常重启,启动结果为“Reject DataNode restart. Because there are no corresponding
DataNode(whose nodeId=xx) in the cluster. Possible solutions are as follows:...”
-#### 5.
用户看到某个ConfigNode/DataNode变成了Unknown状态,在没有kill对应进程的情况下,直接删除掉ConfigNode/DataNode对应的data目录,然后执行start-confignode.sh/start-datanode.sh,这种情况下能成功吗?
+#### 5.
用户看到某个ConfigNode/DataNode变成了Unknown状态,在没有kill对应进程的情况下,直接删除掉ConfigNode/DataNode对应的data目录,然后执行`start-confignode.sh`/`start-datanode.sh`,这种情况下能成功吗?
- 无法启动成功,会报错端口已被占用
@@ -257,5 +257,5 @@ datanode_memory_proportion参数控制分给查询的内存,chunk_timeseriesme
#### 3. 如何降低ConfigNode、DataNode使用的内存?
--
在conf/confignode-env.sh、conf/datanode-env.sh文件可通过调整ON_HEAP_MEMORY、OFF_HEAP_MEMORY等选项可以调整ConfigNode、DataNode使用的最大堆内、堆外内存
+-
在`conf/confignode-env.sh`、`conf/datanode-env.sh`文件可通过调整ON_HEAP_MEMORY、OFF_HEAP_MEMORY等选项可以调整ConfigNode、DataNode使用的最大堆内、堆外内存
diff --git a/src/zh/UserGuide/latest/QuickStart/QuickStart.md
b/src/zh/UserGuide/latest/QuickStart/QuickStart.md
index 85eb9f9..1389bff 100644
--- a/src/zh/UserGuide/latest/QuickStart/QuickStart.md
+++ b/src/zh/UserGuide/latest/QuickStart/QuickStart.md
@@ -122,11 +122,11 @@ IoTDB> SHOW DATABASES
执行结果为:
```
-+-------------+
-| database|
-+-------------+
-| root.ln|
-+-------------+
++---------------+----+-----------------------+---------------------+---------------------+
+| Database|
TTL|SchemaReplicationFactor|DataReplicationFactor|TimePartitionInterval|
++---------------+----+-----------------------+---------------------+---------------------+
+| root.ln|null| 1| 1|
604800000|
++---------------+----+-----------------------+---------------------+---------------------+
Total line number = 1
```
diff --git a/src/zh/UserGuide/latest/Tools-System/Benchmark.md
b/src/zh/UserGuide/latest/Tools-System/Benchmark.md
index 52d094c..080148b 100644
--- a/src/zh/UserGuide/latest/Tools-System/Benchmark.md
+++ b/src/zh/UserGuide/latest/Tools-System/Benchmark.md
@@ -349,4 +349,4 @@ IoT-benchmark目前支持通过配置参数“TEST_DATA_PERSISTENCE”将测试
| STRING_LENGTH | 10
| 字符串长度 |
|
| DOUBLE_LENGTH | 2
| 小数位数 |
|
| 三台机器模拟300台设备数据写入 | BENCHMARK_CLUSTER
| true | 开启多benchmark模式
|
-| BENCHMARK_INDEX | 0、1、3
|
以2.3章节写入参数为例:0号负责设备编号0-99数据写入;1号负责设备编号100-199数据写入;2号负责设备编号200-299数据写入; |
|
\ No newline at end of file
+| BENCHMARK_INDEX | 0、1、3
|
以[写入测试](./Benchmark.md#写入测试)写入参数为例:0号负责设备编号0-99数据写入;1号负责设备编号100-199数据写入;2号负责设备编号200-299数据写入;
| |
\ No newline at end of file
diff --git a/src/zh/UserGuide/latest/User-Manual/Syntax-Rule.md
b/src/zh/UserGuide/latest/User-Manual/Syntax-Rule.md
index f131d73..379bc26 100644
--- a/src/zh/UserGuide/latest/User-Manual/Syntax-Rule.md
+++ b/src/zh/UserGuide/latest/User-Manual/Syntax-Rule.md
@@ -185,11 +185,11 @@
```SQL
# 创建模板 t1`t
-create schema template `t1``t`
+create device template `t1``t`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
# 创建模板 t1't"t
-create schema template `t1't"t`
+create device template `t1't"t`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
```
@@ -222,7 +222,7 @@ create schema template `t1't"t`
```sql
# 创建名为 111 的元数据模板,111 为实数,需要用反引号引用。
- create schema template `111`
+ create device template `111`
(temperature FLOAT encoding=RLE, status BOOLEAN encoding=PLAIN
compression=SNAPPY)
```
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}