Jason918 opened a new issue #12812: URL: https://github.com/apache/pulsar/issues/12812
**Is your enhancement request related to a problem? Please describe.** Optimize zookeeper client performance for loading amounts of topics. Our use case is described here #12651 . **Describe the solution you'd like** Introduce [zk multi ops](http://zookeeper.apache.org/doc/r3.7.0/apidocs/zookeeper-server/org/apache/zookeeper/ZooKeeper.html#multi-java.lang.Iterable-org.apache.zookeeper.AsyncCallback.MultiCallback-java.lang.Object-) to optimize the zk client performance. Our team did a perf test on the zk multi ops, here is the result. |Op type | Single Op (ops/s) | Batch 8 with Multi (ops/s)| |--|--|--| |Create|25k|60k| |Write(with pre-created 5M nodes)|25|90k| |Read|25k|200k| Here is the settings: - Single node size : 256 Bytes - zk server version: 3.4.6 - Cpu usage: 6/40 on core bare metal server. - OS : centos 7 - ZK server disk: 8TB Nvme SSD It's clear that with multi, we can achieve much more performance with the same cpu usage, especially with read operations. The basic idea of implementation will be add two queue (one for read ops and one for write ops) in PulsarZooKeeperClient, all zk ops will be added to the queue first, and a background thread will batch theses requests and sends to zk server in one "multi op". This implementation will introduce the follow parameter in broker configs: - **enableAutoBatchZookeeperOps**, this feature is optional, as it may increase metadata latency with small amount of topics. - **autoBatchZookeeperOpsMaxNum** and **autoBatchZookeeperOpsMaxDelayMills** Just like auto batching parameters in pulsar producer. Limits the max number of ops in one batch and max delay time to wait for a batch. **Describe alternatives you've considered** Add a ratelimiter for topic loading, see #12651 **Additional context** Here is the explanation why multi ops works much better with read ops. - All write ops needs to go through a single thread processor in master. And we have reach the max qps in the previous perf test. - Read ops can be handled by slave nodes. We can get more qps with larger batch size in the previous perf test. Here is the flame graph of the bottleneck thread in master. 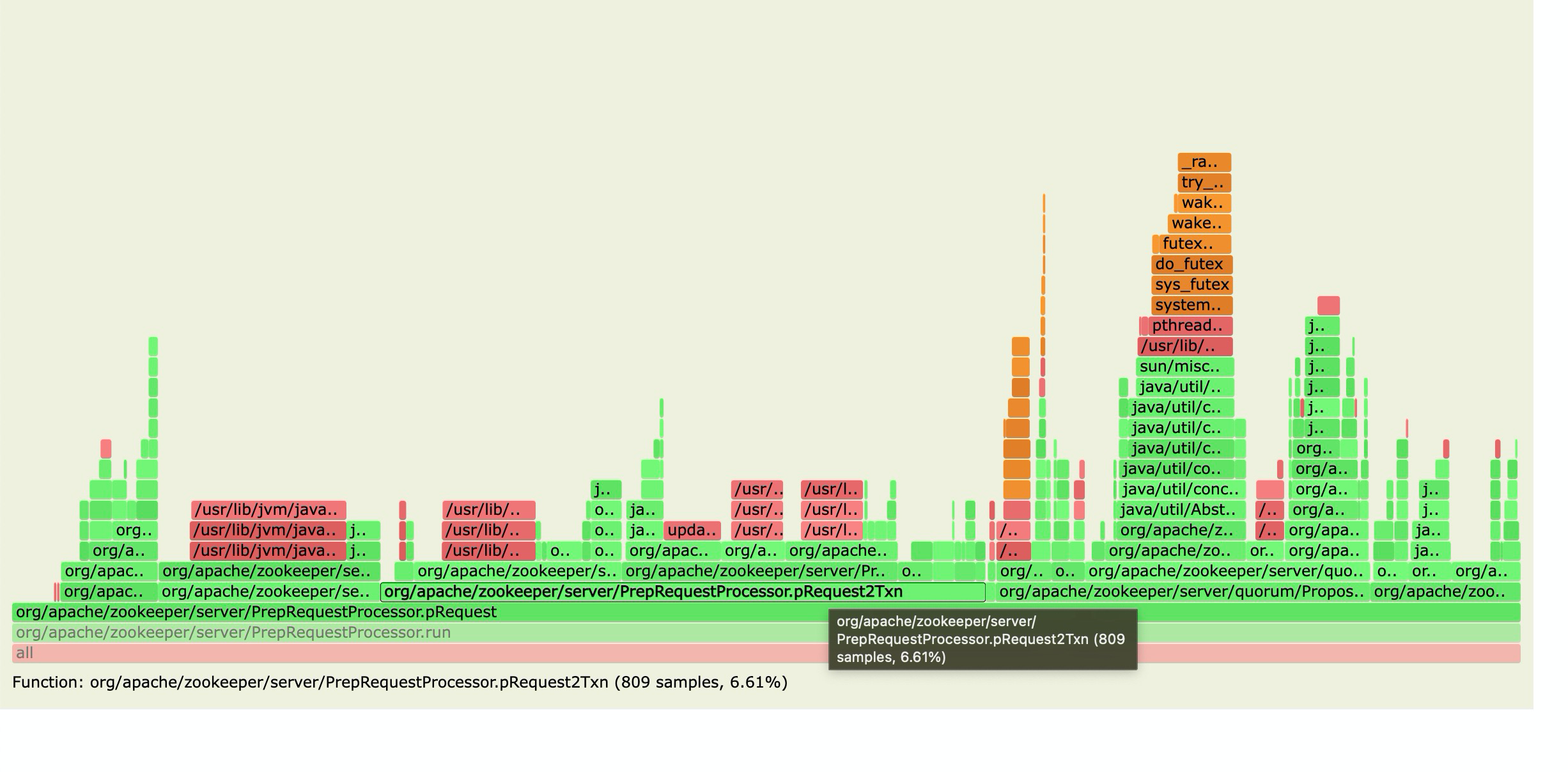 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}