This is an automated email from the ASF dual-hosted git repository.
indhub pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-mxnet.git
The following commit(s) were added to refs/heads/master by this push:
new 54ebc5d Fix image classification scripts and Improve Fp16 tutorial
(#11533)
54ebc5d is described below
commit 54ebc5db7967fe023d987796dd098ecf8a65e507
Author: Rahul Huilgol <[email protected]>
AuthorDate: Sat Jul 28 17:26:10 2018 -0700
Fix image classification scripts and Improve Fp16 tutorial (#11533)
* fix bugs and improve tutorial
* improve logging
* update benchmark_score
* Update float16.md
* update link to dmlc web data
* fix train cifar and add random mirroring
* set aug defaults
* fix whitespace
* fix typo
---
docs/faq/float16.md | 12 ++++++++--
example/gluon/data.py | 15 ++++++------
example/image-classification/benchmark_score.py | 9 ++++---
example/image-classification/common/data.py | 31 ++++++++++++++++++-------
example/image-classification/fine-tune.py | 4 ++--
example/image-classification/train_cifar10.py | 8 ++++++-
example/image-classification/train_imagenet.py | 12 ++++++++--
src/io/image_aug_default.cc | 2 +-
8 files changed, 66 insertions(+), 27 deletions(-)
diff --git a/docs/faq/float16.md b/docs/faq/float16.md
index cbb308f..b4cd97b 100644
--- a/docs/faq/float16.md
+++ b/docs/faq/float16.md
@@ -102,9 +102,17 @@ python fine-tune.py --network resnet --num-layers 50
--pretrained-model imagenet
```
## Example training results
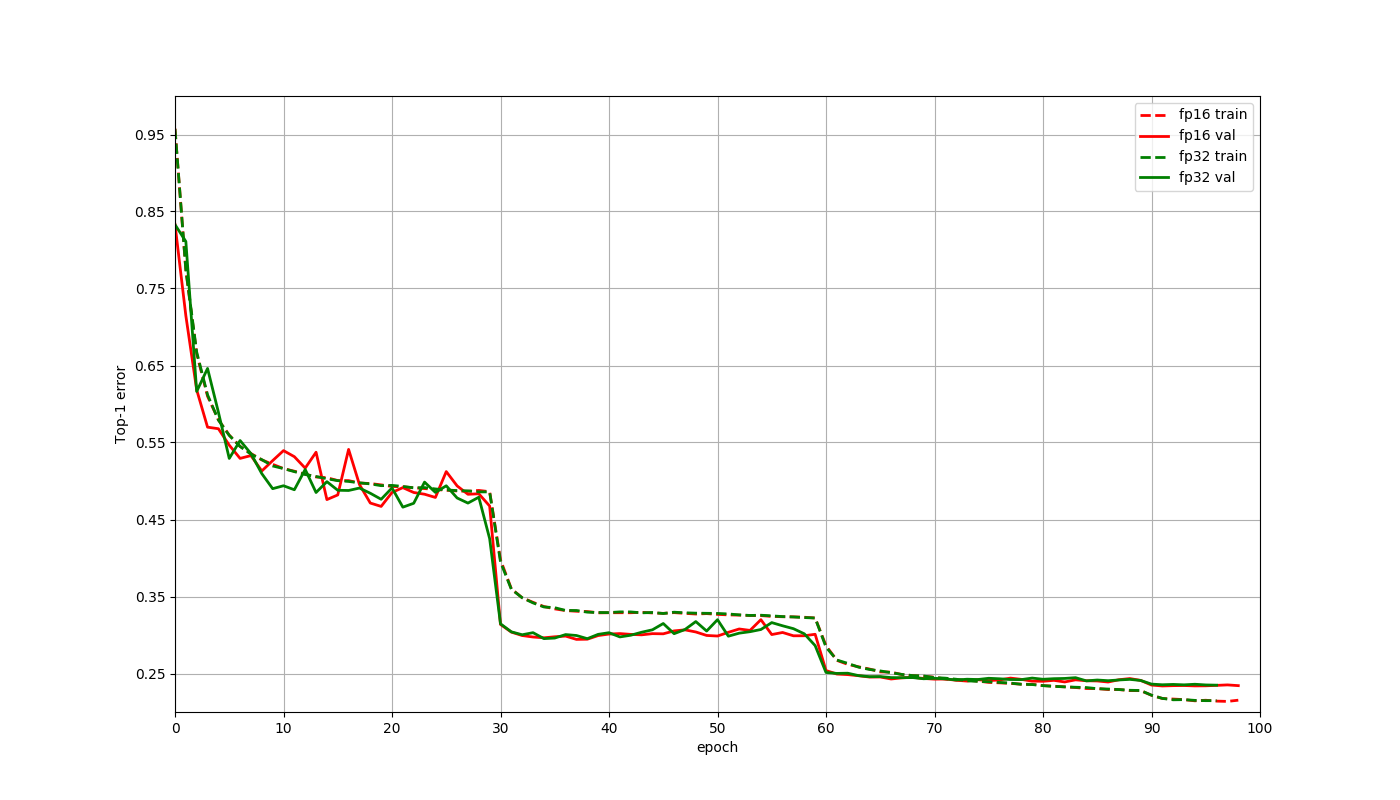
-Here is a plot to compare the training curves of a Resnet50 v1 network on the
Imagenet 2012 dataset. These training jobs ran for 95 epochs with a batch size
of 1024 using a learning rate of 0.4 decayed by a factor of 1 at epochs
30,60,90 and used Gluon. The only changes made for the float16 job when
compared to the float32 job were that the network and data were cast to
float16, and the multi-precision mode was used for optimizer. The final
accuracies at 95th epoch were **76.598% for flo [...]
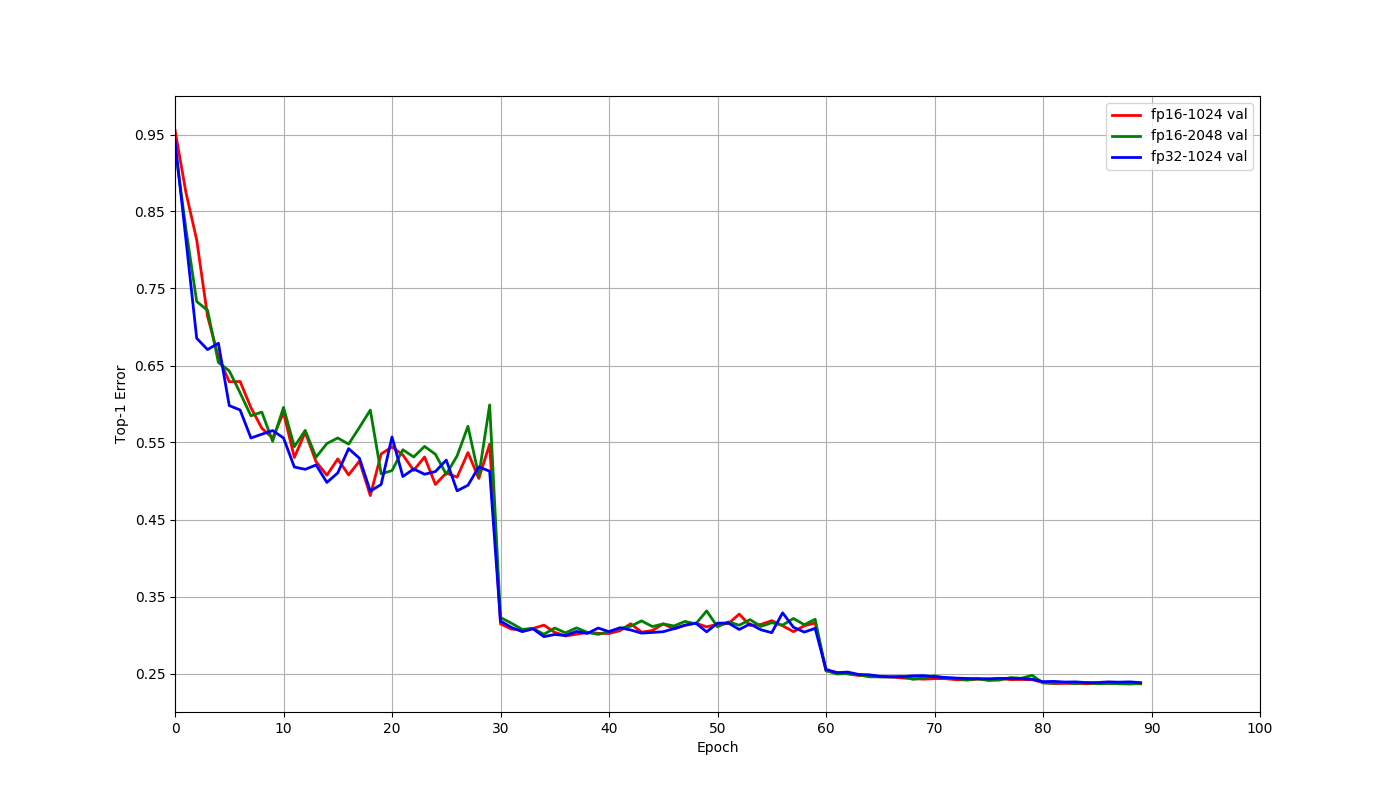
+Let us consider training a Resnet50 v1 model on the Imagenet 2012 dataset. For
this model, the GPU memory usage is close to the capacity of V100 GPU with a
batch size of 128 when using float32. Using float16 allows the use of 256 batch
size. Shared below are results using 8 V100 GPUs on a AWS p3.16x large
instance. Let us compare the three scenarios that arise here: float32 with 1024
batch size, float16 with 1024 batch size and float16 with 2048 batch size.
These jobs trained for 90 epoc [...]
-
+Batch size | Data type | Top 1 Validation accuracy | Time to train | Speedup |
+--- | --- | --- | --- | --- |
+1024 | float32 | 76.18% | 11.8 hrs | 1 |
+1024 | float16 | 76.34% | 7.3 hrs | 1.62x |
+2048 | float16 | 76.29% | 6.5 hrs | 1.82x |
+
+
+
+The differences in accuracies above are within normal random variation, and
there is no reason to expect float16 to have better accuracy than float32 in
general. As the plot indicates training behaves similarly for these cases, even
though we didn't have to change any other hyperparameters. We can also see from
the table that using float16 helps train faster through faster computation with
float16 as well as allowing the use of larger batch sizes.
## Things to keep in mind
diff --git a/example/gluon/data.py b/example/gluon/data.py
index 6aa5316..f855c90 100644
--- a/example/gluon/data.py
+++ b/example/gluon/data.py
@@ -21,6 +21,7 @@ import os
import random
import tarfile
import logging
+import tarfile
logging.basicConfig(level=logging.INFO)
import mxnet as mx
@@ -92,9 +93,10 @@ def get_imagenet_iterator(root, batch_size, num_workers,
data_shape=224, dtype='
def get_caltech101_data():
url =
"https://s3.us-east-2.amazonaws.com/mxnet-public/101_ObjectCategories.tar.gz";
dataset_name = "101_ObjectCategories"
- if not os.path.isdir("data"):
+ data_folder = "data"
+ if not os.path.isdir(data_folder):
os.makedirs(data_folder)
- tar_path = mx.gluon.utils.download(url, path='data')
+ tar_path = mx.gluon.utils.download(url, path=data_folder)
if (not os.path.isdir(os.path.join(data_folder, "101_ObjectCategories")) or
not os.path.isdir(os.path.join(data_folder,
"101_ObjectCategories_test"))):
tar = tarfile.open(tar_path, "r:gz")
@@ -110,18 +112,17 @@ def get_caltech101_iterator(batch_size, num_workers,
dtype):
# resize the shorter edge to 224, the longer edge will be greater or
equal to 224
resized = mx.image.resize_short(image, 224)
# center and crop an area of size (224,224)
- cropped, crop_info = mx.image.center_crop(resized, 224)
+ cropped, crop_info = mx.image.center_crop(resized, (224, 224))
# transpose the channels to be (3,224,224)
transposed = mx.nd.transpose(cropped, (2, 0, 1))
- image = mx.nd.cast(image, dtype)
- return image, label
+ return transposed, label
training_path, testing_path = get_caltech101_data()
dataset_train = ImageFolderDataset(root=training_path, transform=transform)
dataset_test = ImageFolderDataset(root=testing_path, transform=transform)
- train_data = mx.gluon.data.DataLoader(dataset_train, batch_size,
shuffle=True, num_workers=num_workers)
- test_data = mx.gluon.data.DataLoader(dataset_test, batch_size,
shuffle=False, num_workers=num_workers)
+ train_data = DataLoader(dataset_train, batch_size, shuffle=True,
num_workers=num_workers)
+ test_data = DataLoader(dataset_test, batch_size, shuffle=False,
num_workers=num_workers)
return DataLoaderIter(train_data), DataLoaderIter(test_data)
class DummyIter(mx.io.DataIter):
diff --git a/example/image-classification/benchmark_score.py
b/example/image-classification/benchmark_score.py
index 0d47d85..05e4b48 100644
--- a/example/image-classification/benchmark_score.py
+++ b/example/image-classification/benchmark_score.py
@@ -79,13 +79,16 @@ if __name__ == '__main__':
logging.info('network: %s', net)
for d in devs:
logging.info('device: %s', d)
+ logged_fp16_warning = False
for b in batch_sizes:
for dtype in ['float32', 'float16']:
if d == mx.cpu() and dtype == 'float16':
#float16 is not supported on CPU
continue
- elif net in ['inception-bn', 'alexnet'] and dt ==
'float16':
- logging.info('{} does not support float16'.format(net))
+ elif net in ['inception-bn', 'alexnet'] and dtype ==
'float16':
+ if not logged_fp16_warning:
+ logging.info('Model definition for {} does not
support float16'.format(net))
+ logged_fp16_warning = True
else:
speed = score(network=net, dev=d, batch_size=b,
num_batches=10, dtype=dtype)
- logging.info('batch size %2d, dtype %s image/sec: %f',
b, dtype, speed)
+ logging.info('batch size %2d, dtype %s, images/sec:
%f', b, dtype, speed)
diff --git a/example/image-classification/common/data.py
b/example/image-classification/common/data.py
index c1dfcf5..df1449b 100755
--- a/example/image-classification/common/data.py
+++ b/example/image-classification/common/data.py
@@ -28,8 +28,12 @@ def add_data_args(parser):
data.add_argument('--data-val-idx', type=str, default='', help='the index
of validation data')
data.add_argument('--rgb-mean', type=str, default='123.68,116.779,103.939',
help='a tuple of size 3 for the mean rgb')
+ data.add_argument('--rgb-std', type=str, default='1,1,1',
+ help='a tuple of size 3 for the std rgb')
data.add_argument('--pad-size', type=int, default=0,
help='padding the input image')
+ data.add_argument('--fill-value', type=int, default=127,
+ help='Set the padding pixels value to fill_value')
data.add_argument('--image-shape', type=str,
help='the image shape feed into the network, e.g.
(3,224,224)')
data.add_argument('--num-classes', type=int, help='the number of classes')
@@ -67,11 +71,18 @@ def add_data_aug_args(parser):
aug.add_argument('--max-random-scale', type=float, default=1,
help='max ratio to scale')
aug.add_argument('--min-random-scale', type=float, default=1,
- help='min ratio to scale, should >= img_size/input_shape.
otherwise use --pad-size')
+ help='min ratio to scale, should >= img_size/input_shape.
'
+ 'otherwise use --pad-size')
aug.add_argument('--max-random-area', type=float, default=1,
help='max area to crop in random resized crop, whose
range is [0, 1]')
aug.add_argument('--min-random-area', type=float, default=1,
help='min area to crop in random resized crop, whose
range is [0, 1]')
+ aug.add_argument('--min-crop-size', type=int, default=-1,
+ help='Crop both width and height into a random size in '
+ '[min_crop_size, max_crop_size]')
+ aug.add_argument('--max-crop-size', type=int, default=-1,
+ help='Crop both width and height into a random size in '
+ '[min_crop_size, max_crop_size]')
aug.add_argument('--brightness', type=float, default=0,
help='brightness jittering, whose range is [0, 1]')
aug.add_argument('--contrast', type=float, default=0,
@@ -84,13 +95,6 @@ def add_data_aug_args(parser):
help='whether to use random resized crop')
return aug
-def set_resnet_aug(aug):
- # standard data augmentation setting for resnet training
- aug.set_defaults(random_crop=0, random_resized_crop=1)
- aug.set_defaults(min_random_area=0.08)
- aug.set_defaults(max_random_aspect_ratio=4./3.,
min_random_aspect_ratio=3./4.)
- aug.set_defaults(brightness=0.4, contrast=0.4, saturation=0.4,
pca_noise=0.1)
-
class SyntheticDataIter(DataIter):
def __init__(self, num_classes, data_shape, max_iter, dtype):
self.batch_size = data_shape[0]
@@ -137,6 +141,7 @@ def get_rec_iter(args, kv=None):
else:
(rank, nworker) = (0, 1)
rgb_mean = [float(i) for i in args.rgb_mean.split(',')]
+ rgb_std = [float(i) for i in args.rgb_std.split(',')]
train = mx.io.ImageRecordIter(
path_imgrec = args.data_train,
path_imgidx = args.data_train_idx,
@@ -144,6 +149,9 @@ def get_rec_iter(args, kv=None):
mean_r = rgb_mean[0],
mean_g = rgb_mean[1],
mean_b = rgb_mean[2],
+ std_r = rgb_std[0],
+ std_g = rgb_std[1],
+ std_b = rgb_std[2],
data_name = 'data',
label_name = 'softmax_label',
data_shape = image_shape,
@@ -151,13 +159,15 @@ def get_rec_iter(args, kv=None):
rand_crop = args.random_crop,
max_random_scale = args.max_random_scale,
pad = args.pad_size,
- fill_value = 127,
+ fill_value = args.fill_value,
random_resized_crop = args.random_resized_crop,
min_random_scale = args.min_random_scale,
max_aspect_ratio = args.max_random_aspect_ratio,
min_aspect_ratio = args.min_random_aspect_ratio,
max_random_area = args.max_random_area,
min_random_area = args.min_random_area,
+ min_crop_size = args.min_crop_size,
+ max_crop_size = args.max_crop_size,
brightness = args.brightness,
contrast = args.contrast,
saturation = args.saturation,
@@ -181,6 +191,9 @@ def get_rec_iter(args, kv=None):
mean_r = rgb_mean[0],
mean_g = rgb_mean[1],
mean_b = rgb_mean[2],
+ std_r = rgb_std[0],
+ std_g = rgb_std[1],
+ std_b = rgb_std[2],
resize = 256,
data_name = 'data',
label_name = 'softmax_label',
diff --git a/example/image-classification/fine-tune.py
b/example/image-classification/fine-tune.py
index 2a0c0ec..719fa86 100644
--- a/example/image-classification/fine-tune.py
+++ b/example/image-classification/fine-tune.py
@@ -54,8 +54,8 @@ if __name__ == "__main__":
parser.add_argument('--layer-before-fullc', type=str, default='flatten0',
help='the name of the layer before the last fullc
layer')\
- # use less augmentations for fine-tune
- data.set_data_aug_level(parser, 1)
+ # use less augmentations for fine-tune. by default here it uses no
augmentations
+
# use a small learning rate and less regularizations
parser.set_defaults(image_shape='3,224,224',
num_epochs=30,
diff --git a/example/image-classification/train_cifar10.py
b/example/image-classification/train_cifar10.py
index 7eb56eb..f449aad 100644
--- a/example/image-classification/train_cifar10.py
+++ b/example/image-classification/train_cifar10.py
@@ -31,6 +31,11 @@ def download_cifar10():
download_file('http://data.mxnet.io/data/cifar10/cifar10_train.rec',
fnames[0])
return fnames
+def set_cifar_aug(aug):
+ aug.set_defaults(rgb_mean='125.307,122.961,113.8575',
rgb_std='51.5865,50.847,51.255')
+ aug.set_defaults(random_mirror=1, pad=4, fill_value=0, random_crop=1)
+ aug.set_defaults(min_random_size=32, max_random_size=32)
+
if __name__ == '__main__':
# download data
(train_fname, val_fname) = download_cifar10()
@@ -41,7 +46,8 @@ if __name__ == '__main__':
fit.add_fit_args(parser)
data.add_data_args(parser)
data.add_data_aug_args(parser)
- data.set_data_aug_level(parser, 2)
+ # uncomment to set standard cifar augmentations
+ # set_cifar_aug(parser)
parser.set_defaults(
# network
network = 'resnet',
diff --git a/example/image-classification/train_imagenet.py
b/example/image-classification/train_imagenet.py
index a90b6ae..0835f5d 100644
--- a/example/image-classification/train_imagenet.py
+++ b/example/image-classification/train_imagenet.py
@@ -23,6 +23,14 @@ from common import find_mxnet, data, fit
from common.util import download_file
import mxnet as mx
+def set_imagenet_aug(aug):
+ # standard data augmentation setting for imagenet training
+ aug.set_defaults(rgb_mean='123.68,116.779,103.939',
rgb_std='58.393,57.12,57.375')
+ aug.set_defaults(random_crop=0, random_resized_crop=1, random_mirror=1)
+ aug.set_defaults(min_random_area=0.08)
+ aug.set_defaults(max_random_aspect_ratio=4./3.,
min_random_aspect_ratio=3./4.)
+ aug.set_defaults(brightness=0.4, contrast=0.4, saturation=0.4,
pca_noise=0.1)
+
if __name__ == '__main__':
# parse args
parser = argparse.ArgumentParser(description="train imagenet-1k",
@@ -30,8 +38,8 @@ if __name__ == '__main__':
fit.add_fit_args(parser)
data.add_data_args(parser)
data.add_data_aug_args(parser)
- # uncomment to set standard augmentation for resnet training
- # data.set_resnet_aug(parser)
+ # uncomment to set standard augmentations for imagenet training
+ # set_imagenet_aug(parser)
parser.set_defaults(
# network
network = 'resnet',
diff --git a/src/io/image_aug_default.cc b/src/io/image_aug_default.cc
index 5b28aa1..bea2e2c 100644
--- a/src/io/image_aug_default.cc
+++ b/src/io/image_aug_default.cc
@@ -178,7 +178,7 @@ struct DefaultImageAugmentParam : public
dmlc::Parameter<DefaultImageAugmentPara
DMLC_DECLARE_FIELD(rotate).set_default(-1.0f)
.describe("Rotate by an angle. If set, it overwrites the
``max_rotate_angle`` option.");
DMLC_DECLARE_FIELD(fill_value).set_default(255)
- .describe("Set the padding pixes value into ``fill_value``.");
+ .describe("Set the padding pixels value to ``fill_value``.");
DMLC_DECLARE_FIELD(data_shape)
.set_expect_ndim(3).enforce_nonzero()
.describe("The shape of a output image.");
{kind=link}
{kind=link}