lsm1 commented on a change in pull request #1881:
URL: https://github.com/apache/incubator-kyuubi/pull/1881#discussion_r804310768
##########
File path:
dev/kyuubi-extension-spark-common/src/main/scala/org/apache/kyuubi/sql/watchdog/ForcedMaxOutputRowsBase.scala
##########
@@ -70,14 +65,14 @@ trait ForcedMaxOutputRowsBase extends Rule[LogicalPlan] {
true
}
case _: MultiInstanceRelation => true
+ case _: Join => true
case _ => false
}
protected def canInsertLimit(p: LogicalPlan, maxOutputRowsOpt: Option[Int]):
Boolean = {
maxOutputRowsOpt match {
case Some(forcedMaxOutputRows) => canInsertLimitInner(p) &&
- !p.maxRows.exists(_ <= forcedMaxOutputRows) &&
- !isView
Review comment:
SQL with view will first enter the resolveViews during analyze.The
Analyzer's Execute method will be called again, and the analysis of SQL
statements with view will recursively call Analyzer's Batches.
https://github.com/apache/incubator-kyuubi/pull/1247 add "isView" fixed this.
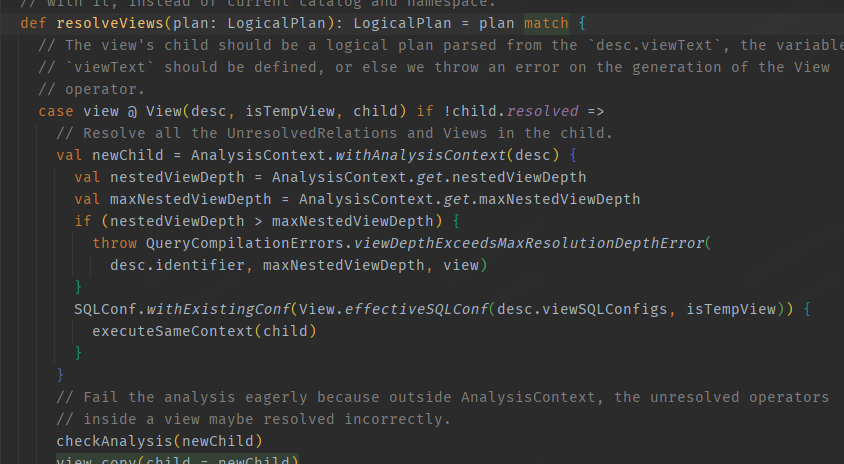
But now Place the ForcedMaxOutputRowsRule in the projectOptimizerRule
stage,we do not need this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}