larroy commented on a change in pull request #15109: [DOC] refine autograd docs URL: https://github.com/apache/incubator-mxnet/pull/15109#discussion_r307563953
########## File path: docs/api/python/autograd/autograd.md ########## @@ -76,7 +82,63 @@ Detailed tutorials are available in Part 1 of [the MXNet gluon book](http://gluon.mxnet.io/). +# Higher order gradient + +Some operators support higher order gradients. Meaning that you calculate the gradient of the +gradient. For this the operator's backward must be as well differentiable. Some operators support +differentiating multiple times, and others two, most just once. + +For calculating higher order gradients, we can use the `mx.autograd.grad` function while recording +and then call backward, or call `mx.autograd.grad` two times. If we do the later is important that +the first call uses `create_graph=True` and `retain_graph=True` and the second call uses +`create_graph=False` and `retain_graph=True`. Otherwise we will not get the results that we want. If Review comment: @apeforest @kshitij12345 I don't think pasting the graph here helps because it doesn't change, it's only related to attached autograd to arrays from my point of view. There's a difference, you can retain and not create if you want to calculate gradients again. If you reuse the outputs in the graph you should create. The details are in imperative.cc Backward, but they have in fact slightly different behaviour. You can try yourself, but if you use heads=x_grad_grad in the third gradient, you need to have create=True in the previous call. 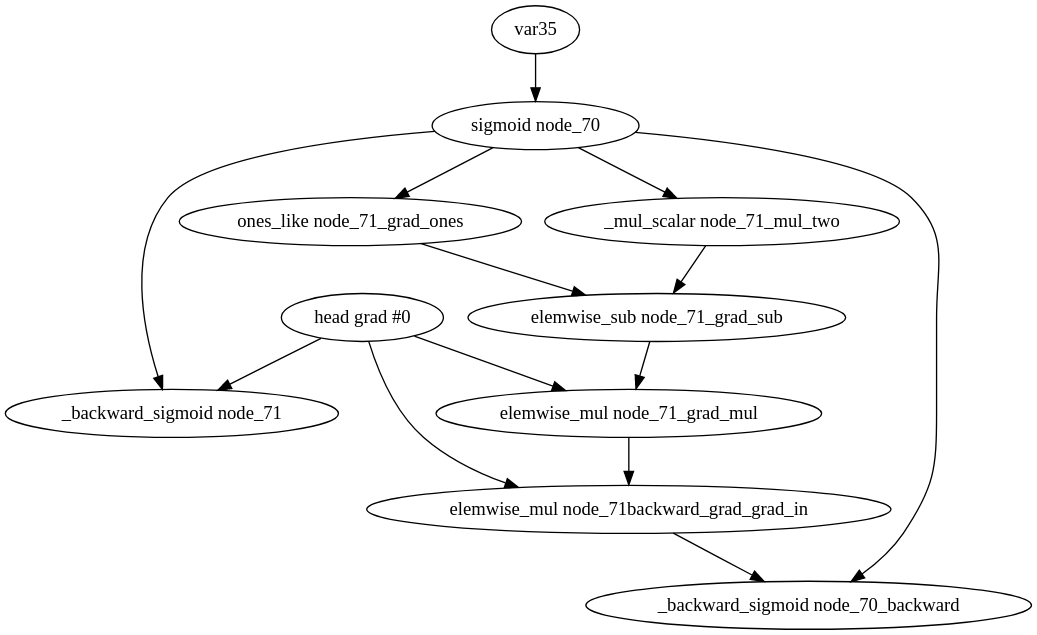 ``` with autograd.record(): y = op(x) x_grad = autograd.grad(heads=y, variables=x, head_grads=y_grad, create_graph=True, retain_graph=True)[0] x_grad_grad = autograd.grad(heads=x_grad, variables=x, head_grads=head_grad_grads, create_graph=False, retain_graph=True)[0] x_grad_grad_grad = autograd.grad(heads=x_grad, variables=x, head_grads=head_grad_grads, create_graph=False, retain_graph=True)[0] #x_grad.backward(head_grad_grads) ``` In any case I don't see this is a reason to block the PR. ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services
{kind=link}