lhotari opened a new issue #8229: URL: https://github.com/apache/pulsar/issues/8229
Pulsar Broker 2.6.1 enters an infinite loop between these stack frames: ``` org.apache.bookkeeper.mledger.impl.OpReadEntry.checkReadCompletion org.apache.bookkeeper.mledger.impl.ManagedLedgerImpl.internalReadFromLedger org.apache.bookkeeper.mledger.impl.ManagedLedgerImpl.asyncReadEntries org.apache.bookkeeper.mledger.impl.OpReadEntry.lambda$checkReadCompletion$1 ``` **To Reproduce** There aren't currently known steps to reproduce the issue in an isolated way. This happens in a load test on a 3 broker, 3 bookie, 3 zk cluster running in Openshift/k8s. The load test covers 7500 Pulsar topics which are read with short-living readers, there aren't any subscriptions. The topics are created in a namespace with retention policy of 10080 minutes. Each topic contains up to 5 messages. **Additional context** Pulsar Slack thread with lots of details at https://apache-pulsar.slack.com/archives/C5Z4T36F7/p1602159831227900 **Possible reason** This is the first few lines of code in [OpRead.checkReadCompletion](https://github.com/apache/pulsar/blob/8b7b60e6507ae4a961e66f10e920fc1e3808df41/managed-ledger/src/main/java/org/apache/bookkeeper/mledger/impl/OpReadEntry.java#L133) method: ```java void checkReadCompletion() { if (entries.size() < count && cursor.hasMoreEntries()) { // We still have more entries to read from the next ledger, schedule a new async operation if (nextReadPosition.getLedgerId() != readPosition.getLedgerId()) { cursor.ledger.startReadOperationOnLedger(nextReadPosition, OpReadEntry.this); } ``` The usage of `cursor.hasMoreEntries()` seems invalid here. In the table of data extracted from the heap dump by using Eclipse MAT OQL, I can see that `OpRead.readPosition.ledgerId != OpRead.cursor.readPosition.ledgerId` and `OpRead.nextReadPosition.ledgerId != OpRead.cursor.ledger.lastConfirmedEntry.ledgerId` (cursor write position) . 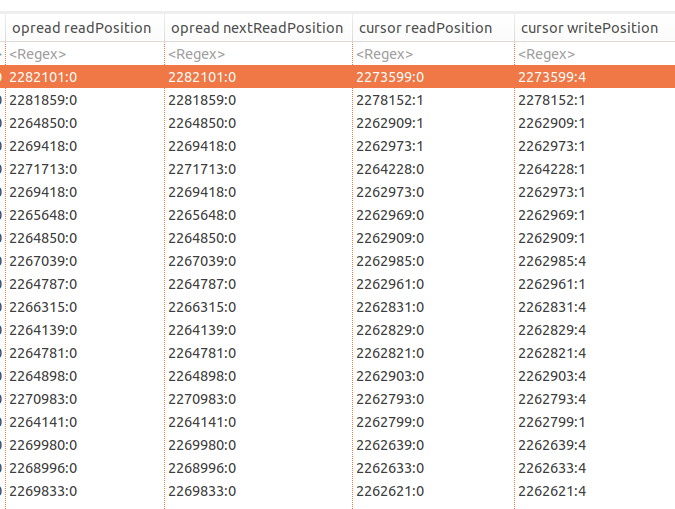 Therefore, when `cursor.hasMoreEntries()` is called, it should take `OpRead.readPosition.getLedgerId()` into account. Currently the ledgerId is ignored and in the case of when cursor really has more entries in a different ledgerId, it will lead to an infinite loop. The code in `checkReadCompletion` has another problem. The call to `[cursor.ledger.startReadOperationOnLedger](https://github.com/apache/pulsar/blob/e2fbf31ff34f2aa94276ab6103c73cec23849c1b/managed-ledger/src/main/java/org/apache/bookkeeper/mledger/impl/ManagedLedgerImpl.java#L1844)` might call `opReadEntry.readEntriesFailed`. ```java PositionImpl startReadOperationOnLedger(PositionImpl position, OpReadEntry opReadEntry) { Long ledgerId = ledgers.ceilingKey(position.getLedgerId()); if (null == ledgerId) { opReadEntry.readEntriesFailed(new ManagedLedgerException.NoMoreEntriesToReadException("The ceilingKey(K key) method is used to return the " + "least key greater than or equal to the given key, or null if there is no such key"), null); } ``` The problem here is that there isn't currently a way to signal this back to `checkReadCompletion` method and the execution will continue calling startReadOperationOnLedger again later on in the same `checkReadCompletion` method call. **Possibly related issue** #8078 has a similar stack trace in a screenshot of a threaddump. That also has a symptom of high CPU consumption. ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}