CalvinKirs opened a new issue, #2557:
URL: https://github.com/apache/incubator-seatunnel/issues/2557
## Abstract
WAL (Write Ahead Logging) is generated due to the requirement of master node
data storage persistence. We need to use the file system to complete the node
data persistence.
The node data is a `KV` key-value pair, and the stored data can only be
queried in full. The data is usually in kb-mb size. Direct storage of KV based
on the file system itself is a heavyweight operation, and concurrent writing is
not supported for some file systems. , but in order to ensure efficiency, we
will use batch writing, and how to ensure data accuracy, we use the WAL method.
##WAL's core idea
Usually called write-ahead log, it is a common method to prevent memory
corruption and ensure that data is not lost.
## Outline Design
### WAL structure
We will define a WalEntry as follows
````
class WalEntry{
byte[] key
byte[] value
Type EntryType
}
````
When there is data to write, we will encapsulate the data (single) into a
WalEntry, and then encode it. In addition to the above fields, the encoded data
will also add a CRC value (CRC32 cyclic redundancy check technology, Use 8
bytes to save, so that it can be validated when reading),
### Read and write design
For higher performance, we use continuous append writes to improve
performance, and use a double buffer mechanism, that is, read and write
separation, each with a `buffer`.
````
calss ReadBuffer
class WriterBuffer
````
The written data is first recorded in WAL, and then written to the memory
memtable (the memtable will eventually be flushed into the storage system in
batches)
The size of the WAL file is related to the capacity of the memtable bound to
it. The memtable will have a threshold, and it will be closed when it is full,
and the WAL will not accept new writes at this time, so the capacity of the WAL
file usually does not expand infinitely . After the data in the memtable is
flushed to disk by a background thread, and no other errors occur, the WAL can
be safely deleted.
When SeaTunnel starts, we will fully load the data in the WAL and restore
the full disk.
All write operations are performed in the memtable. When the memtable space
is insufficient, a new memtable will be created to continue to receive write
operations. The original memory will be marked as read-only mode, waiting to be
flushed.
### WAL brush strategy
When data is written to the WAL file, we need to manually call flush to
complete it.
There are usually three strategies in the industry,
Since we can't stand data loss, we only use one strategy - instant flushing,
but also configurable time period flushing.
### How to utilize an existing filesystem
We will split the previous FileStorage, and third-party file system
instances (such as Hdfs) will be split for reuse.
````
public HdfsStorage(Map<String, String> configuration) throws
CheckpointStorageException {
this.initStorage(configuration);
}
````
init storage will be independent for other business calls,
And checkpoint will be used as a storage business type of storage.
### latest version
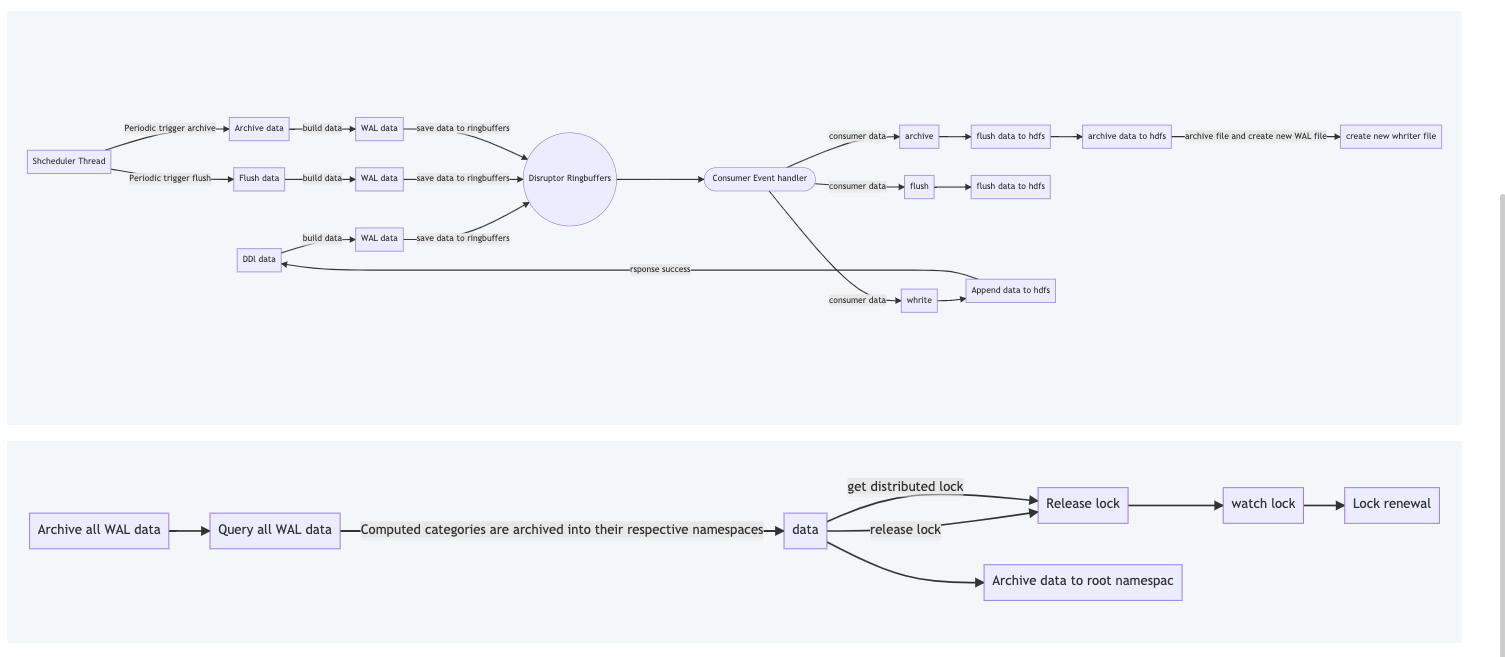
We use Disruptor to build a multi-producer-single-consumer model to ensure
consistent data order.
We name the user's IMAP data as namespace to distinguish different IMAP
data. Each server will create a namespace/Server-Index/WAL and a
namespace/Server-Index/Storage-Data( Storage data is the data after each
archive), which is used to store the data requested from the server.
The Server-Index can be an IP or a random string. Just to distinguish
between different servers, as long as there is no conflict.
When users go to DDL operations (it should be noted that all DDL operations
are appends in our actual storage, there is no real physical deletion), users
will build the corresponding WAL Data (including operation instructions,
versions, serialization) , a series of information such as namespce, and the
corresponding serialization information, etc.),
Then submit the message to the disruotor. This process is a synchronization
process. When the data of this operation is consumed, it will return after the
append command is actually executed. After this process is completed, a
successful message will be returned to the user, which means that the operation
was successfully performed. .
We will have an asynchronous timing thread to perform flush and archive
operations. When our data reaches a certain threshold, we will archive the
data. The process of archiving is to compress the data and then write it into
Storage-Data. Then delete the data in the WAL and create a new WAL file.
We have conducted benchmark tests, dual-threaded production, and
single-threaded consumption. When the data is at the byte level, a single
machine can reach tens of thousands of operations. At the MB level, it is
probably less than 100 operations. Among them, the byte-level data The memory
is set to 512M, and the MB-level data memory is set to 5G.
discuss:
If the WAL is named after the namespace, that is, on a server, each
namespace will have a WAL. In this case, we do not need to attach metadata
information to each data, but only need one piece of metadata information. When
archiving, all data needs to be archived, but only the corresponding WAL needs
to be archived.
When performing a full query, we need to query the data of all namespaces.
At this time, we need to archive all the data, but if the above method is
adopted, we only query all the archived WAL information of each node, and then
query the Can. In this process, calculation and merge operations will be
performed. All data are ordered. We need to determine the final value of all
data according to the data order.
for example
````
insert into data(K,V) values(1,1)
insert into data(K,V) values(1,2)
delete from data where K=1
insert into data(K,V) values(1,3)
update data set V=4 where K=1
````
The above records will have a total of five records in the storage, so we
will merge them according to the version. In the above statement, if we query,
the actual returned records are K=1 V=4
Distributed locks are not actually optional in this process, if each node
has a record for each namespace. Then when we query, because there is no
archive operation, there will be no concurrency, so there is no need for
distributed locks. Since we want to get the latest data, in this process, we
need to wait for 2*flushInterval time. This time can be configured. If our data
volume is large, then we can set this time to be very large, which can reduce
the The number of archives, but will increase the query time.
Physical data storage directory
<img width="1110" alt="image"
src="https://user-images.githubusercontent.com/16631152/189626085-16c141a1-7b0d-4aa5-9ee9-85e8af2c2814.png";>
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}