daveliepmann commented on a change in pull request #14769: [Clojure] Add Fine
Tuning Sentence Pair Classification BERT Example
URL: https://github.com/apache/incubator-mxnet/pull/14769#discussion_r280033222
##########
File path: contrib/clojure-package/examples/bert/fine-tune-bert.ipynb
##########
@@ -0,0 +1,512 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Fine-tuning Sentence Pair Classification with BERT\n",
+ "\n",
+ "**This tutorial is based off of the Gluon NLP one here
https://gluon-nlp.mxnet.io/examples/sentence_embedding/bert.html**\n";,
+ "\n",
+ "Pre-trained language representations have been shown to improve many
downstream NLP tasks such as question answering, and natural language
inference. To apply pre-trained representations to these tasks, there are two
strategies:\n",
+ "\n",
+ "feature-based approach, which uses the pre-trained representations as
additional features to the downstream task.\n",
+ "fine-tuning based approach, which trains the downstream tasks by
fine-tuning pre-trained parameters.\n",
+ "While feature-based approaches such as ELMo [3] (introduced in the
previous tutorial) are effective in improving many downstream tasks, they
require task-specific architectures. Devlin, Jacob, et al proposed BERT [1]
(Bidirectional Encoder Representations from Transformers), which fine-tunes
deep bidirectional representations on a wide range of tasks with minimal
task-specific parameters, and obtained state- of-the-art results.\n",
+ "\n",
+ "In this tutorial, we will focus on fine-tuning with the pre-trained BERT
model to classify semantically equivalent sentence pairs. Specifically, we
will:\n",
+ "\n",
+ "load the state-of-the-art pre-trained BERT model and attach an additional
layer for classification,\n",
+ "process and transform sentence pair data for the task at hand, and\n",
+ "fine-tune BERT model for sentence classification.\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Preparation\n",
+ "\n",
+ "To run this tutorial locally, in the example directory:\n",
+ "\n",
+ "1. Get the model and supporting data by running `get_bert_data.sh`. \n",
+ "2. This Jupyter Notebook uses the lein-jupyter plugin to be able to
execute Clojure code in project setting. The first time that you run it you
will need to install the kernel with`lein jupyter install-kernel`. After that
you can open the notebook in the project directory with `lein jupyter
notebook`."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Load requirements\n",
+ "\n",
+ "We need to load up all the namespace requires"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 1,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [],
+ "source": [
+ "(ns bert.bert-sentence-classification\n",
+ " (:require [bert.util :as bert-util]\n",
+ " [clojure-csv.core :as csv]\n",
+ " [clojure.java.shell :refer [sh]]\n",
+ " [clojure.string :as string]\n",
+ " [org.apache.clojure-mxnet.callback :as callback]\n",
+ " [org.apache.clojure-mxnet.context :as context]\n",
+ " [org.apache.clojure-mxnet.dtype :as dtype]\n",
+ " [org.apache.clojure-mxnet.eval-metric :as eval-metric]\n",
+ " [org.apache.clojure-mxnet.io :as mx-io]\n",
+ " [org.apache.clojure-mxnet.layout :as layout]\n",
+ " [org.apache.clojure-mxnet.module :as m]\n",
+ " [org.apache.clojure-mxnet.ndarray :as ndarray]\n",
+ " [org.apache.clojure-mxnet.optimizer :as optimizer]\n",
+ " [org.apache.clojure-mxnet.symbol :as sym]))\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "collapsed": true
+ },
+ "source": [
+ "# Use the Pre-trained BERT Model\n",
+ "\n",
+ "In this tutorial we will use the pre-trained BERT model that was exported
from GluonNLP via the `scripts/bert/staticbert/static_export_base.py`. For
convenience, the model has been downloaded for you by running the
`get_bert_data.sh` file in the root directory of this example."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Get BERT\n",
+ "\n",
+ "Let’s first take a look at the BERT model architecture for sentence pair
classification below:\n",
+ "\n",
+ "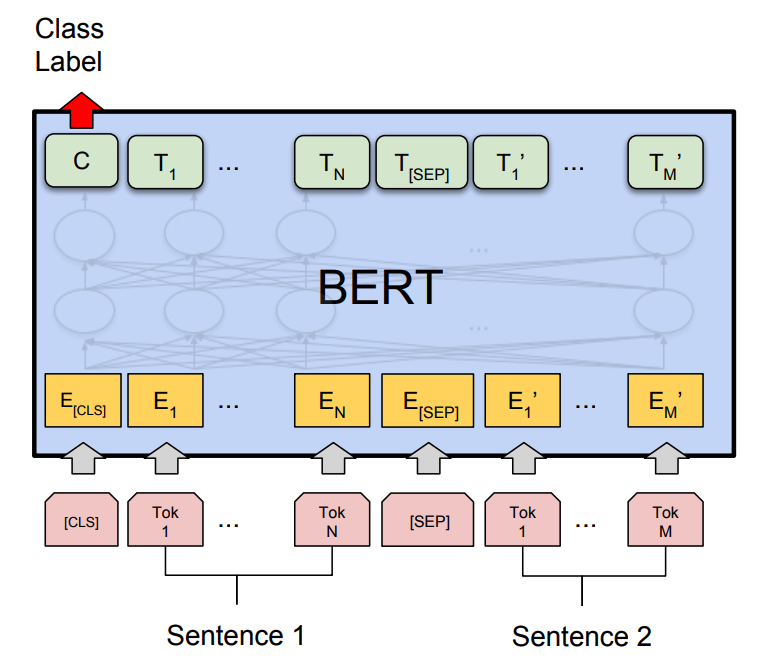\n",
+ "\n",
+ "where the model takes a pair of sequences and pools the representation of
the first token in the sequence. Note that the original BERT model was trained
for masked language model and next sentence prediction tasks, which includes
layers for language model decoding and classification. These layers will not be
used for fine-tuning sentence pair classification.\n",
+ "\n",
+ "Let's load the pre-trained BERT using the module API in MXNet."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 2,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "#'bert.bert-sentence-classification/bert-base"
+ ]
+ },
+ "execution_count": 2,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "(def model-path-prefix \"data/static_bert_base_net\")\n",
+ ";; epoch number of the model\n",
+ "(def epoch 0)\n",
+ ";; the vocabulary used in the model\n",
+ "(def vocab (bert-util/get-vocab))\n",
+ ";; the input question\n",
+ ";; the maximum length of the sequence\n",
+ "(def seq-length 128)\n",
+ "\n",
+ "(def bert-base (m/load-checkpoint {:prefix model-path-prefix :epoch 0}))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Model Definition for Sentence Pair Classification\n",
+ "\n",
+ "Now that we have loaded the BERT model, we only need to attach an
additional layer for classification. We can do this by defining a fine tune
model from the symbol of the base BERT model."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 3,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [
+ {
+ "data": {
+ "text/plain": [
+ "#'bert.bert-sentence-classification/model-sym"
+ ]
+ },
+ "execution_count": 3,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
+ "source": [
+ "(defn fine-tune-model\n",
+ " \"msymbol: the pretrained network symbol\n",
+ " num-classes: the number of classes for the fine-tune datasets\n",
+ " dropout: the dropout rate\"\n",
+ " [msymbol {:keys [num-classes dropout]}]\n",
+ " (as-> msymbol data\n",
+ " (sym/dropout {:data data :p dropout})\n",
+ " (sym/fully-connected \"fc-finetune\" {:data data :num-hidden
num-classes})\n",
+ " (sym/softmax-output \"softmax\" {:data data})))\n",
+ "\n",
+ "(def model-sym (fine-tune-model (m/symbol bert-base) {:num-classes 2
:dropout 0.1}))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Data Preprocessing for BERT\n",
+ "\n",
+ "## Dataset\n",
+ "\n",
+ "For demonstration purpose, we use the dev set of the Microsoft Research
Paraphrase Corpus dataset. The file is named ‘dev.tsv’ and was downloaded as
part of the data script. Let’s take a look at the raw dataset."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Quality\t#1 ID\t#2 ID\t#1 String\t#2 String\n",
+ "1\t1355540\t1355592\tHe said the foodservice pie business doesn 't fit
the company 's long-term growth strategy .\t\" The foodservice pie business
does not fit our long-term growth strategy .\n",
+ "0\t2029631\t2029565\tMagnarelli said Racicot hated the Iraqi regime and
looked forward to using his long years of training in the war .\tHis wife said
he was \" 100 percent behind George Bush \" and looked forward to using his
years of training in the war .\n",
+ "0\t487993\t487952\tThe dollar was at 116.92 yen against the yen , flat
on the session , and at 1.2891 against the Swiss franc , also flat .\tThe
dollar was at 116.78 yen JPY = , virtually flat on the session , and at 1.2871
against the Swiss franc CHF = , down 0.1 percent .\n",
+ "1\t1989515\t1989458\tThe AFL-CIO is waiting until October to decide if
it will endorse a candidate .\tThe AFL-CIO announced Wednesday that it will
decide in October whether to endorse a candidate before the primaries .\n",
+ "\n"
+ ]
+ }
+ ],
+ "source": [
+ "(-> (sh \"head\" \"-n\" \"5\" \"data/dev.tsv\") \n",
+ " :out\n",
+ " println)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The file contains 5 columns, separated by tabs (i.e. ‘\n",
+ "\n",
+ "\\t\n",
+ "‘). The first line of the file explains each of these columns: 0. the
label indicating whether the two sentences are semantically equivalent 1. the
id of the first sentence in this sample 2. the id of the second sentence in
this sample 3. the content of the first sentence 4. the content of the second
sentence\n",
+ "\n",
+ "For our task, we are interested in the 0th, 3rd and 4th columns. "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "metadata": {
+ "collapsed": false
+ },
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "He said the foodservice pie business doesn 't fit the company 's
long-term growth strategy .\n",
Review comment:
Just removing quotes seems to work on this example. I'm spot-checking the
rest.
```clojure
(csv/parse-csv (string/replace (slurp "data/dev.tsv") "\"" "")
:delimiter \tab
:strict true)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
With regards,
Apache Git Services
{kind=link}