This is an automated email from the ASF dual-hosted git repository.
shenghang pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/seatunnel-website.git
The following commit(s) were added to refs/heads/main by this push:
new a2c9fbea413d [Blog] SeaTunnel metadata cache deep dive (EN/ZH) (#418)
a2c9fbea413d is described below
commit a2c9fbea413d880ad65edbbbf27e856fa6830a52
Author: David Zollo <[email protected]>
AuthorDate: Tue Jan 13 20:21:45 2026 +0800
[Blog] SeaTunnel metadata cache deep dive (EN/ZH) (#418)
---
blog/2026-01-13-seatunnel-metadata-cache.md | 102 +++++++++++++++++++++
.../2026-01-13-seatunnel-metadata-cache.md | 102 +++++++++++++++++++++
2 files changed, 204 insertions(+)
diff --git a/blog/2026-01-13-seatunnel-metadata-cache.md
b/blog/2026-01-13-seatunnel-metadata-cache.md
new file mode 100644
index 000000000000..8dd4381786f7
--- /dev/null
+++ b/blog/2026-01-13-seatunnel-metadata-cache.md
@@ -0,0 +1,102 @@
+---
+slug: seatunnel-metadata-cache
+title: "Deep Dive into Apache SeaTunnel Metadata Cache: Running Tens of
Thousands of Sync Jobs in Parallel"
+tags: [Zeta, SeaTunnel Engine, Metadata]
+---
+
+# Deep Dive into Apache SeaTunnel Metadata Cache: Running Tens of Thousands of
Sync Jobs in Parallel
+
+
+
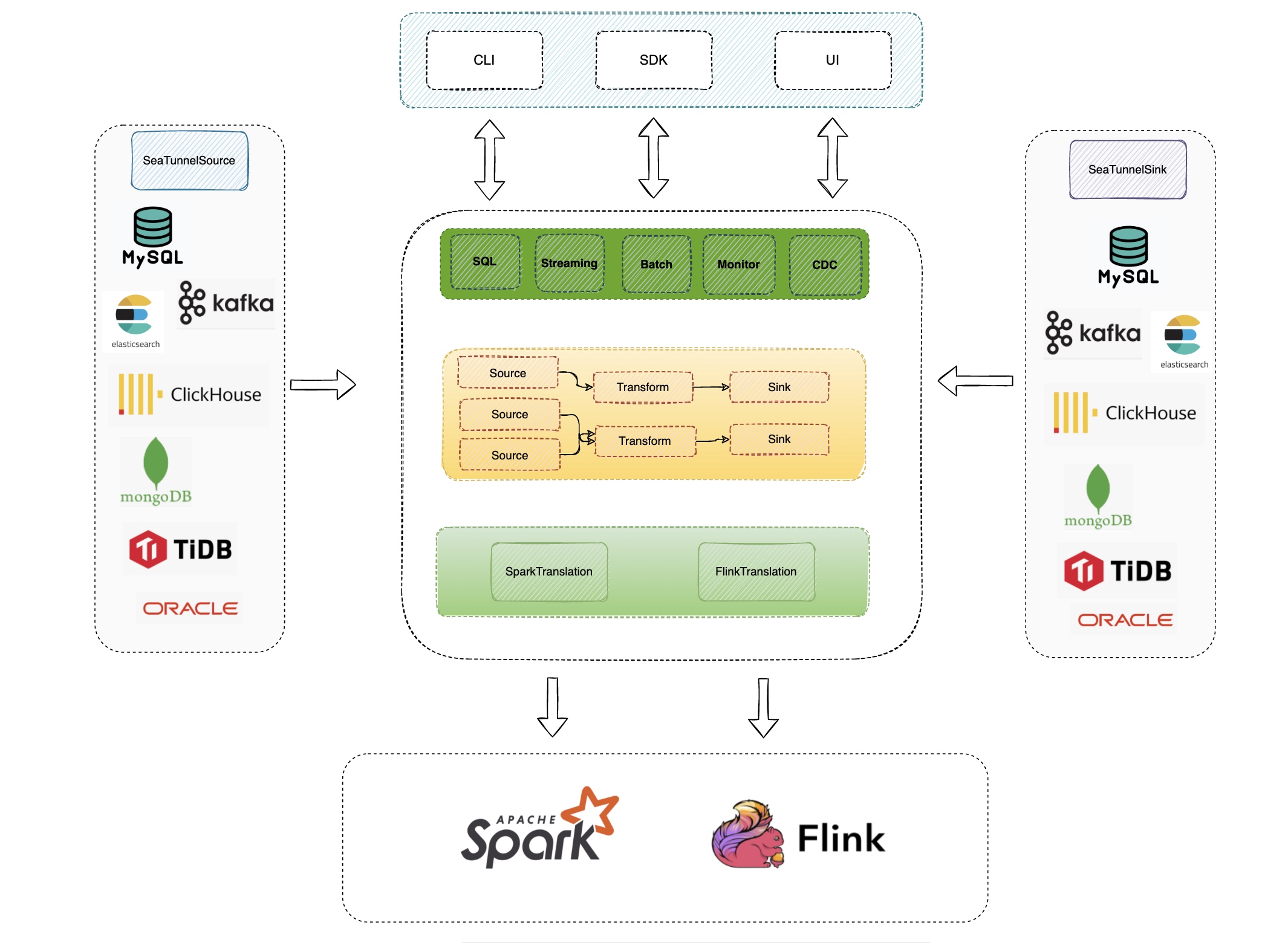
+In large-scale data integration, the throughput bottleneck is often not the
data pipeline itself, but the “metadata path”: loading connector JARs during
startup, managing state and recovery during runtime, and fetching
schemas/partitions from external systems (databases, Hive Metastore, etc.)
while initializing jobs. Once job concurrency reaches thousands (or more),
these seemingly small operations can easily turn into cluster-wide pressure.
+
+Apache SeaTunnel Engine (Zeta) caches high-frequency, reusable, and expensive
metadata on the engine side, and combines it with distributed storage and
lifecycle cleanup. This is a key reason why the engine can run massive numbers
of sync jobs concurrently with better stability.
+
+
+
+## Why metadata becomes the bottleneck
+
+When you start a huge number of small jobs in parallel, the most common
metadata bottlenecks usually come from three areas:
+
+- **Class loading and dependency isolation**: creating a dedicated ClassLoader
per job can repeatedly load the same connector dependencies and quickly raise
JVM Metaspace pressure.
+- **State and recoverability**: checkpoints, runtime state, and historical job
information can become heavy in both memory and IO without tiered storage and
automatic cleanup.
+- **External schema/catalog queries**: repeated schema and partition lookups
can overload databases or Hive Metastore and lead to instability.
+
+Below is a practical breakdown of SeaTunnel’s approach, together with
configuration tips you can apply in production.
+
+## 1) ClassLoader caching to reduce Metaspace pressure
+
+When many jobs reuse the same set of connectors, frequent creation/destruction
of class loaders causes Metaspace churn and can even lead to metaspace-related
OOMs. SeaTunnel Engine provides `classloader-cache-mode` to reuse class loaders
across jobs and reduce repeated loads.
+
+Enable it in `seatunnel.yaml` (it is enabled by default; re-enable it if you
previously turned it off):
+
+```yaml
+seatunnel:
+ engine:
+ classloader-cache-mode: true
+```
+
+**When it helps most**:
+
+- High job concurrency and frequent job starts, with a relatively small set of
connector types.
+- You observe consistent Metaspace growth or class-loading related memory
alerts.
+
+**Notes**:
+
+- If your cluster runs with a highly diverse set of connectors, caching
increases the amount of resident metadata in Metaspace. Monitor your Metaspace
trend and adjust accordingly.
+
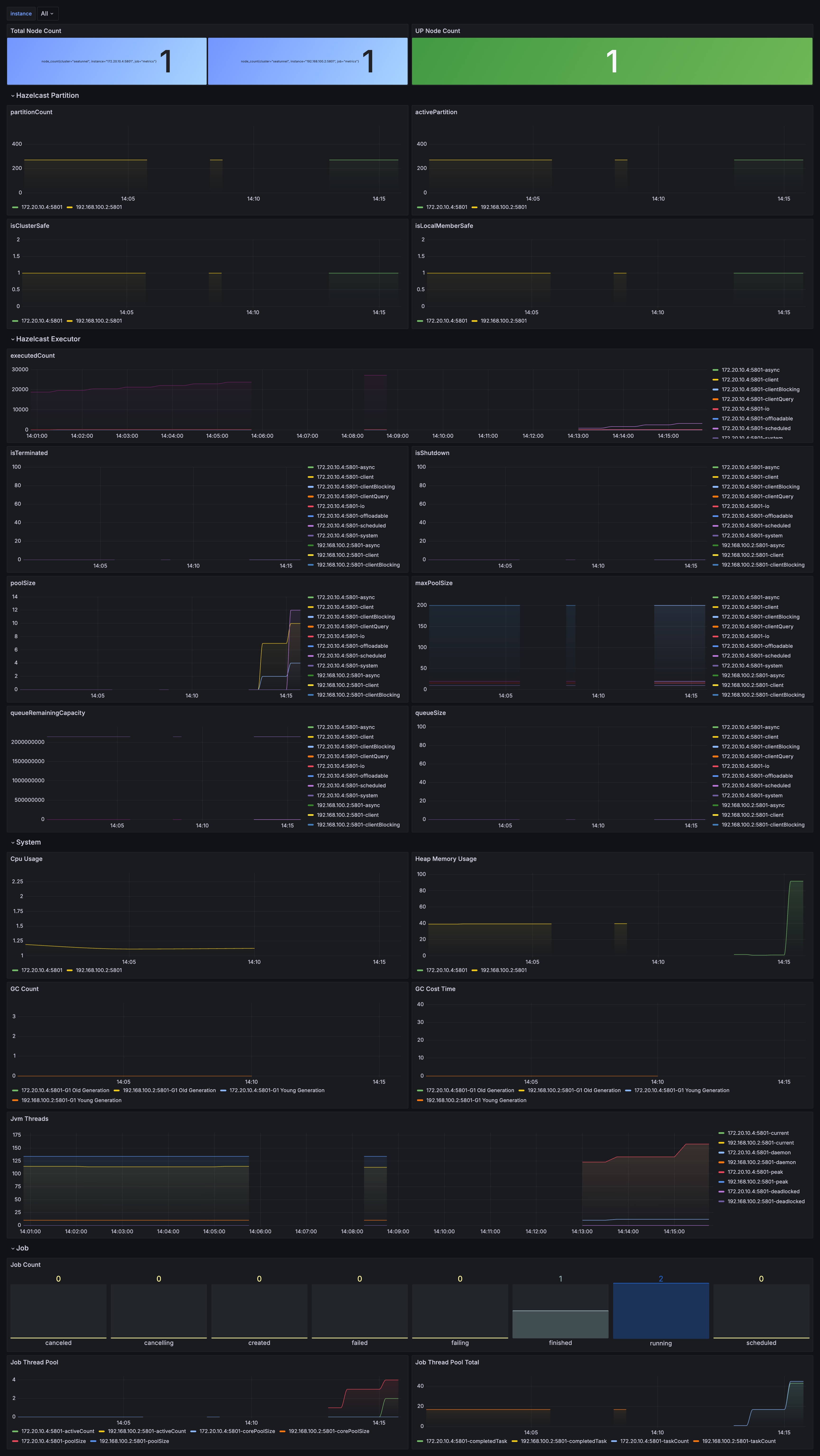
+## 2) Distributed state and persistence for recoverability
+
+SeaTunnel Engine’s fault tolerance is built on the Chandy–Lamport checkpoint
idea. For both performance and reliability, it uses Hazelcast distributed data
structures (such as IMap) for certain runtime information, and relies on
external storage (shared/distributed storage) for durable recovery.
+
+In practice, you will usually care about three sets of settings:
+
+### (1) Checkpoint parameters
+
+```yaml
+seatunnel:
+ engine:
+ checkpoint:
+ interval: 300000
+ timeout: 10000
+```
+
+If your job config (`env`) specifies
`checkpoint.interval`/`checkpoint.timeout`, the job config takes precedence.
+
+### (2) IMap backup and persistence (recommended for production)
+
+For multi-node clusters, configure at least `backup-count` to reduce the risk
of losing in-memory information when a node fails. If you want jobs to be
automatically recoverable after a full cluster stop/restart, consider enabling
external persistence for IMap as well.
+
+For details, see:
+- `/docs/seatunnel-engine/deployment`
+- `/docs/seatunnel-engine/checkpoint-storage`
+
+### (3) Automatic cleanup of historical job information
+
+SeaTunnel stores completed job status, counters, and error logs in IMap. As
the number of jobs grows, memory usage will grow too. Configure
`history-job-expire-minutes` so expired job information is evicted
automatically (default is 1440 minutes, i.e., 1 day).
+
+```yaml
+seatunnel:
+ engine:
+ history-job-expire-minutes: 1440
+```
+
+## 3) Catalog/schema metadata caching to reduce source-side pressure
+
+When many jobs start concurrently, schema/catalog requests (table schema,
partitions, constraints, etc.) can turn into a “silent storm”. SeaTunnel
applies caching and reuse patterns in connectors/catalogs to reduce repeated
network round-trips and metadata parsing overhead.
+
+- **JDBC sources**: startup typically fetches table schemas, types, and
primary keys for validation and split planning. For large fan-out startups,
avoid letting every job repeatedly fetch the same metadata (batch job starts or
pre-warming can help).
+- **Hive sources**: Hive Metastore is often a shared and sensitive service.
Reusing catalog instances and already-loaded database/table/partition metadata
helps reduce Metastore pressure, especially for highly partitioned tables.
+
+## How this differs from Flink/Spark: optimized for “massive small jobs”
+
+Flink is primarily designed for long-running streaming jobs and complex
operator state; Spark is job/context oriented for batch processing. For the
“tens of thousands of independent small jobs” goal, SeaTunnel Engine focuses on
pushing reusable metadata down to the engine layer: minimizing repeated loads,
minimizing repeated external queries, and managing the lifecycle of historical
job metadata to keep the cluster stable under high concurrency.
+
+## Production checklist
+
+- **Enable reasonable backups**: in production, set `backup-count >= 1` and
evaluate IMap persistence if you need automatic recovery after full restarts.
+- **Limit connector diversity**: keeping connector combinations relatively
stable improves the benefit of `classloader-cache-mode`.
+- **Monitor metadata-related signals**: besides JVM metrics, watch checkpoint
latency/failure rate, Hazelcast memory usage, IMap size and growth, and
historical job accumulation.
+- **Set eviction policies**: tune `history-job-expire-minutes` to balance
observability and long-term memory safety.
+
+
diff --git
a/i18n/zh-CN/docusaurus-plugin-content-blog/2026-01-13-seatunnel-metadata-cache.md
b/i18n/zh-CN/docusaurus-plugin-content-blog/2026-01-13-seatunnel-metadata-cache.md
new file mode 100644
index 000000000000..ba07815249d6
--- /dev/null
+++
b/i18n/zh-CN/docusaurus-plugin-content-blog/2026-01-13-seatunnel-metadata-cache.md
@@ -0,0 +1,102 @@
+---
+slug: seatunnel-metadata-cache
+title: "深度拆解 Apache SeaTunnel 元数据缓存:支撑数万同步任务并行运行"
+tags: [Zeta, SeaTunnel Engine, Metadata]
+---
+
+# 深度拆解 Apache SeaTunnel 元数据缓存:支撑数万同步任务并行运行
+
+
+
+在大规模数据集成场景中,吞吐瓶颈往往不在数据通道本身,而在“元数据路径”上:启动时的 Connector/Jar
加载、运行中的状态管理与恢复、以及初始化阶段对外部系统(如数据库、Hive Metastore)的
Schema/分区查询。任务量一旦上到千级、万级,这些“看似轻量”的动作会被放大成集群级别的压力。
+
+Apache SeaTunnel
Engine(Zeta)把一部分高频、可复用且昂贵的元数据下沉到引擎侧进行缓存,并配合分布式存储与自动清理策略,让海量同步任务可以更稳定地并行运行。
+
+
+
+## 为什么“元数据”会成为瓶颈
+
+以“万级小作业”并行启动为例,常见的元数据瓶颈主要来自三类:
+
+- **类加载与依赖隔离**:每个作业独立创建 ClassLoader,会反复加载同一批 Connector 依赖,快速抬升 JVM Metaspace
压力。
+- **状态与恢复信息**:Checkpoint、任务状态、历史作业信息等若缺少分层存储与自动清理,会带来内存与 IO 的双重负担。
+- **外部目录/Schema 查询**:作业初始化阶段对源端数据库或 Metastore 的频繁请求,容易造成连接拥塞与元数据服务抖动。
+
+下面从三条主线拆解 SeaTunnel 的“元数据缓存”思路与可落地的配置建议。
+
+## 一:ClassLoader 缓存,降低 Metaspace 压力
+
+当大量作业复用相同的 Source/Sink Connector 时,持续创建和销毁类加载器会带来明显的 Metaspace
抖动,甚至触发溢出。SeaTunnel Engine 提供 `classloader-cache-mode`,用于复用作业之间的
ClassLoader,减少重复加载和频繁回收的开销。
+
+在 `seatunnel.yaml` 中开启(该配置默认开启,若你曾手动关闭可重新启用):
+
+```yaml
+seatunnel:
+ engine:
+ classloader-cache-mode: true
+```
+
+**适用场景**:
+
+- 作业规模大、启动频繁,且 Connector 类型相对有限(复用率高)。
+- JVM Metaspace 频繁增长,或出现与类加载相关的内存告警。
+
+**注意点**:
+
+- 如果集群长期运行且 Connector 类型非常分散,缓存会增加常驻的类元数据占用;建议结合监控观察 Metaspace
曲线,再决定是否开启或调整作业结构。
+
+## 二:分布式状态与持久化,保证可恢复与可运营
+
+SeaTunnel Engine 的容错语义基于 Chandy–Lamport Checkpoint 思想。为了兼顾性能与可靠性,它在引擎内部使用
Hazelcast 的分布式数据结构(如 IMap)承载一部分运行态信息,并通过外部存储(共享/分布式存储)完成故障恢复所需的数据落盘。
+
+你通常需要关心三组配置:
+
+### 1) Checkpoint 触发参数
+
+```yaml
+seatunnel:
+ engine:
+ checkpoint:
+ interval: 300000
+ timeout: 10000
+```
+
+说明:如果在作业配置文件 `env` 中配置了 `checkpoint.interval`/`checkpoint.timeout`,会优先以作业配置为准。
+
+### 2) IMap 备份与持久化(建议用于生产集群)
+
+当集群节点数大于 1 时,建议至少配置
`backup-count`,以降低单点故障导致的内存态信息丢失风险;对于需要“全停全启后自动恢复”的场景,可进一步配置 IMap 外部持久化。
+
+相关细节可参考文档:
+- `/docs/seatunnel-engine/deployment`
+- `/docs/seatunnel-engine/checkpoint-storage`
+
+### 3) 历史作业信息的自动清理
+
+SeaTunnel 将已完成作业的状态、计数器、错误日志等信息存放在 IMap 中。作业越多,累积越快。建议按需配置
`history-job-expire-minutes`,让过期信息自动淘汰,避免内存长期膨胀(默认 1440 分钟,即 1 天)。
+
+```yaml
+seatunnel:
+ engine:
+ history-job-expire-minutes: 1440
+```
+
+## 三:Catalog/Schema 元数据缓存,减少源端压力
+
+大量作业并行启动时,对外部系统的元数据请求(表结构、分区信息、约束信息等)很容易成为“隐形风暴”。SeaTunnel 在 Connector/Catalog
侧引入缓存与复用思路,尽量把高频查询前置到引擎侧,减少重复的网络往返与服务端解析开销。
+
+- **JDBC
场景**:初始化阶段会读取表结构、字段类型、主键等信息,用于校验与分片规划。建议在高并发启动时避免每个作业对同一张表重复拉取全量元数据(可通过作业编排层做批次启动/预热)。
+- **Hive 场景**:Hive Metastore 往往是共享服务且相对敏感,建议尽量复用 Catalog 实例与已加载的
Database/Table/Partition 信息,并在大规模分区表同步中关注 Metastore 的 QPS 与响应时间。
+
+## 与 Flink / Spark 的差异:面向“海量小作业”的轻量化
+
+Flink 的设计重心是长生命周期的流作业与复杂算子状态;Spark 更偏向批处理与作业级 Context
管理。在“万级独立小任务并发”这个目标下,SeaTunnel Engine
的策略更强调把可复用的启动与运行元数据沉到引擎层:减少重复加载、减少重复查询、并对历史信息进行可控的生命周期管理,从而提升并发启动与稳定性。
+
+## 生产落地建议
+
+- **启用合理备份**:生产集群建议 `backup-count >= 1`,并评估是否需要 IMap 外部持久化以支持全停全启自动恢复。
+- **收敛 Connector 类型**:尽量在同一集群里控制 Connector 组合的离散程度,让 `classloader-cache-mode`
的收益最大化。
+- **关注“元数据指标”**:除了 JVM 指标,建议关注 Checkpoint 延迟/失败率、Hazelcast 内存使用、IMap
大小与增长速率、历史作业累积速度等。
+- **配置过期策略**:根据排障与审计需求设置 `history-job-expire-minutes`,避免“为了可观测性而撑爆内存”。
+
+
{kind=link}
{kind=link}
{kind=link}