This is an automated email from the ASF dual-hosted git repository.
shenghang pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/seatunnel-website.git
The following commit(s) were added to refs/heads/main by this push:
new ef4fffd13ad3 Add i18n for blog and fix img urls error (#419)
ef4fffd13ad3 is described below
commit ef4fffd13ad313f4a097ab212f8225bc30154217
Author: David Zollo <[email protected]>
AuthorDate: Thu Jan 15 18:16:30 2026 +0800
Add i18n for blog and fix img urls error (#419)
---
blog/2026-01-13-seatunnel-metadata-cache.md | 5 +-
docusaurus.config.js | 55 +++++++++++++++++++++
...-1-0-release.md => 2022-03-18-2-1-0-release.md} | 4 +-
.../2026-01-13-seatunnel-metadata-cache.md | 6 +--
.../seatunnel-metadata-cache/dashboard.jpg | Bin 0 -> 2137665 bytes
.../seatunnel-metadata-cache/metadata-flow.jpg | Bin 0 -> 544311 bytes
6 files changed, 61 insertions(+), 9 deletions(-)
diff --git a/blog/2026-01-13-seatunnel-metadata-cache.md
b/blog/2026-01-13-seatunnel-metadata-cache.md
index 8dd4381786f7..e901543b06b2 100644
--- a/blog/2026-01-13-seatunnel-metadata-cache.md
+++ b/blog/2026-01-13-seatunnel-metadata-cache.md
@@ -6,13 +6,12 @@ tags: [Zeta, SeaTunnel Engine, Metadata]
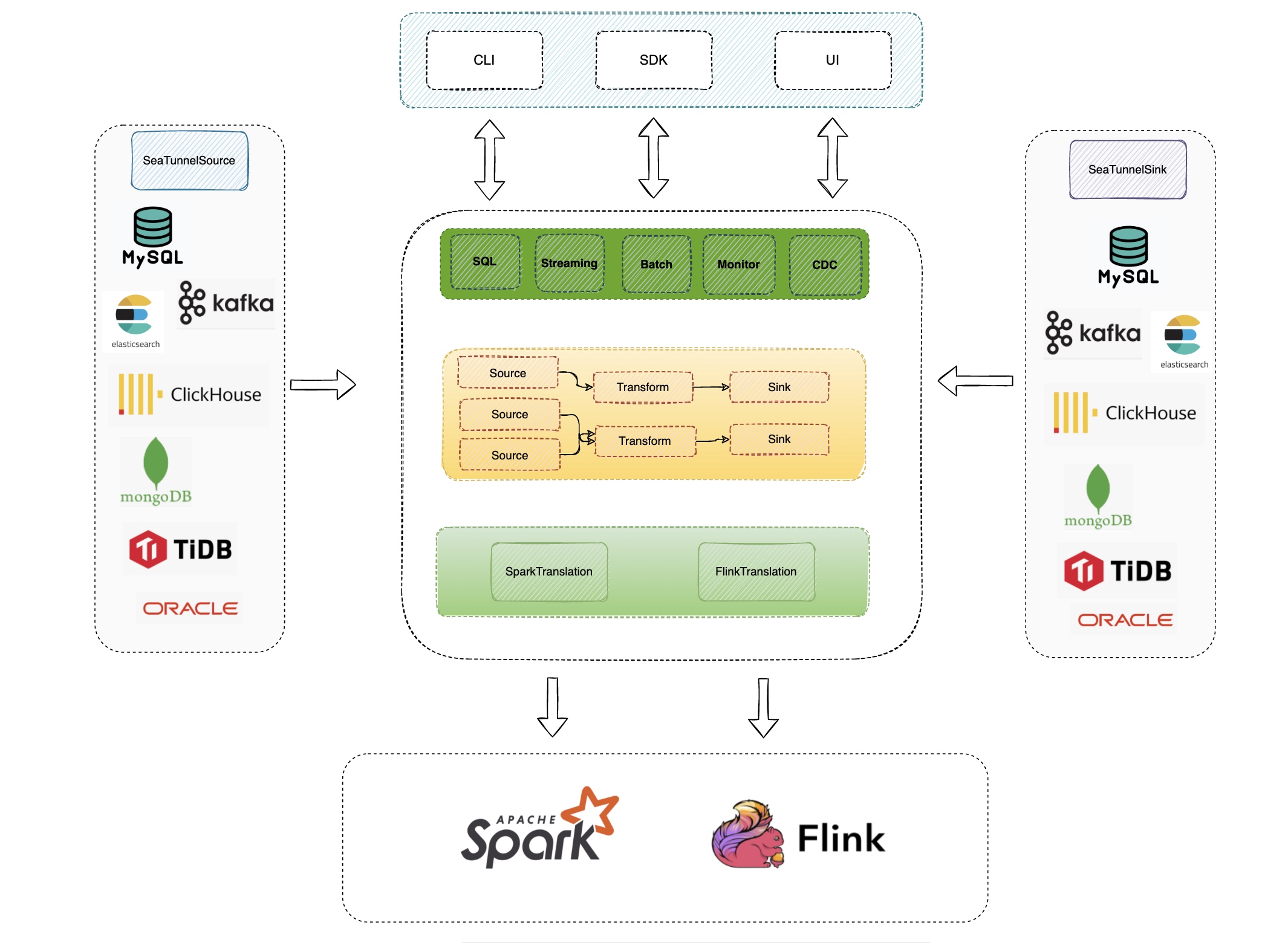
# Deep Dive into Apache SeaTunnel Metadata Cache: Running Tens of Thousands of
Sync Jobs in Parallel
-
In large-scale data integration, the throughput bottleneck is often not the
data pipeline itself, but the “metadata path”: loading connector JARs during
startup, managing state and recovery during runtime, and fetching
schemas/partitions from external systems (databases, Hive Metastore, etc.)
while initializing jobs. Once job concurrency reaches thousands (or more),
these seemingly small operations can easily turn into cluster-wide pressure.
Apache SeaTunnel Engine (Zeta) caches high-frequency, reusable, and expensive
metadata on the engine side, and combines it with distributed storage and
lifecycle cleanup. This is a key reason why the engine can run massive numbers
of sync jobs concurrently with better stability.
-
+
## Why metadata becomes the bottleneck
@@ -99,4 +98,4 @@ Flink is primarily designed for long-running streaming jobs
and complex operator
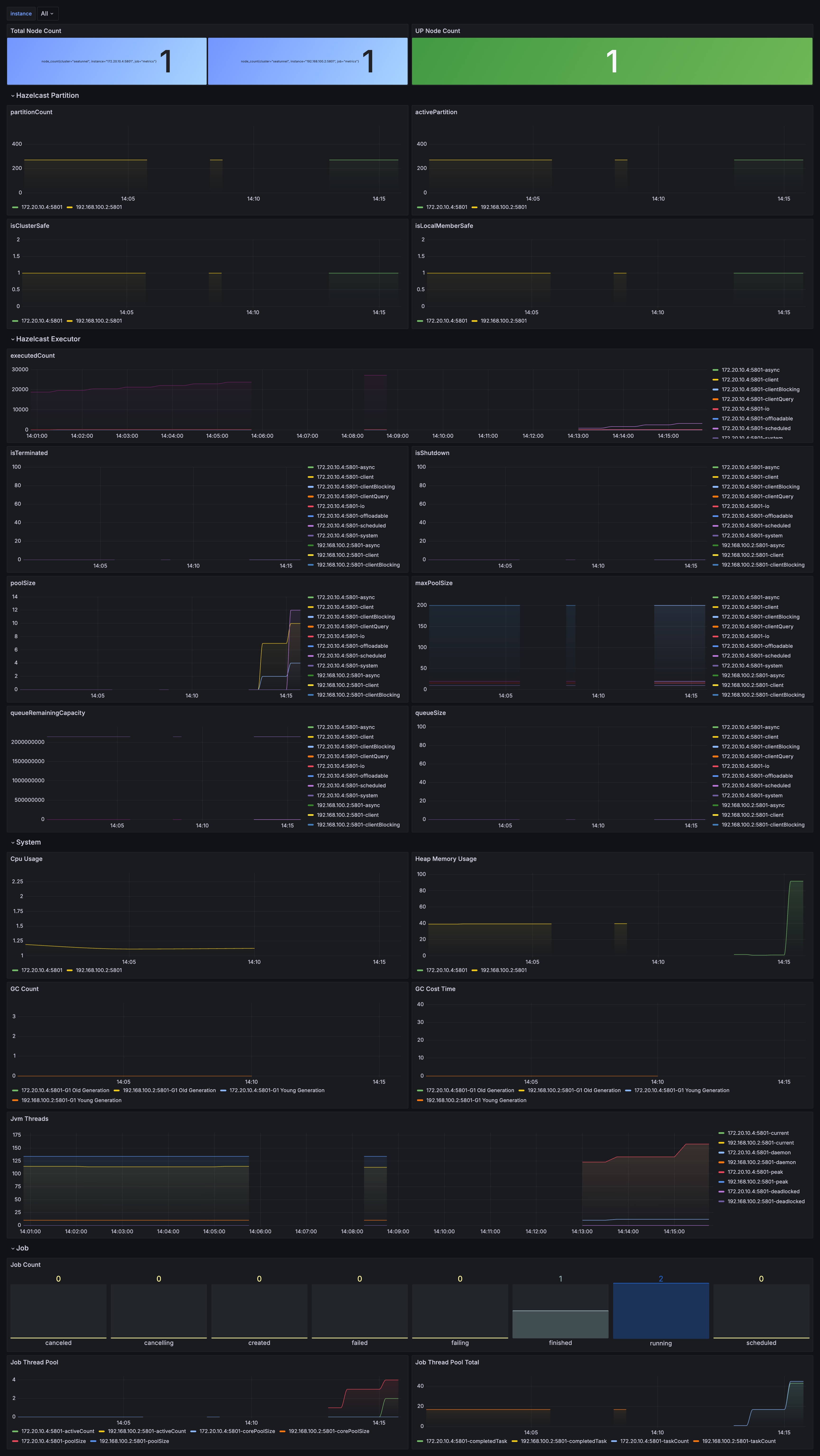
- **Monitor metadata-related signals**: besides JVM metrics, watch checkpoint
latency/failure rate, Hazelcast memory usage, IMap size and growth, and
historical job accumulation.
- **Set eviction policies**: tune `history-job-expire-minutes` to balance
observability and long-term memory safety.
-
+
diff --git a/docusaurus.config.js b/docusaurus.config.js
index b8c6042d1b77..cf3aea8743da 100644
--- a/docusaurus.config.js
+++ b/docusaurus.config.js
@@ -2,6 +2,55 @@ const darkCodeTheme =
require("prism-react-renderer/themes/dracula");
const versions = require("./versions.json");
const st_web_versions = require("./seatunnel_web_versions.json");
+const fs = require("fs");
+const path = require("path");
+
+function listMarkdownFiles(rootDir) {
+ /** @type {string[]} */
+ const results = [];
+
+ /** @param {string} dir */
+ function walk(dir) {
+ const entries = fs.readdirSync(dir, { withFileTypes: true });
+ for (const entry of entries) {
+ if (entry.name.startsWith(".")) continue;
+ const absPath = path.join(dir, entry.name);
+ if (entry.isDirectory()) {
+ walk(absPath);
+ continue;
+ }
+ if (!entry.isFile()) continue;
+ if (!entry.name.endsWith(".md") && !entry.name.endsWith(".mdx"))
continue;
+ results.push(path.relative(rootDir, absPath));
+ }
+ }
+
+ if (fs.existsSync(rootDir)) {
+ walk(rootDir);
+ }
+
+ return results;
+}
+
+function getZhBlogExcludePatterns() {
+ const blogRoot = path.join(__dirname, "blog");
+ const zhRoot = path.join(
+ __dirname,
+ "i18n",
+ "zh-CN",
+ "docusaurus-plugin-content-blog"
+ );
+
+ const blogFiles = listMarkdownFiles(blogRoot);
+ const exclude = [];
+ for (const rel of blogFiles) {
+ const translatedPath = path.join(zhRoot, rel);
+ if (!fs.existsSync(translatedPath)) {
+ exclude.push(rel);
+ }
+ }
+ return exclude;
+}
/** @type {import('@docusaurus/types').Config} */
const config = {
@@ -94,6 +143,12 @@ const config = {
},
blog: {
showReadingTime: true,
+ postsPerPage: 100,
+ blogSidebarCount: "ALL",
+ exclude:
+ process.env.DOCUSAURUS_CURRENT_LOCALE === "zh-CN"
+ ? getZhBlogExcludePatterns()
+ : [],
// Please change this to your repo.
editUrl:
"https://github.com/apache/seatunnel-website/edit/main/";,
diff --git a/i18n/zh-CN/docusaurus-plugin-content-blog/2-1-0-release.md
b/i18n/zh-CN/docusaurus-plugin-content-blog/2022-03-18-2-1-0-release.md
similarity index 98%
rename from i18n/zh-CN/docusaurus-plugin-content-blog/2-1-0-release.md
rename to i18n/zh-CN/docusaurus-plugin-content-blog/2022-03-18-2-1-0-release.md
index 2f7f604594e6..42b1fdb96169 100644
--- a/i18n/zh-CN/docusaurus-plugin-content-blog/2-1-0-release.md
+++ b/i18n/zh-CN/docusaurus-plugin-content-blog/2022-03-18-2-1-0-release.md
@@ -1,5 +1,5 @@
---
-slug: Apache SeaTunnel(Incubating) 首个Apache 版本 2.1.0 发布,内核重构,全面支持Flink
+slug: "Apache SeaTunnel(Incubating) 首个Apache 版本 2.1.0 发布,内核重构,全面支持Flink"
title: Apache SeaTunnel(Incubating) 首个Apache 版本 2.1.0 发布,内核重构,全面支持Flink
tags: [2.1.0, Release]
---
@@ -58,4 +58,4 @@ Apache SeaTunnel(Incubating) 目前登记用户如下,如果您也在使用Apa
## 【PPMC感言】
Apache SeaTunnel(Incubating) PPMC LiFeng Nie在谈及首个Apache版本发布的时候说,从进入Apache
Incubator的第一天,我们就一直在努力学习Apache
Way以及各种Apache政策,第一个版本发布的过程花费了大量的时间(主要是合规性),但我们认为这种时间是值得花费的,这也是我们选择进入Apache的一个很重要的原因,我们需要让用户用得放心,而Apache无疑是最佳选择,其
License 近乎苛刻的检查会让用户尽可能地避免相关的合规性问题,保证软件合理合法的流通。另外,其践行Apache
Way,例如公益使命、实用主义、社区胜于代码、公开透明与共识决策、任人唯贤等,可以帮助 SeaTunnel 社区更加开放、透明,向多元化方向发展。
-
\ No newline at end of file
+
diff --git
a/i18n/zh-CN/docusaurus-plugin-content-blog/2026-01-13-seatunnel-metadata-cache.md
b/i18n/zh-CN/docusaurus-plugin-content-blog/2026-01-13-seatunnel-metadata-cache.md
index ba07815249d6..dd1734204330 100644
---
a/i18n/zh-CN/docusaurus-plugin-content-blog/2026-01-13-seatunnel-metadata-cache.md
+++
b/i18n/zh-CN/docusaurus-plugin-content-blog/2026-01-13-seatunnel-metadata-cache.md
@@ -1,18 +1,16 @@
---
slug: seatunnel-metadata-cache
title: "深度拆解 Apache SeaTunnel 元数据缓存:支撑数万同步任务并行运行"
-tags: [Zeta, SeaTunnel Engine, Metadata]
---
# 深度拆解 Apache SeaTunnel 元数据缓存:支撑数万同步任务并行运行
-
在大规模数据集成场景中,吞吐瓶颈往往不在数据通道本身,而在“元数据路径”上:启动时的 Connector/Jar
加载、运行中的状态管理与恢复、以及初始化阶段对外部系统(如数据库、Hive Metastore)的
Schema/分区查询。任务量一旦上到千级、万级,这些“看似轻量”的动作会被放大成集群级别的压力。
Apache SeaTunnel
Engine(Zeta)把一部分高频、可复用且昂贵的元数据下沉到引擎侧进行缓存,并配合分布式存储与自动清理策略,让海量同步任务可以更稳定地并行运行。
-
+
## 为什么“元数据”会成为瓶颈
@@ -99,4 +97,4 @@ Flink 的设计重心是长生命周期的流作业与复杂算子状态;Spark
- **关注“元数据指标”**:除了 JVM 指标,建议关注 Checkpoint 延迟/失败率、Hazelcast 内存使用、IMap
大小与增长速率、历史作业累积速度等。
- **配置过期策略**:根据排障与审计需求设置 `history-job-expire-minutes`,避免“为了可观测性而撑爆内存”。
-
+
diff --git a/static/image/20260113/seatunnel-metadata-cache/dashboard.jpg
b/static/image/20260113/seatunnel-metadata-cache/dashboard.jpg
new file mode 100644
index 000000000000..2dffba076eba
Binary files /dev/null and
b/static/image/20260113/seatunnel-metadata-cache/dashboard.jpg differ
diff --git a/static/image/20260113/seatunnel-metadata-cache/metadata-flow.jpg
b/static/image/20260113/seatunnel-metadata-cache/metadata-flow.jpg
new file mode 100644
index 000000000000..c3575105384f
Binary files /dev/null and
b/static/image/20260113/seatunnel-metadata-cache/metadata-flow.jpg differ
{kind=link}
{kind=link}
{kind=link}