laglangyue opened a new issue, #2405: URL: https://github.com/apache/incubator-seatunnel/issues/2405
### Search before asking - [X] I had searched in the [issues](https://github.com/apache/incubator-seatunnel/issues?q=is%3Aissue+label%3A%22bug%22) and found no similar issues. ### What happened When I was adapting connector-v2 and testing locally, I found some problems with decimal. I modified the code of the fake of connector-v2 to support the decimal type, and then run org.apache.seatunnel.example.spark.v2.seatunnelapiexample, which repeats the error. 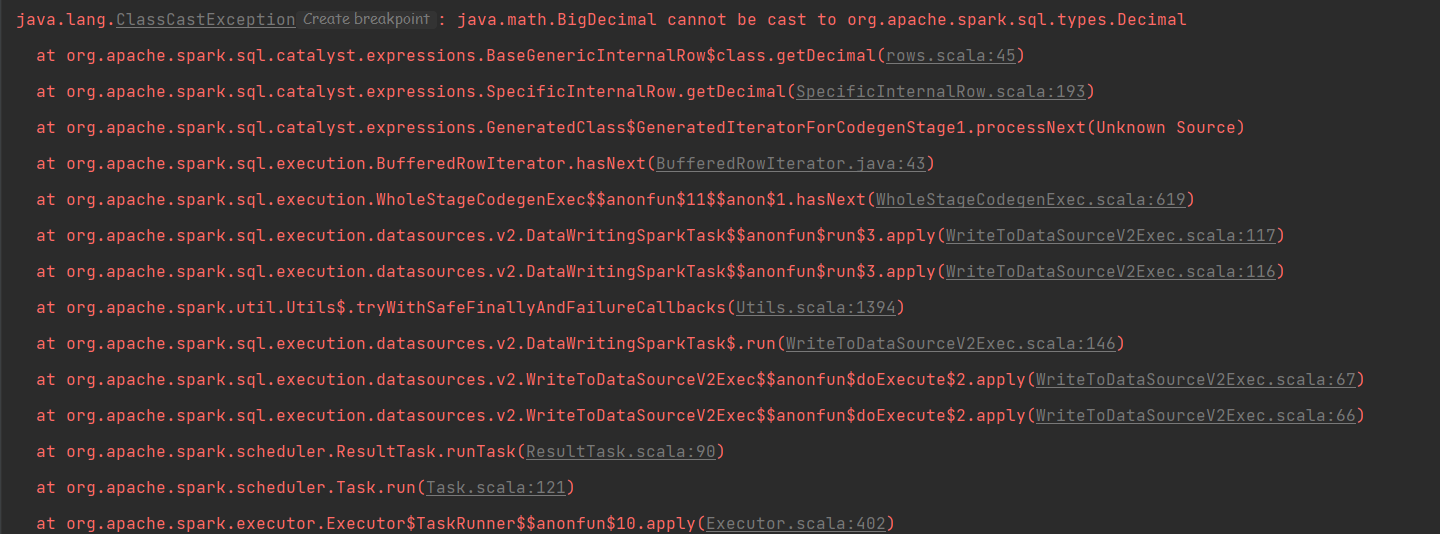 ### SeaTunnel Version dev ### SeaTunnel Config ```conf env { # You can set spark configuration here # see available properties defined by spark: https://spark.apache.org/docs/latest/configuration.html#available-properties #job.mode = BATCH spark.app.name = "SeaTunnel" spark.executor.instances = 2 spark.executor.cores = 1 spark.executor.memory = "1g" spark.master = local } source { # This is a example input plugin **only for test and demonstrate the feature input plugin** FakeSource { result_table_name = "fake" field_name = "name,age,timestamp,decimal" } # You can also use other input plugins, such as hdfs # hdfs { # result_table_name = "accesslog" # path = "hdfs://hadoop-cluster-01/nginx/accesslog" # format = "json" # } # If you would like to get more information about how to configure seatunnel and see full list of input plugins, # please go to https://seatunnel.apache.org/docs/spark/configuration/source-plugins/Fake } transform { # split data by specific delimiter # you can also use other transform plugins, such as sql sql { sql = "select name,age,timestamp,decimal from fake" result_table_name = "sql" } # If you would like to get more information about how to configure seatunnel and see full list of transform plugins, } sink { Console {} } ``` ### Running Command ```shell just in idea run the example org.apache.seatunnel.example.spark.v2.seatunnelapiexample ``` ### Error Exception ```log at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73) at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:668) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:259) at org.apache.seatunnel.core.starter.spark.execution.SinkExecuteProcessor.execute(SinkExecuteProcessor.java:75) at org.apache.seatunnel.core.starter.spark.execution.SparkExecution.execute(SparkExecution.java:60) at org.apache.seatunnel.core.starter.spark.command.SparkApiTaskExecuteCommand.execute(SparkApiTaskExecuteCommand.java:54) at org.apache.seatunnel.core.starter.Seatunnel.run(Seatunnel.java:40) at org.apache.seatunnel.example.spark.v2.SeaTunnelApiExample.main(SeaTunnelApiExample.java:43) Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0, localhost, executor driver): java.lang.ClassCastException: java.math.BigDecimal cannot be cast to org.apache.spark.sql.types.Decimal at org.apache.spark.sql.catalyst.expressions.BaseGenericInternalRow$class.getDecimal(rows.scala:45) at org.apache.spark.sql.catalyst.expressions.SpecificInternalRow.getDecimal(SpecificInternalRow.scala:193) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source) at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43) at org.apache.spark.sql.execution.WholeStageCodegenExec$$anonfun$11$$anon$1.hasNext(WholeStageCodegenExec.scala:619) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2Exec.scala:117) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$$anonfun$run$3.apply(WriteToDataSourceV2Exec.scala:116) ``` ### Flink or Spark Version _No response_ ### Java or Scala Version 8 ### Screenshots _No response_ ### Are you willing to submit PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}