TakaHiR07 opened a new issue, #19169: URL: https://github.com/apache/pulsar/issues/19169
### Search before asking - [X] I searched in the [issues](https://github.com/apache/pulsar/issues) and found nothing similar. ### Version server and client version: pulsar-2.9.4 ### Minimal reproduce step do txn produce and txn consume on a 200-partition topic by pulsar-perf. The throughput is 10MB/s, batchSize is 10, subscriptionType is exclusive. It is a tailing read, consuming the latest message produce config is :`-txn -nmt 1000 -time 0 -s 1024 -i 60 -bm 10 -b 1000 -bb 4194304 -r 10000 -mk random -threads 3`; consume config is : `-txn -nmt 2000 -time 0 -i 60 -s sub_test_txn_p200 -ss sub_test_txn_p200 -sp Latest -ioThreads 1 -n 1` ### What did you expect to see? The cpu usage should not be so high when it is exclusive subscription, tailing read and txn consume. Actually the tailing read should not consume more resource than catchup read. ### What did you see instead? 1. when it is tailing read and exclusive subscription and txn consume, the cpu usage is 80%. But when it turn to catchup read, the cpu usage is 45%. 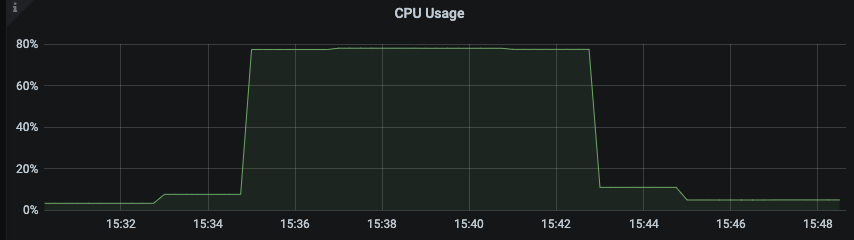 2. Throughput would not influence the cpu usage, but if topic have more partition, the cpu usage is higher. I add some log in code and have found the cpu is consumed in "broker-topic-workers", which is mostly do PersistentDispatcherSingleActiveConsumer#readEntriesComplete and PersistentDispatcherSingleActiveConsumer#dispatchEntriesToConsumer.  I also add a metric of thread pool "broker-topic-workers", and found that when do catchup read 2. Throughput would not influence the cpu usage, but if topic have more partition, the cpu usage is higher. 3. I add some log in code and have found the cpu is consumed in "broker-topic-workers", which is mostly do PersistentDispatcherSingleActiveConsumer#readEntriesComplete and PersistentDispatcherSingleActiveConsumer#dispatchEntriesToConsumer.  4. I also add a metric of thread pool "broker-topic-workers", and found that when do catchup read. the completed task in thread pool is total 150K * 8 thread = 1200K/s, while the read throughput is 10K message/s. There are too many task in this thread pool. 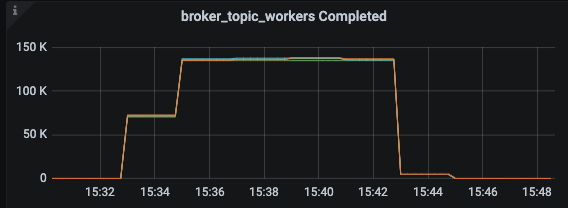 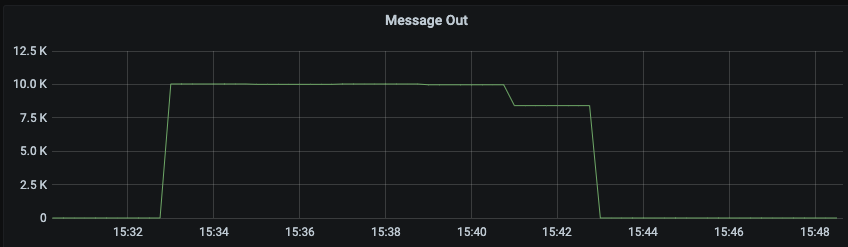 ### Anything else? Although tested in 2.9.4, I guess this problem may also occur in master branch. ### Are you willing to submit a PR? - [ ] I'm willing to submit a PR! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}