HwiLu opened a new issue, #1820: URL: https://github.com/apache/incubator-seatunnel/issues/1820
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/incubator-seatunnel/issues?q=is%3Aissue+label%3A%22bug%22) and found no similar issues. ### What happened When the source table time field is null, the target table will be populated with the current timestamp。The type of time field could be `TIMESTAMP` `DATETIME` `TIME`。The detail shows in screenshots. ### SeaTunnel Version v2.1.1 ### SeaTunnel Config ```conf # cat spark.batch.jdbc.to.jdbc.conf # # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ###### ###### This config file is a demonstration of batch processing in SeaTunnel config ###### env { # You can set spark configuration here # see available properties defined by spark: https://spark.apache.org/docs/latest/configuration.html#available-properties spark.app.name = "SeaTunnel" spark.executor.instances = 2 spark.executor.cores = 1 spark.executor.memory = "1g" } source { # This is a example input plugin **only for test and demonstrate the feature input plugin** jdbc { driver = "com.mysql.jdbc.Driver" url = "jdbc:mysql://localhost:3306/zhangw" table = "zhangw_s" result_table_name = "zhangw_r" user = "zhangw" password = "zhangw" } # You can also use other input plugins, such as file # file { # result_table_name = "accesslog" # path = "hdfs://hadoop-cluster-01/nginx/accesslog" # format = "json" # } # If you would like to get more information about how to configure seatunnel and see full list of input plugins, # please go to https://seatunnel.apache.org/docs/spark/configuration/source-plugins/Fake } transform { # split data by specific delimiter # you can also use other filter plugins, such as sql # sql { # sql = "select * from accesslog where request_time > 1000" # } # If you would like to get more information about how to configure seatunnel and see full list of filter plugins, # please go to https://seatunnel.apache.org/docs/spark/configuration/transform-plugins/Sql } sink { # choose stdout output plugin to output data to console #Console {} jdbc { driver = "com.mysql.jdbc.Driver", saveMode = "overwrite", url = "jdbc:mysql://node02:3306/zhangwei" user = "zhangw", password = "zhangw", dbTable = "zhangw_s", } # you can also use other output plugins, such as hdfs # hdfs { # path = "hdfs://hadoop-cluster-01/nginx/accesslog_processed" # save_mode = "append" # } # If you would like to get more information about how to configure seatunnel and see full list of output plugins, # please go to https://seatunnel.apache.org/docs/spark/configuration/sink-plugins/Console } ``` ### Running Command ```shell ./bin/start-seatunnel-spark.sh --master local[2] --deploy-mode client --config ./config/spark.batch.jdbc.to.jdbc.conf ``` ### Error Exception ```log no error ``` ### Flink or Spark Version spark-2.4.8-bin-hadoop2.7 ### Java or Scala Version java version "1.8.0_281" ### Screenshots  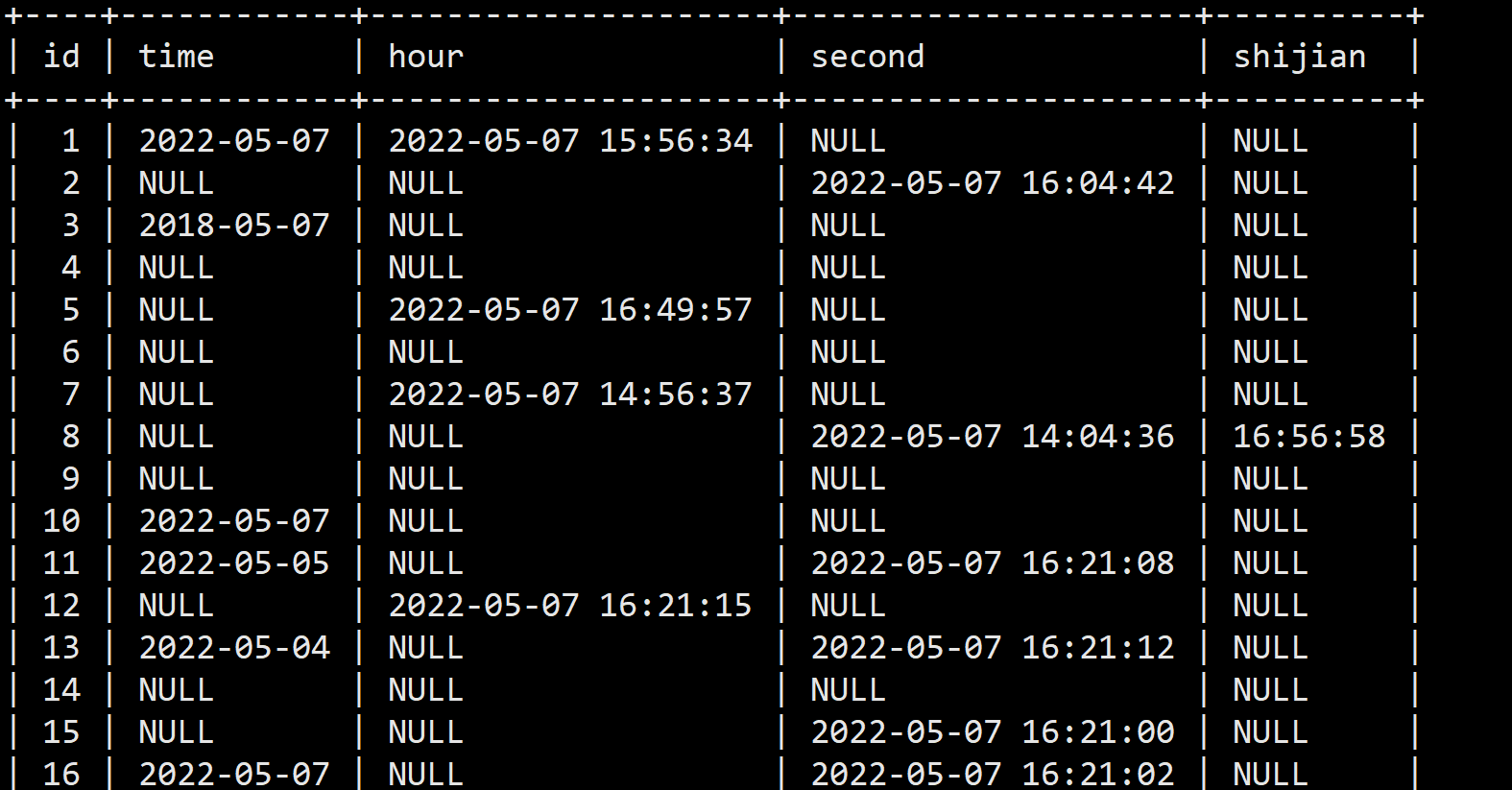 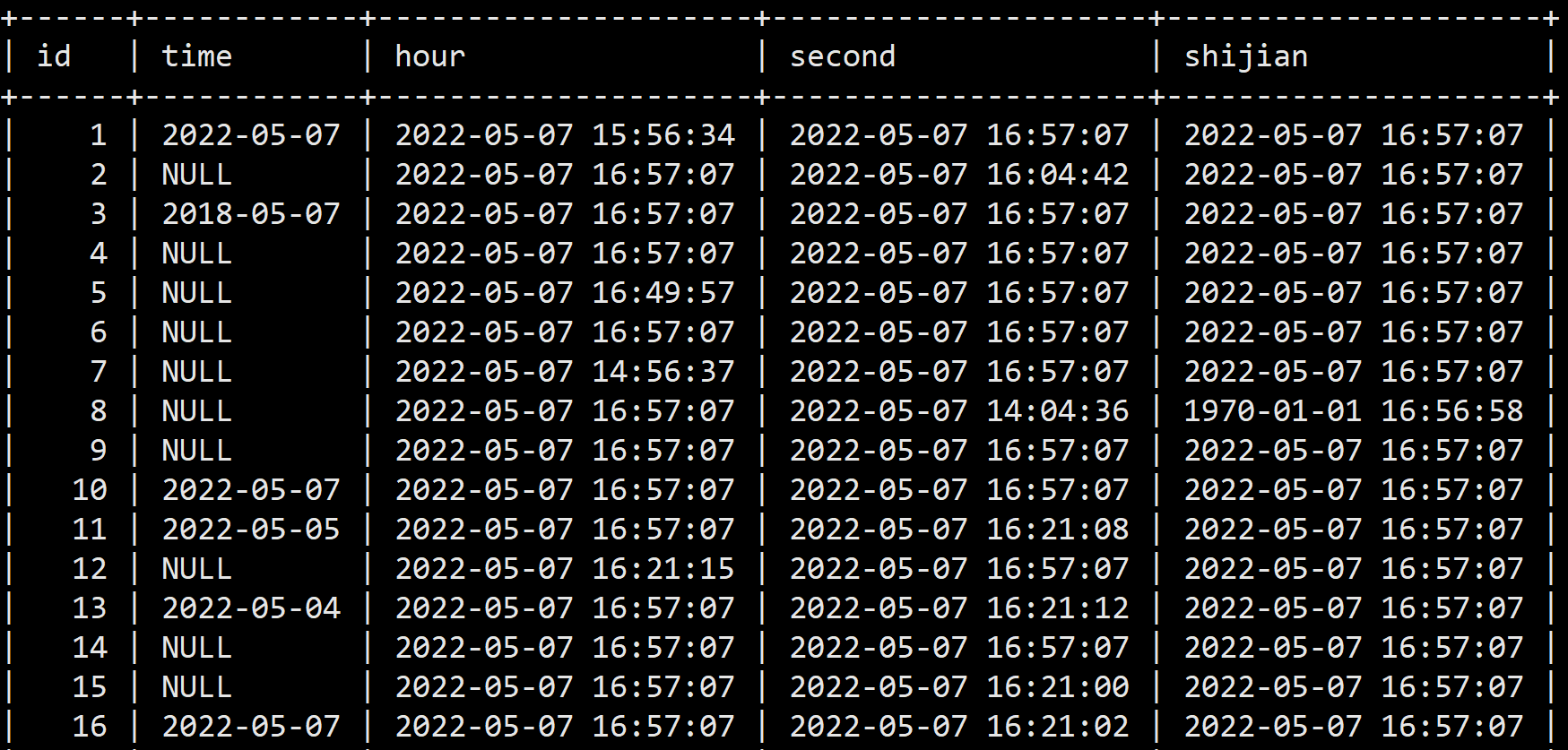 ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}