TheR1sing3un opened a new issue, #7163: URL: https://github.com/apache/rocketmq/issues/7163
### Before Creating the Enhancement Request - [X] I have confirmed that this should be classified as an enhancement rather than a bug/feature. ### Summary # DLedger Controller Performance Optimization ## Overview Based on the performance bottleneck issues in the current mode of RocketMQ, implement a high-performance, highly maintainable new version of the Controller module that provides low-latency master-slave switching capabilities, improves the upper limit of the number of `brokers` that a Controller node is responsible for, and uses the high-performance optimization of `DLedger`. ## Background In Apache/RocketMQ V5.x, a new Controller mode was introduced, which provides an independent Controller component for providing master-slave switching capabilities for broker replicas in a master-slave architecture. The Controller uses `Openmessaging/DLedger` as the metadata multi-replica consensus protocol library. `DLedger` uses the `Raft` protocol to ensure consistency, and based on this feature, Controller nodes can provide linearized read and write features for metadata. The current implementation of the Controller version can operate stably and provide election functions for broker replica groups with few nodes. However, in the current scenario, if a small number of broker replica groups share one Controller group or even one broker replica group monopolizes one Controller group, the scale of the Controller group we need to maintain in a large cluster will be very large, which will be a great challenge for the utilization of server resources and daily operation and maintenance capabilities. Therefore, for the above-mentioned problems, we can adopt a deployment mode similar to the current `Name Server`, where multiple broker replica groups or even multiple clusters share one Controller group. At this time, the performance of the Controller architecture in this large-scale scenario becomes a challenge. The current Controller architecture is still in a state of low performance and low utilization of machine resources, so we need to upgrade the Controller architecture for large-scale scenarios with high performance. ## Current Architecture Problem Analysis ### Inappropriate use of `DLedger State Machine` 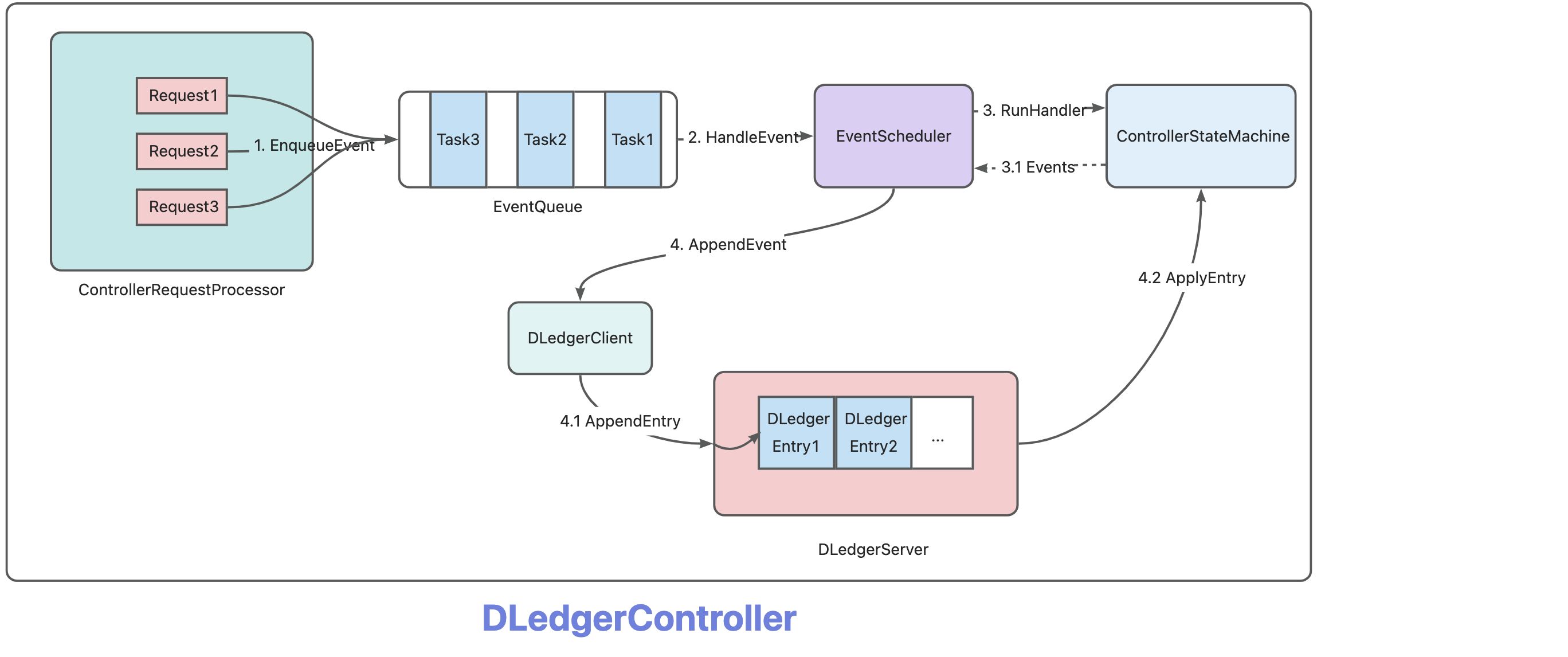 > The above diagram shows the entire process of a request processing on the broker side, which is also the process of using the state machine on the Controller side. In the current architecture, if a broker initiates an `ElectMaster` request, the Controller will have the following process: 1. First, package the request into a `Task` and put it into the `EventQueue`. 2. Wait for the `EventScheduler` to pull the `Task`. 3. As shown in step 3 above, we will process the `Task`. Currently, it is an `ElectMaster` request, so we will access the state machine and determine a new Master based on the state machine data and the current heartbeat data, and generate an `ElectMasterEvent`(a state machine modification event). 4. As shown in step 4 above, we will serialize the `ElectMasterEvent` into a `DLedger Entry` and write it to the `DLedgerServer` through the `DLedgerClient`. 5. When the `DLedgerEntry` is committed, it is applied to the upper-level state machine, the `ElectMasterEvent` is deserialized, and the state machine is modified based on the event content. > In the above request processing flow, there are the following problems #### Multiple accesses to the state machine for a single request In the above `ElectMaster` request, we first accessed the state machine data to determine the state machine modification event to be generated, then wrote the modification event into the state machine through the `DLedgerClient`, and then waited for the event to be applied to the state machine and modified the state machine. So we made two requests to access the state machine data, and ensured data consistency between the two requests by processing them synchronously with a single-threaded `EventScheduler`. However, in theory, accessing the state machine before deciding to modify its data is fundamentally an incorrect use of the multi-replica state machine model based on the Raft protocol. #### The generation of state machine modification events depends on real-time external state that is not part of a state machine When the Controller processes an `ElectMaster` request, it participates in the election of a new Master based on the current heartbeat data of the `Broker` nodes recorded by the Controller's `HeartbeatManager` component. Therefore, the generation of a state machine modification event, such as the `ElectMasterEvent` event in this example, is affected by real-time data outside of the state machine, that is, the current data of `HeartbeatManager`. Thus, we introduce a time dimension into the factors that generate an event. If we need to apply a state modification event to multiple replicas and ensure correct results, we should not introduce real-time data as a factor in generating an event, because the application of a state machine modification event or a `DLedger Entry` on the state machine can only be related to the current data of the state machine, otherwise consistency cannot be guaranteed. #### Single-threaded synchronous blocking writes to DLedgerServer Currently, requests for Controller state modification and access are all placed in the `EventQueue` first, and then executed synchronously and blocked by a single-threaded `EventScheduler`. For example, the `ElectMaster` request mentioned above will first access the state machine, determine the current election event based on the current state machine state and the data of `HeartManager`, and then write the event to `DLedgerServer`, waiting for `DLedgerServer` to correctly apply the event before ending the current event processing and synchronously pulling the next event in the EventQueue for processing again. Therefore, this request processing is completely single-threaded, synchronous and blocked, to ensure consistency of request processing. However, `DLedgerServer` itself can ensure linear consistency processing of concurrent requests, and this single-threaded request processing model is inefficient and useless. When the concurrency of requests is high, only one thread processes requests, and the power of `multi-core CPU` cannot be utilized. ### Not utilizing the unique features of DLedger The current version of `DLedger` is being iterated towards high-performance optimization, and will implement three major features: `State Machine Snapshots`, `Linearizable Read`, and `Follower Read`. These features will enhance the read and write performance of `DLedger` from multiple perspectives, but the Controller module has not applied these features. #### State Machine Snapshot The `State Machine Snapshot` feature mainly generates a `snapshot` of the current state machine data when a `snapshot threshold` is reached, and deletes `DLedger Entrys` that has been covered by the `snapshot`. This feature can bring three improvements to the Controller side: ##### Log Compression By compressing logs, we can reduce the disk space occupied by the Controller, which can help to optimize the overall storage usage of the system. ##### Fast Restart By taking a `snapshot` of the state machine, we can reduce the time needed for log replay when a Controller node restarts. This can help to quickly restore normal operation and provide uninterrupted services. ##### Fast replica data synchronization By sending a state machine `snapshot` to severely lagging Controller followers, we can quickly synchronize their data with the primary node, which can help to reduce the delay caused by the log lag of multiple followers in the Controller replica group. ### Linearizable Read Although the Controller does not currently require strict linearizable read and write operations, it is still desirable to provide this capability to users for a more rigorous consistency guarantee. `DLedger` has already implemented linearizable read, which can ensure linear consistency between multiple client requests and responses even in the face of concurrent requests. However, the current Controller architecture only uses single-threaded client request-response to ensure linear consistency, without leveraging DLedger's consistency optimizations for multiple client requests. The `DLedger` community will implement the `ReadIndex Read` and `Lease Read` algorithms to greatly improve the linear read performance of the state machine. Fully integrating the `ReadIndex Read` and `Lease Read` algorithms into the Controller will result in the following improvements: 1. By using `ReadIndex Read` and `Lease Read` to reduce the number of read log writes, we can reduce disk I/O consumption, decrease disk space usage, and reduce network I/O consumption, as reading logs requires synchronization between replicas over the network. 2. Reduced broker-side read latency: When the Controller is responsible for a large cluster, metadata pull requests from brokers can be large, putting significant pressure on the Controller node's read requests. The above optimizations can greatly reduce the length of a single read request chain, allowing read requests to be quickly processed. #### Follower Read When implementing `ReadIndex Read` or `Lease Read` in `DLedger`, we can provide the ability to read from followers, which can significantly reduce the pressure on the leader node and even allow it to focus solely on state machine modification while using followers for state machine reads. ### Synchronous Blocking Request Handling Chain The current Controller request processing chain is entirely synchronous and blocking. Let's take the `ElectMaster` request processing as an example. > Full processing chain for an ElectMaster request 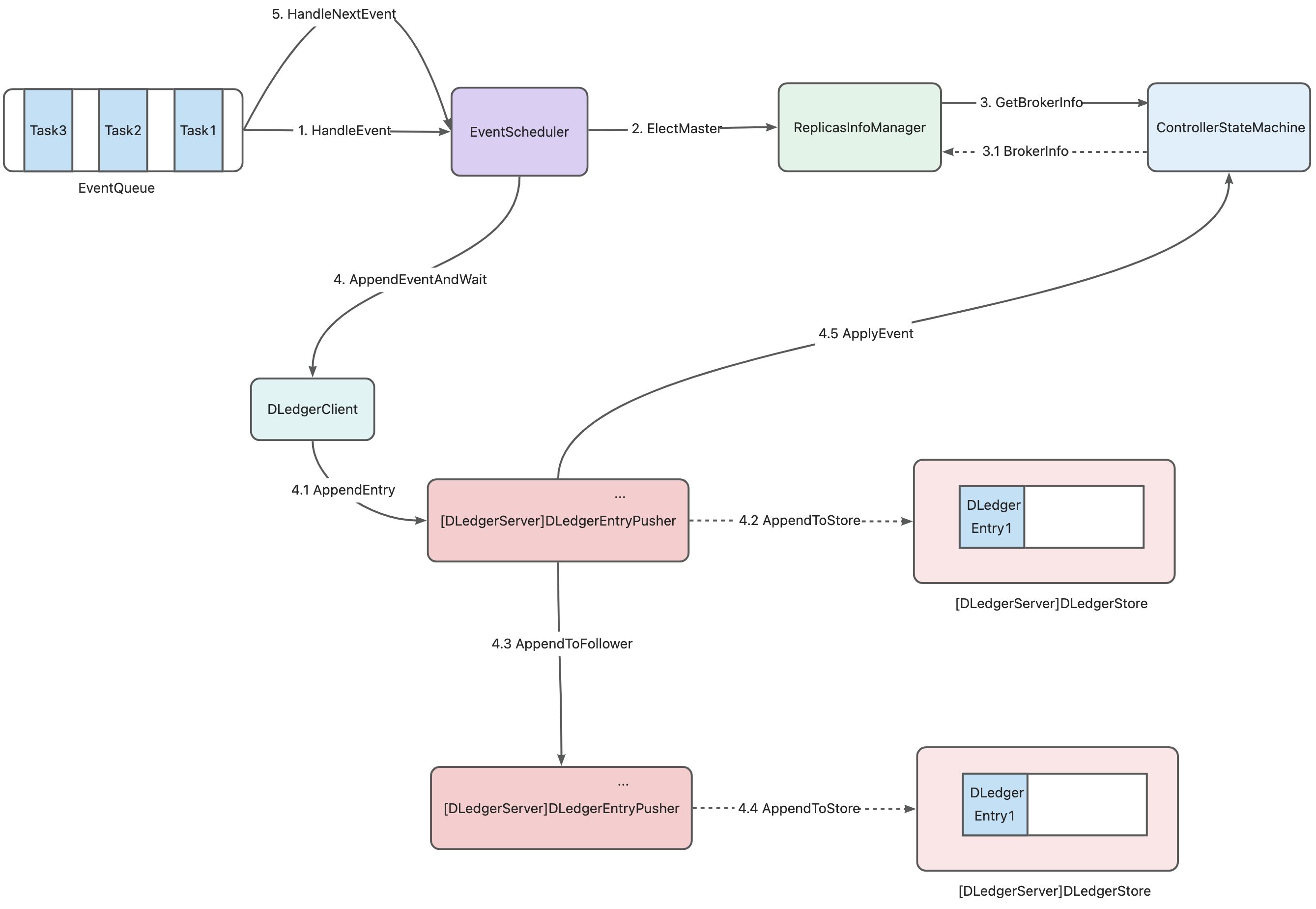 The above figure shows the entire process of handling an `ElectMaster` request, all of which occur synchronously and blockingly. 1. In step-1 `HandlerEvent`, we use a single-threaded `EventScheduler` for synchronous processing.  2. Step-2 and 3 are executed by the same thread as shown in the above diagram. 3. In step-4, we use this thread to write the state machine write events generated in step-3. Although the processing is handed over to the `DLedgerServer`, the `DLedgerServer` only uses the current thread as a client to perform the write operation. We also use synchronous wait in the code for the write to succeed, so step-4 is also executed synchronously.  4. Therefore, in step-4, `DLedgerServer` writes data to `DLedgerStore`, sends the data to the `Follower` node, the `Follower` node writes it and waits for the Quorum to write it successfully. All of the above steps are executed synchronously. However, in theory, we can use concurrent execution in multiple places, such as writing data to `DLedgerServer`. `DLedger` itself supports concurrent writes, so it is not necessary to synchronize and wait for execution with a single thread at this point, but multiple business processing threads can write concurrently. ### Single-threaded Scheduled Task Currently, the Controller module has many scheduled tasks, including `Heartbeat Timeout Checks`, `Inactive Master Detection`, etc., but all scheduled tasks are executed by a single thread, and each execution requires accessing all data, such as the `Inactive Master Detection`. This requires synchronous scanning of the entire state machine each time it is executed, which may result in performance issues when the scale of the responsible `Broker` is large. This is because scanning all data in the entire state machine with a single thread synchronously is inefficient, so there may be some performance bottlenecks in this area. ## Optimized Implementation Plan ### Refactor the usage of DLedger on the Controller side #### Controller-side events All operations that access or modify the state machine on the Controller side will be encapsulated into an `Event`, resulting in the following types of `Event`: > Write Events - `AlterSyncStateSetEvent`: modifies `SyncStateSet` - `ElectMasterEvent`: elects a new `Master` - `ApplyBrokerId`: `Broker` notifies Controller to apply BrokerId - `RegisterBroker`: `Broker` try to modify the `BrokerAddress` recorded in the state machine upon successful registration - `CleanBrokerData`: `Admin` clears the information of a specified `Broker` > Consistent Read Events - `GetNextBrokerIdEvent`: retrieves the next `BrokerId` to be assigned - `GetReplicaInfoEvent`: `Broker` retrieves current replica information > Unsafe-Read Events - `GetSyncStateSetEvent`: `Admin` retrieves the current replica synchronization status directly - `ScanNeedReelectBrokerSets`: `DLedgerController` periodically scans all `Broker` replica groups that need to be re-elected. The above events can be classified into three categories: - `Write Events`: These events need to be written through `DLedger` to achieve fault tolerance and reliability within the Controller replica group. After the data is written, as long as the number of `unavailable nodes` is not greater than the `Controller replica group size / 2`, the written events can be guaranteed not to be lost. - `Consistent Read Events`: Since the `Write Events` are written through `DLedger`, the consistency between the write events has been ensured. We can also access the state machine data through `DLedger`'s consistent read mode to ensure `linear consistency` between `Read` and `Write` events. This is suitable for scenarios that require strict `linear consistency` access among multiple `brokers`. - `Unsafe-Read Events`: These events access the state machine directly for data reading, without ensuring the consistency between read and write events. Therefore, they are suitable for events that do not require high consistency, such as `Admin` commands. All events, except for `ElectMasterEvent`, have the same processing logic as the current one (the processing logic remains unchanged, but the timing of processing is changed to when `DLedger` executes a modification operation similar to `CAS`). > Refactor the processing logic of `ElectMasterEvent` In the above text, we mentioned that if we want an event to be `Apply` to the state machine at different nodes and times, we can ensure that the state machines of the Controller replica group are in the same state after `Apply`. Then the processing logic of this event can only depend on the same factors, which can be the data carried by the event itself or the data of the current state machine. If the original processing logic of `ElectMasterEvent` directly handled like other `Write Events` and processed after `Apply` without modifying any logic, then we cannot guarantee the constraint that the event relies on the same factors as mentioned above.   Since `ElectMasterEvent` is based on the heartbeat information in the current node's `HeartbeatManager` as the basis for the election, the simplest example is that when the node applies this event, the data in its `HeartbeatManager` is completely different from that of the master node. At this time, the election result is also likely to be different. Therefore, the processing logic of our `ElectMasterEvent` needs to be refactored to the following logic: 1. When generating the `ElectMasterEvent`, retrieve the heartbeat information of the required `Broker` replica group from the `HeartbeatManager` and include it as data in the `ElectMasterEvent`. 2. When the state machine `Apply` this event, use the heartbeat data from the `ElectMasterEvent` as the data source for the original processing logic of `BrokerLiveInfoGetter` and `BrokerValidPredicate`. 3. Keep all other logic consistent with the original implementation. #### Event Processing Architecture 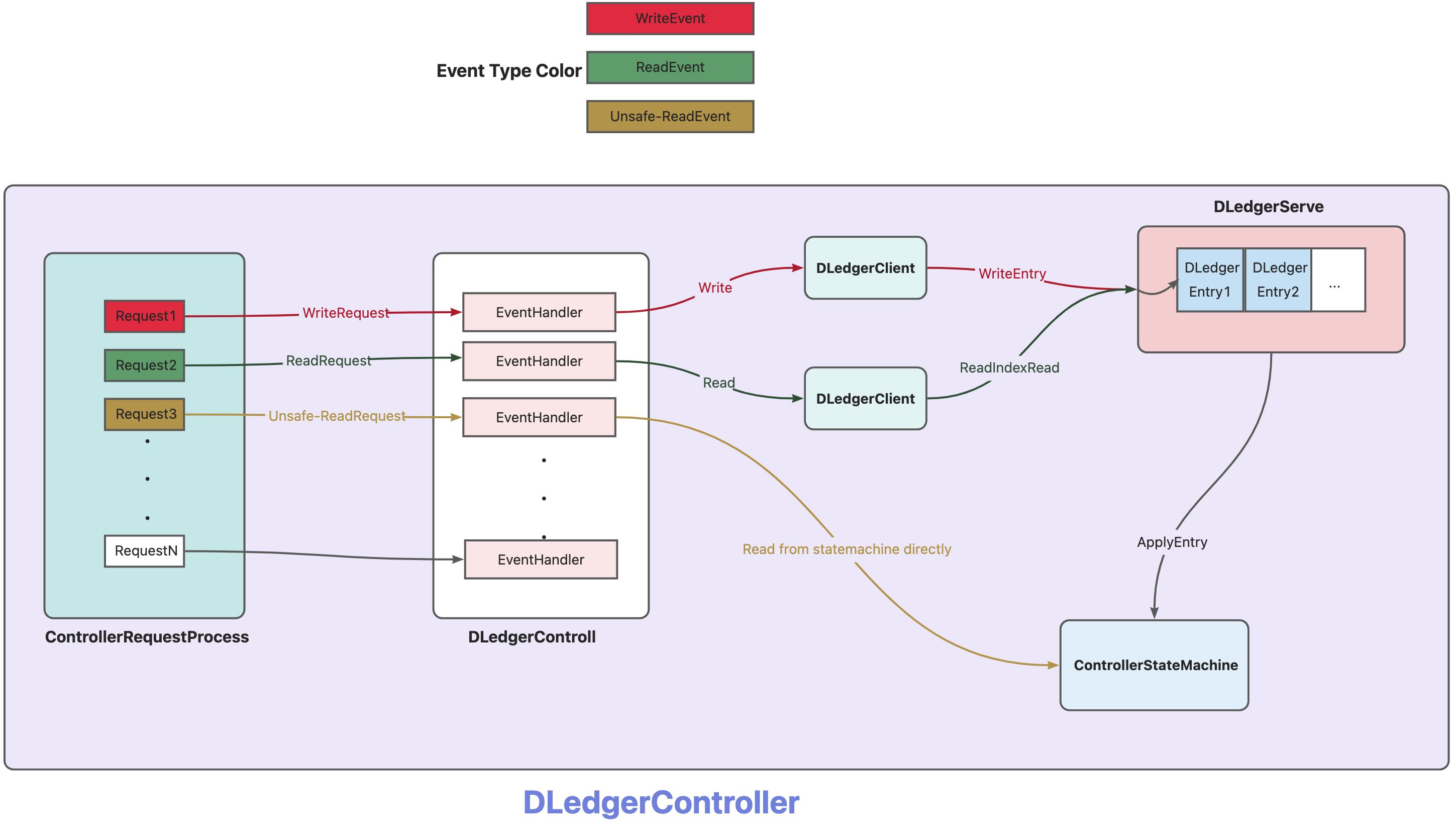 All request processing threads are uniformly managed by the `ControllerRequestProcessor` thread pool. The processing flows for the three different types of events are slightly different: > WriteEvent 1. Collect and organize the data required for the event processing logic, and package the request event as an actual state machine event, such as `ElectMasterEvent`, which includes the current heartbeat information in the `HearbeatManager`. 2. Send the event as a `Write Event` to `DLedgerServer` through `DLedgerClient` and wait for it to be submitted. 3. When the event is submitted, the state machine will pull the log of the written event, deserialize it back to the original event structure, and modify the state machine data according to the corresponding logic. > ReadEvent 1. Package the event as an actual state machine read event, and use a `ReadClojure` for the actual reading logic based on the `DLedger` reading specification. 2. Send the event as a read event to `DLedgerServer` through `DLedgerClient`. 3. When the event is submitted and applied to the state machine, the first step packaged `ReadClojure` will be called for the actual state machine data reading logic. > Unsafe-ReadEvent 1. Directly retrieve the corresponding data from the state machine according to the request event. ### New Request Interaction Architecture After refactoring the event processing architecture mentioned above, we have the prerequisites to use various high-performance optimizations provided by `DLedger`. Therefore, we can implement the following new request interaction architecture.  The above diagram shows the request interaction architecture between `Broker`/`Admin`/`Controller`. #### Broker Request There are two types of requests from `Broker`, one is `WriteRequest` and the other is `ReadRequest`. Both of these need to ensure linear consistency for read and write operations. Therefore, `ReadRequest` can only be a `ReadEvent` and not an `Unsafe-ReadEvent`. ##### WriteRequest `WriteRequest` on the `Broker` side corresponds to `WriteEvent` on the Controller side. According to `DLedger` constraints, i.e., `Raft` protocol constraints, all write events can only be performed by the Leader node. Therefore, all `WriteRequests` from the Broker side are processed by the Controller-Leader. ##### ReadRequest `ReadRequest` on the `Broker` side corresponds to `ReadEvent` on the Controller side, and it needs to go through `DLedger` for consensus reading to ensure consistency. In the case where `Follower-Read` mode is enabled on the Controller side, Broker can send all `ReadRequests` to Controller-Follower to reduce the request processing pressure on Controller-Leader. However, there is a Broker-side request sending detail to note here. In some cases, such as long-term network partition or downtime and restart of Follower, etc., a large number of states may lag behind Controller-Leader. In this case, if Broker performs Follower-Read at the Controller-Follower to linearly read the status machine data, then according to `Follower-Read` and `Read-Index` protocol, the request will be blocked until the Controller-Follower catches up with the status of the request acceptance time of the Controller-Leader. This will cause the following problems: 1. Delay in `Broker`'s data reading, as it needs to wait for Controller-Follower to catch up with Controller-Leader's status. 2. A large number of blocking `Broker` read requests are blocked on the Controller-Follower node, causing a large number of business processing threads to occupy the node itself, further slowing down the Follower's catching up with the Leader. Therefore, an optimization for reading from a Follower node can be implemented on the Controller side. When the status of Controller-Follower lags behind a certain threshold, the Controller-Follower node will no longer provide `Follower-Read`, but instead let Broker request to other Followers or Leaders. ##### Admin Request `Admin` side sends requests to view status, and these requests do not need to ensure linear consistency. Can we also send them to Follower for processing? Theoretically, this type of `Unsafe-Read` request does not need to ensure consistency, so can we read from any node. However, our core goal is to make the read data as close to or as consistent with the actual current state machine data as possible. If we let the Controller-Follower node handle the `Unsafe-Read` processing, it will increase the probability of reading a `Stale-State`, as the Leader always has the latest data in the current replica group, and Follower may lag behind the Leader. Therefore, we still need to send this `Unsafe-ReadRequest` to the Controller-Leader for processing. ### Motivation . ### Describe the Solution You'd Like . ### Describe Alternatives You've Considered . ### Additional Context _No response_ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}