kyehe opened a new issue, #3618: URL: https://github.com/apache/incubator-seatunnel/issues/3618
### Search before asking - [X] I had searched in the [feature](https://github.com/apache/incubator-seatunnel/issues?q=is%3Aissue+label%3A%22Feature%22) and found no similar feature requirement. ### Description Branch: dev version: 2.1.3 spark batch job on yarn when I run st job with spark mode, I found that the spark job has two stages, one is source reader stage, another is sink wirter stage. according to the logs, the second will not execute before the source reader finish. so, for the batch job, especially for read a large of data from source like a big mysql table, it will spend so much time to read data with jdbc connection, while the sink writer need to start write when source reader has read one single line of data. the parallelly mode will speed up the whole job as soon as possible. the picture blew is a test job to read a big(5+ billion lines) mysql table which has not primary key and write into a hive table. source parallism is default value 1, the sink parallism I configured it to 30. 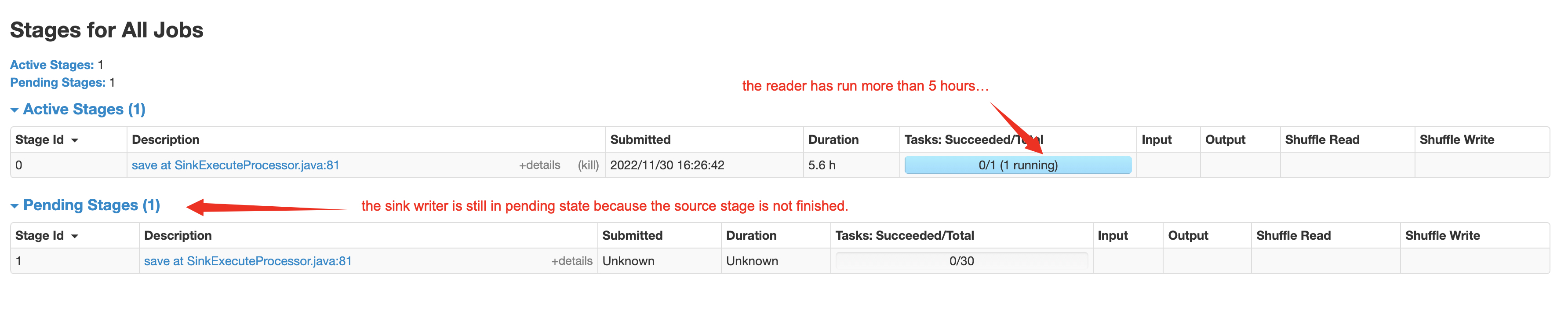 ### Usage Scenario _No response_ ### Related issues _No response_ ### Are you willing to submit a PR? - [ ] Yes I am willing to submit a PR! ### Code of Conduct - [X] I agree to follow this project's [Code of Conduct](https://www.apache.org/foundation/policies/conduct) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}