This is an automated email from the ASF dual-hosted git repository.
chengpan pushed a commit to branch branch-1.7
in repository https://gitbox.apache.org/repos/asf/kyuubi.git
The following commit(s) were added to refs/heads/branch-1.7 by this push:
new 83cc18877 [KYUUBI #4702] [ARROW] CommandResultExec should not trigger
job
83cc18877 is described below
commit 83cc1887718bd1499b83b3598c078a70a76b3267
Author: Fu Chen <[email protected]>
AuthorDate: Sun Apr 23 16:07:17 2023 +0800
[KYUUBI #4702] [ARROW] CommandResultExec should not trigger job
### _Why are the changes needed?_
Before this PR:
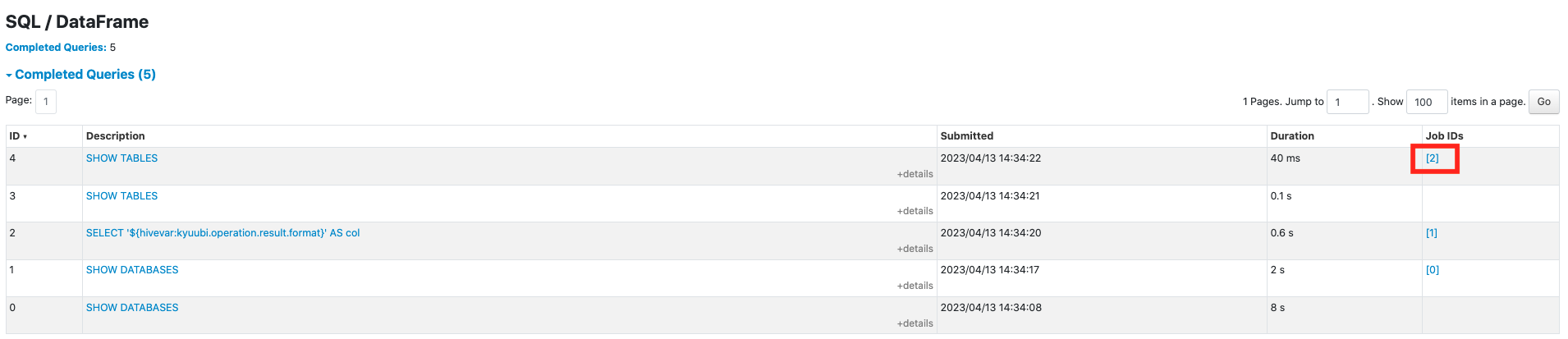
After this PR:
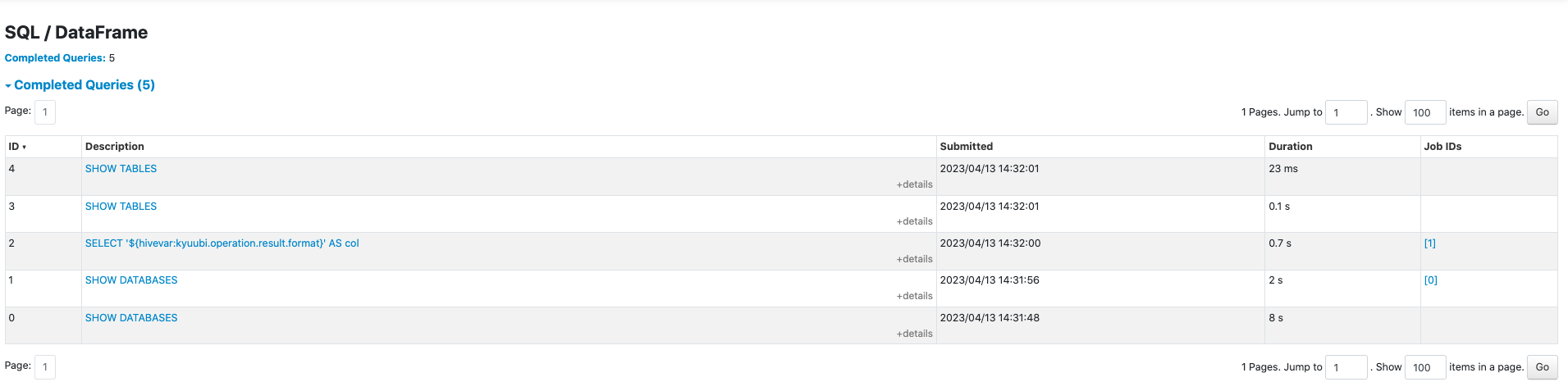
### _How was this patch tested?_
- [ ] Add some test cases that check the changes thoroughly including
negative and positive cases if possible
- [ ] Add screenshots for manual tests if appropriate
- [x] [Run
test](https://kyuubi.readthedocs.io/en/master/develop_tools/testing.html#running-tests)
locally before make a pull request
Closes #4702 from cfmcgrady/arrow-command-result-exec.
Closes #4702
8da308f33 [Fu Chen] address comment
aa35be498 [Fu Chen] address comment
625d5848a [Fu Chen] rebase master
263417e03 [Fu Chen] Merge remote-tracking branch 'apache/master' into
arrow-command-result-exec
49f23ce9f [Fu Chen] to refine
e39747f10 [Fu Chen] revert unnecessarily changes.
29acf104c [Fu Chen] CommandResultExec should not trigger job
Authored-by: Fu Chen <[email protected]>
Signed-off-by: Cheng Pan <[email protected]>
(cherry picked from commit 4ca025b3cff696dd886bcf3225714043efa9b123)
Signed-off-by: Cheng Pan <[email protected]>
---
.../spark/sql/kyuubi/SparkDatasetHelper.scala | 38 ++++++++++++++++++++++
.../operation/SparkArrowbasedOperationSuite.scala | 33 +++++++++++++++++++
2 files changed, 71 insertions(+)
diff --git
a/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
b/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
index 10b178324..6bd96676f 100644
---
a/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
+++
b/externals/kyuubi-spark-sql-engine/src/main/scala/org/apache/spark/sql/kyuubi/SparkDatasetHelper.scala
@@ -24,7 +24,9 @@ import org.apache.spark.internal.Logging
import org.apache.spark.network.util.{ByteUnit, JavaUtils}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
+import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.execution.{CollectLimitExec, LocalTableScanExec,
SparkPlan, SQLExecution}
+import org.apache.spark.sql.execution.{CollectLimitExec, SparkPlan,
SQLExecution}
import org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec
import org.apache.spark.sql.execution.arrow.{ArrowConverters,
KyuubiArrowConverters}
import org.apache.spark.sql.functions._
@@ -51,6 +53,9 @@ object SparkDatasetHelper extends Logging {
doCollectLimit(collectLimit)
case collectLimit: CollectLimitExec if collectLimit.limit < 0 =>
executeArrowBatchCollect(collectLimit.child)
+ // TODO: replace with pattern match once we drop Spark 3.1 support.
+ case command: SparkPlan if isCommandResultExec(command) =>
+ doCommandResultExec(command)
case localTableScan: LocalTableScanExec =>
doLocalTableScan(localTableScan)
case plan: SparkPlan =>
@@ -177,6 +182,17 @@ object SparkDatasetHelper extends Logging {
result.toArray
}
+ def doCommandResultExec(command: SparkPlan): Array[Array[Byte]] = {
+ KyuubiArrowConverters.toBatchIterator(
+ // TODO: replace with `command.rows.iterator` once we drop Spark 3.1
support.
+ commandResultExecRowsMethod.invoke[Seq[InternalRow]](command).iterator,
+ command.schema,
+ SparkSession.active.sessionState.conf.arrowMaxRecordsPerBatch,
+ maxBatchSize,
+ -1,
+ SparkSession.active.sessionState.conf.sessionLocalTimeZone).toArray
+ }
+
def doLocalTableScan(localTableScan: LocalTableScanExec): Array[Array[Byte]]
= {
localTableScan.longMetric("numOutputRows").add(localTableScan.rows.size)
KyuubiArrowConverters.toBatchIterator(
@@ -232,6 +248,28 @@ object SparkDatasetHelper extends Logging {
.getOrElse(0)
}
+ private def isCommandResultExec(sparkPlan: SparkPlan): Boolean = {
+ // scalastyle:off line.size.limit
+ // the CommandResultExec was introduced in SPARK-35378 (Spark 3.2), after
SPARK-35378 the
+ // physical plan of runnable command is CommandResultExec.
+ // for instance:
+ // ```
+ // scala> spark.sql("show tables").queryExecution.executedPlan
+ // res0: org.apache.spark.sql.execution.SparkPlan =
+ // CommandResult <empty>, [namespace#0, tableName#1, isTemporary#2]
+ // +- ShowTables [namespace#0, tableName#1, isTemporary#2],
V2SessionCatalog(spark_catalog), [default]
+ //
+ // scala > spark.sql("show tables").queryExecution.executedPlan.getClass
+ // res1: Class[_ <: org.apache.spark.sql.execution.SparkPlan] = class
org.apache.spark.sql.execution.CommandResultExec
+ // ```
+ // scalastyle:on line.size.limit
+ sparkPlan.getClass.getName ==
"org.apache.spark.sql.execution.CommandResultExec"
+ }
+
+ private lazy val commandResultExecRowsMethod = DynMethods.builder("rows")
+ .impl("org.apache.spark.sql.execution.CommandResultExec")
+ .build()
+
/**
* refer to org.apache.spark.sql.Dataset#withAction(), assign a new
execution id for arrow-based
* operation, so that we can track the arrow-based queries on the UI tab.
diff --git
a/externals/kyuubi-spark-sql-engine/src/test/scala/org/apache/kyuubi/engine/spark/operation/SparkArrowbasedOperationSuite.scala
b/externals/kyuubi-spark-sql-engine/src/test/scala/org/apache/kyuubi/engine/spark/operation/SparkArrowbasedOperationSuite.scala
index 27310992f..057d8c6ff 100644
---
a/externals/kyuubi-spark-sql-engine/src/test/scala/org/apache/kyuubi/engine/spark/operation/SparkArrowbasedOperationSuite.scala
+++
b/externals/kyuubi-spark-sql-engine/src/test/scala/org/apache/kyuubi/engine/spark/operation/SparkArrowbasedOperationSuite.scala
@@ -278,6 +278,39 @@ class SparkArrowbasedOperationSuite extends
WithSparkSQLEngine with SparkDataTyp
assert(numStages == 1)
}
+ test("CommandResultExec should not trigger job") {
+ val listener = new JobCountListener
+ val l2 = new SQLMetricsListener
+ val nodeName = spark.sql("SHOW
TABLES").queryExecution.executedPlan.getClass.getName
+ if (SPARK_ENGINE_RUNTIME_VERSION < "3.2") {
+ assert(nodeName ==
"org.apache.spark.sql.execution.command.ExecutedCommandExec")
+ } else {
+ assert(nodeName == "org.apache.spark.sql.execution.CommandResultExec")
+ }
+ withJdbcStatement("table_1") { statement =>
+ statement.executeQuery(s"CREATE TABLE table_1 (id bigint) USING parquet")
+ withSparkListener(listener) {
+ withSparkListener(l2) {
+ val resultSet = statement.executeQuery("SHOW TABLES")
+ assert(resultSet.next())
+ assert(resultSet.getString("tableName") == "table_1")
+ KyuubiSparkContextHelper.waitListenerBus(spark)
+ }
+ }
+ }
+
+ if (SPARK_ENGINE_RUNTIME_VERSION < "3.2") {
+ // Note that before Spark 3.2, a LocalTableScan SparkPlan will be
submitted, and the issue of
+ // preventing LocalTableScan from triggering a job submission was
addressed in [KYUUBI #4710].
+ assert(l2.queryExecution.executedPlan.getClass.getName ==
+ "org.apache.spark.sql.execution.LocalTableScanExec")
+ } else {
+ assert(l2.queryExecution.executedPlan.getClass.getName ==
+ "org.apache.spark.sql.execution.CommandResultExec")
+ }
+ assert(listener.numJobs == 0)
+ }
+
test("LocalTableScanExec should not trigger job") {
val listener = new JobCountListener
withJdbcStatement("view_1") { statement =>
{kind=link}
{kind=link}