bgawrych commented on a change in pull request #20533:
URL: https://github.com/apache/incubator-mxnet/pull/20533#discussion_r694668740
##########
File path: src/operator/nn/mkldnn/mkldnn_base-inl.h
##########
@@ -305,17 +305,28 @@ inline static mkldnn::memory::desc GetMemDesc(const
NDArray& arr, int dtype = -1
return mkldnn::memory::desc{dims, get_mkldnn_type(dtype),
mkldnn::memory::format_tag::any};
}
-inline static mkldnn::memory::desc GetFCWeightDesc(const NDArray& arr, int
dtype = -1) {
+inline static bool ChooseBRGEMMImpl(mkldnn::memory::dims weight_dims, size_t
batch_size) {
+ // Conditions based on measurement results done on CLX8280
+ // https://github.com/apache/incubator-mxnet/pull/20533
+ return weight_dims[0] % 64 == 0 && weight_dims[1] % 64 == 0 &&
weight_dims[0] >= 1024 &&
Review comment:
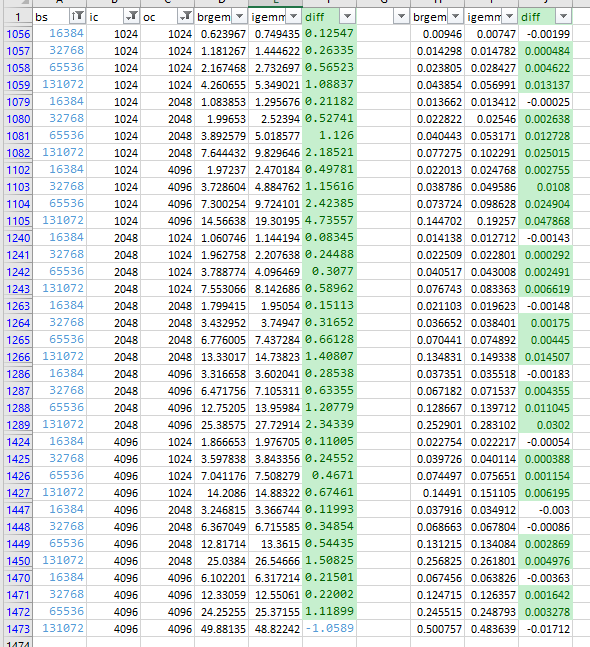
Running 100 iterations of benchmark which allows to utilize caching
mechanism shows that BRGEMM is faster in majority of cases (1043/1472) - when
running only single iteration with specific shape it's only (423/1472)
Below are results for current conditions (left 100 iterations / right 1
iteration) and also I'm attaching spreadsheet
[brgemm_igemm_cmp_2.xlsx](https://github.com/apache/incubator-mxnet/files/7038007/brgemm_igemm_cmp_2.xlsx)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}