This is an automated email from the ASF dual-hosted git repository.
chengpan pushed a commit to branch branch-1.7
in repository https://gitbox.apache.org/repos/asf/kyuubi.git
The following commit(s) were added to refs/heads/branch-1.7 by this push:
new 9439534ab [KYUUBI #4710] [ARROW] LocalTableScanExec should not trigger
job
9439534ab is described below
commit 9439534abf02f5619abb39970f93236029cad209
Author: Fu Chen <[email protected]>
AuthorDate: Thu Apr 20 17:58:27 2023 +0800
[KYUUBI #4710] [ARROW] LocalTableScanExec should not trigger job
### _Why are the changes needed?_
Before this PR:
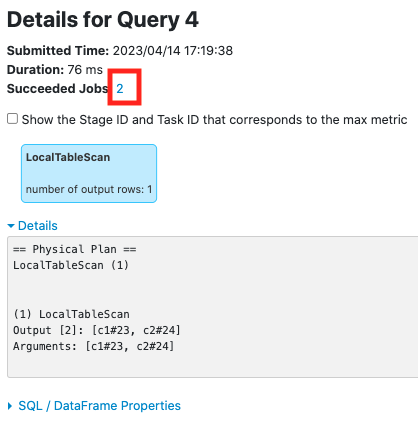
After this PR:
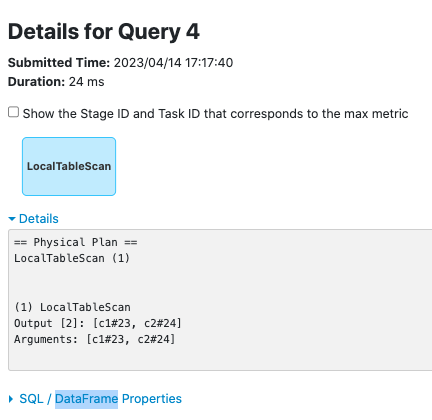
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including
negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run
test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests)
locally before make a pull request
Closes #4710 from cfmcgrady/arrow-local-table-scan-exec.
Closes #4710
e4c2891d1 [Fu Chen] fix ci
1049200ea [Fu Chen] fix style
4d45fe8b7 [Fu Chen] add assert
b8bd5b5a7 [Fu Chen] LocalTableScanExec should not trigger job
Authored-by: Fu Chen <[email protected]>
Signed-off-by: Cheng Pan <[email protected]>
(cherry picked from commit 9086b28bc392a928e7cd68aa03b69f3e60d73643)
Signed-off-by: Cheng Pan <[email protected]>
---
.../execution/arrow/KyuubiArrowConverters.scala | 8 +-
.../spark/sql/kyuubi/SparkDatasetHelper.scala | 15 ++-
.../operation/SparkArrowbasedOperationSuite.scala | 139 +++++++++++++--------
3 files changed, 103 insertions(+), 59 deletions(-)
diff --git
a/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/execution/arrow/KyuubiArrowConverters.scala
b/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/execution/arrow/KyuubiArrowConverters.scala
index 2feadbced..8a34943cc 100644
---
a/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/execution/arrow/KyuubiArrowConverters.scala
+++
b/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/execution/arrow/KyuubiArrowConverters.scala
@@ -203,7 +203,7 @@ object KyuubiArrowConverters extends SQLConfHelper with
Logging {
* Different from
[[org.apache.spark.sql.execution.arrow.ArrowConverters.toBatchIterator]],
* each output arrow batch contains this batch row count.
*/
- private def toBatchIterator(
+ def toBatchIterator(
rowIter: Iterator[InternalRow],
schema: StructType,
maxRecordsPerBatch: Long,
@@ -226,6 +226,7 @@ object KyuubiArrowConverters extends SQLConfHelper with
Logging {
* with two key differences:
* 1. there is no requirement to write the schema at the batch header
* 2. iteration halts when `rowCount` equals `limit`
+ * Note that `limit < 0` means no limit, and return all rows the in the
iterator.
*/
private[sql] class ArrowBatchIterator(
rowIter: Iterator[InternalRow],
@@ -255,7 +256,7 @@ object KyuubiArrowConverters extends SQLConfHelper with
Logging {
}
}
- override def hasNext: Boolean = (rowIter.hasNext && rowCount < limit) || {
+ override def hasNext: Boolean = (rowIter.hasNext && (rowCount < limit ||
limit < 0)) || {
root.close()
allocator.close()
false
@@ -283,7 +284,8 @@ object KyuubiArrowConverters extends SQLConfHelper with
Logging {
// If the size of rows are 0 or negative, unlimit it.
maxRecordsPerBatch <= 0 ||
rowCountInLastBatch < maxRecordsPerBatch ||
- rowCount < limit)) {
+ rowCount < limit ||
+ limit < 0)) {
val row = rowIter.next()
arrowWriter.write(row)
estimatedBatchSize += (row match {
diff --git
a/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
b/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
index 1c8d32c48..10b178324 100644
---
a/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
+++
b/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
@@ -24,7 +24,7 @@ import org.apache.spark.internal.Logging
import org.apache.spark.network.util.{ByteUnit, JavaUtils}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
-import org.apache.spark.sql.execution.{CollectLimitExec, SparkPlan,
SQLExecution}
+import org.apache.spark.sql.execution.{CollectLimitExec, LocalTableScanExec,
SparkPlan, SQLExecution}
import org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec
import org.apache.spark.sql.execution.arrow.{ArrowConverters,
KyuubiArrowConverters}
import org.apache.spark.sql.functions._
@@ -51,6 +51,8 @@ object SparkDatasetHelper extends Logging {
doCollectLimit(collectLimit)
case collectLimit: CollectLimitExec if collectLimit.limit < 0 =>
executeArrowBatchCollect(collectLimit.child)
+ case localTableScan: LocalTableScanExec =>
+ doLocalTableScan(localTableScan)
case plan: SparkPlan =>
toArrowBatchRdd(plan).collect()
}
@@ -175,6 +177,17 @@ object SparkDatasetHelper extends Logging {
result.toArray
}
+ def doLocalTableScan(localTableScan: LocalTableScanExec): Array[Array[Byte]]
= {
+ localTableScan.longMetric("numOutputRows").add(localTableScan.rows.size)
+ KyuubiArrowConverters.toBatchIterator(
+ localTableScan.rows.iterator,
+ localTableScan.schema,
+ SparkSession.active.sessionState.conf.arrowMaxRecordsPerBatch,
+ maxBatchSize,
+ -1,
+ SparkSession.active.sessionState.conf.sessionLocalTimeZone).toArray
+ }
+
/**
* This method provides a reflection-based implementation of
* [[AdaptiveSparkPlanExec.finalPhysicalPlan]] that enables us to adapt to
the Spark runtime
diff --git
a/externals/kyuubi-spark-sql-engine/src/test/scala/org/apache/kyuubi/engine/spark/operation/SparkArrowbasedOperationSuite.scala
b/externals/kyuubi-spark-sql-engine/src/test/scala/org/apache/kyuubi/engine/spark/operation/SparkArrowbasedOperationSuite.scala
index 2ef29b398..27310992f 100644
---
a/externals/kyuubi-spark-sql-engine/src/test/scala/org/apache/kyuubi/engine/spark/operation/SparkArrowbasedOperationSuite.scala
+++
b/externals/kyuubi-spark-sql-engine/src/test/scala/org/apache/kyuubi/engine/spark/operation/SparkArrowbasedOperationSuite.scala
@@ -23,8 +23,8 @@ import java.util.{Set => JSet}
import org.apache.spark.KyuubiSparkContextHelper
import org.apache.spark.scheduler.{SparkListener, SparkListenerJobStart}
import org.apache.spark.sql.{QueryTest, Row, SparkSession}
-import org.apache.spark.sql.catalyst.plans.logical.{LogicalPlan, Project}
-import org.apache.spark.sql.execution.{CollectLimitExec, QueryExecution,
SparkPlan}
+import org.apache.spark.sql.catalyst.plans.logical.Project
+import org.apache.spark.sql.execution.{CollectLimitExec, LocalTableScanExec,
QueryExecution, SparkPlan}
import org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec
import org.apache.spark.sql.execution.arrow.KyuubiArrowConverters
import org.apache.spark.sql.execution.exchange.Exchange
@@ -104,48 +104,29 @@ class SparkArrowbasedOperationSuite extends
WithSparkSQLEngine with SparkDataTyp
}
test("assign a new execution id for arrow-based result") {
- var plan: LogicalPlan = null
-
- val listener = new QueryExecutionListener {
- override def onSuccess(funcName: String, qe: QueryExecution, durationNs:
Long): Unit = {
- plan = qe.analyzed
+ val listener = new SQLMetricsListener
+ withJdbcStatement() { statement =>
+ withSparkListener(listener) {
+ val result = statement.executeQuery("select 1 as c1")
+ assert(result.next())
+ assert(result.getInt("c1") == 1)
}
- override def onFailure(funcName: String, qe: QueryExecution, exception:
Exception): Unit = {}
}
- withJdbcStatement() { statement =>
- // since all the new sessions have their owner listener bus, we should
register the listener
- // in the current session.
- registerListener(listener)
- val result = statement.executeQuery("select 1 as c1")
- assert(result.next())
- assert(result.getInt("c1") == 1)
- }
- KyuubiSparkContextHelper.waitListenerBus(spark)
- unregisterListener(listener)
- assert(plan.isInstanceOf[Project])
+ assert(listener.queryExecution.analyzed.isInstanceOf[Project])
}
test("arrow-based query metrics") {
- var queryExecution: QueryExecution = null
-
- val listener = new QueryExecutionListener {
- override def onSuccess(funcName: String, qe: QueryExecution, durationNs:
Long): Unit = {
- queryExecution = qe
- }
- override def onFailure(funcName: String, qe: QueryExecution, exception:
Exception): Unit = {}
- }
+ val listener = new SQLMetricsListener
withJdbcStatement() { statement =>
- registerListener(listener)
- val result = statement.executeQuery("select 1 as c1")
- assert(result.next())
- assert(result.getInt("c1") == 1)
+ withSparkListener(listener) {
+ val result = statement.executeQuery("select 1 as c1")
+ assert(result.next())
+ assert(result.getInt("c1") == 1)
+ }
}
- KyuubiSparkContextHelper.waitListenerBus(spark)
- unregisterListener(listener)
-
- val metrics = queryExecution.executedPlan.collectLeaves().head.metrics
+ val metrics =
listener.queryExecution.executedPlan.collectLeaves().head.metrics
assert(metrics.contains("numOutputRows"))
assert(metrics("numOutputRows").value === 1)
}
@@ -273,7 +254,6 @@ class SparkArrowbasedOperationSuite extends
WithSparkSQLEngine with SparkDataTyp
withPartitionedTable("t_3") {
statement.executeQuery("select * from t_3 limit 10 offset 10")
}
- KyuubiSparkContextHelper.waitListenerBus(spark)
}
}
// the extra shuffle be introduced if the `offset` > 0
@@ -292,13 +272,49 @@ class SparkArrowbasedOperationSuite extends
WithSparkSQLEngine with SparkDataTyp
withPartitionedTable("t_3") {
statement.executeQuery("select * from t_3 limit 1000")
}
- KyuubiSparkContextHelper.waitListenerBus(spark)
}
}
// Should be only one stage since there is no shuffle.
assert(numStages == 1)
}
+ test("LocalTableScanExec should not trigger job") {
+ val listener = new JobCountListener
+ withJdbcStatement("view_1") { statement =>
+ withSparkListener(listener) {
+ withAllSessions { s =>
+ import s.implicits._
+ Seq((1, "a")).toDF("c1", "c2").createOrReplaceTempView("view_1")
+ val plan = s.sql("select * from view_1").queryExecution.executedPlan
+ assert(plan.isInstanceOf[LocalTableScanExec])
+ }
+ val resultSet = statement.executeQuery("select * from view_1")
+ assert(resultSet.next())
+ assert(!resultSet.next())
+ }
+ }
+ assert(listener.numJobs == 0)
+ }
+
+ test("LocalTableScanExec metrics") {
+ val listener = new SQLMetricsListener
+ withJdbcStatement("view_1") { statement =>
+ withSparkListener(listener) {
+ withAllSessions { s =>
+ import s.implicits._
+ Seq((1, "a")).toDF("c1", "c2").createOrReplaceTempView("view_1")
+ }
+ val result = statement.executeQuery("select * from view_1")
+ assert(result.next())
+ assert(!result.next())
+ }
+ }
+
+ val metrics =
listener.queryExecution.executedPlan.collectLeaves().head.metrics
+ assert(metrics.contains("numOutputRows"))
+ assert(metrics("numOutputRows").value === 1)
+ }
+
private def checkResultSetFormat(statement: Statement, expectFormat:
String): Unit = {
val query =
s"""
@@ -321,32 +337,30 @@ class SparkArrowbasedOperationSuite extends
WithSparkSQLEngine with SparkDataTyp
assert(resultSet.getString("col") === expect)
}
- private def registerListener(listener: QueryExecutionListener): Unit = {
- // since all the new sessions have their owner listener bus, we should
register the listener
- // in the current session.
- SparkSQLEngine.currentEngine.get
- .backendService
- .sessionManager
- .allSessions()
-
.foreach(_.asInstanceOf[SparkSessionImpl].spark.listenerManager.register(listener))
- }
-
- private def unregisterListener(listener: QueryExecutionListener): Unit = {
- SparkSQLEngine.currentEngine.get
- .backendService
- .sessionManager
- .allSessions()
-
.foreach(_.asInstanceOf[SparkSessionImpl].spark.listenerManager.unregister(listener))
+ // since all the new sessions have their owner listener bus, we should
register the listener
+ // in the current session.
+ private def withSparkListener[T](listener: QueryExecutionListener)(body: =>
T): T = {
+ withAllSessions(s => s.listenerManager.register(listener))
+ try {
+ val result = body
+ KyuubiSparkContextHelper.waitListenerBus(spark)
+ result
+ } finally {
+ withAllSessions(s => s.listenerManager.unregister(listener))
+ }
}
+ // since all the new sessions have their owner listener bus, we should
register the listener
+ // in the current session.
private def withSparkListener[T](listener: SparkListener)(body: => T): T = {
withAllSessions(s => s.sparkContext.addSparkListener(listener))
try {
- body
+ val result = body
+ KyuubiSparkContextHelper.waitListenerBus(spark)
+ result
} finally {
withAllSessions(s => s.sparkContext.removeSparkListener(listener))
}
-
}
private def withPartitionedTable[T](viewName: String)(body: => T): T = {
@@ -432,6 +446,21 @@ class SparkArrowbasedOperationSuite extends
WithSparkSQLEngine with SparkDataTyp
.get()
staticConfKeys.contains(key)
}
+
+ class JobCountListener extends SparkListener {
+ var numJobs = 0
+ override def onJobStart(jobStart: SparkListenerJobStart): Unit = {
+ numJobs += 1
+ }
+ }
+
+ class SQLMetricsListener extends QueryExecutionListener {
+ var queryExecution: QueryExecution = null
+ override def onSuccess(funcName: String, qe: QueryExecution, durationNs:
Long): Unit = {
+ queryExecution = qe
+ }
+ override def onFailure(funcName: String, qe: QueryExecution, exception:
Exception): Unit = {}
+ }
}
case class TestData(key: Int, value: String)
{kind=link}
{kind=link}