Repository: spark Updated Branches: refs/heads/master 86664338f -> b09ec92a6
[SPARK-21502][MESOS] fix --supervise for mesos in cluster mode ## What changes were proposed in this pull request? With supervise enabled for a driver, re-launching it was failing because the driver had the same framework Id. This patch creates a new driver framework id every time we re-launch a driver, but we keep the driver submission id the same since that is the same with the task id the driver was launched with on mesos and retry state and other info within Dispatcher's data structures uses that as a key. We append a "-retry-%4d" string as a suffix to the framework id passed by the dispatcher to the driver and the same value to the app_id created by each driver, except the first time where we dont need the retry suffix. The previous format for the frameworkId was 'DispactherFId-DriverSubmissionId'. We also detect the case where we have multiple spark contexts started from within the same driver and we do set proper names to their corresponding app-ids. The old practice was to unset the framework id passed from the dispatcher after the driver framework was started for the first time and let mesos decide the framework ID for subsequent spark contexts. The decided fId was passed as an appID. This patch affects heavily the history server. Btw we dont have the issues of the standalone case where driver id must be different since the dispatcher will re-launch a driver(mesos task) only if it gets an update that it is dead and this is verified by mesos implicitly. We also dont fix the fine grained mode which is deprecated and of no use. ## How was this patch tested? This task was manually tested on dc/os. Launched a driver, stoped its container and verified the expected behavior. Initial retry of the driver, driver in pending state:  Driver re-launched: 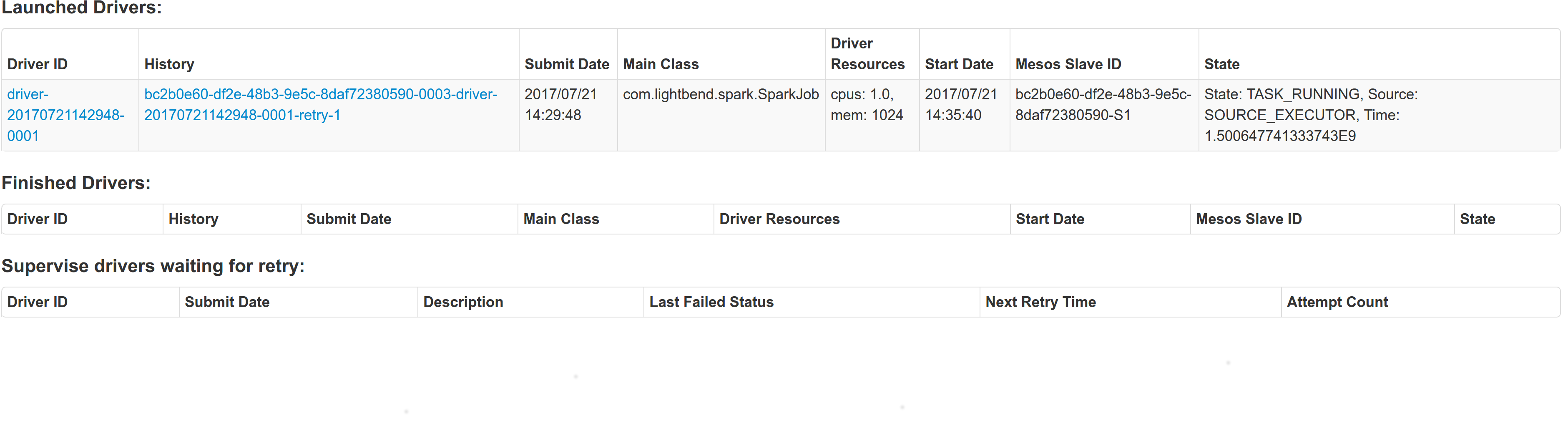 Another re-try:  The resulted entries in history server at the bottom: 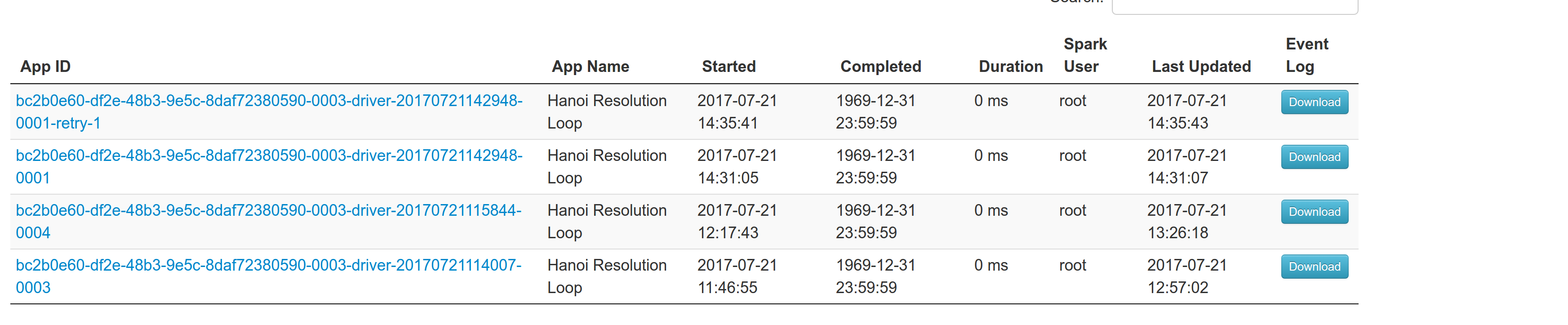 Regarding multiple spark contexts here is the end result regarding the spark history server, for the second spark context we add an increasing number as a suffix:  Author: Stavros Kontopoulos <[email protected]> Closes #18705 from skonto/fix_supervise_flag. Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/b09ec92a Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/b09ec92a Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/b09ec92a Branch: refs/heads/master Commit: b09ec92a6b57be1f16e6f9a60469b54819632ffe Parents: 8666433 Author: Stavros Kontopoulos <[email protected]> Authored: Mon Jul 24 11:11:34 2017 -0700 Committer: Marcelo Vanzin <[email protected]> Committed: Mon Jul 24 11:11:34 2017 -0700 ---------------------------------------------------------------------- .../cluster/mesos/MesosClusterScheduler.scala | 3 ++- .../MesosCoarseGrainedSchedulerBackend.scala | 20 ++++++++++++++++++-- 2 files changed, 20 insertions(+), 3 deletions(-) ---------------------------------------------------------------------- http://git-wip-us.apache.org/repos/asf/spark/blob/b09ec92a/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosClusterScheduler.scala ---------------------------------------------------------------------- diff --git a/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosClusterScheduler.scala b/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosClusterScheduler.scala index 577f9a8..28780d3 100644 --- a/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosClusterScheduler.scala +++ b/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosClusterScheduler.scala @@ -369,7 +369,8 @@ private[spark] class MesosClusterScheduler( } private def getDriverFrameworkID(desc: MesosDriverDescription): String = { - s"${frameworkId}-${desc.submissionId}" + val retries = desc.retryState.map { d => s"-retry-${d.retries.toString}" }.getOrElse("") + s"${frameworkId}-${desc.submissionId}${retries}" } private def adjust[A, B](m: collection.Map[A, B], k: A, default: B)(f: B => B) = { http://git-wip-us.apache.org/repos/asf/spark/blob/b09ec92a/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosCoarseGrainedSchedulerBackend.scala ---------------------------------------------------------------------- diff --git a/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosCoarseGrainedSchedulerBackend.scala b/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosCoarseGrainedSchedulerBackend.scala index 6e7f41d..e6b0957 100644 --- a/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosCoarseGrainedSchedulerBackend.scala +++ b/resource-managers/mesos/src/main/scala/org/apache/spark/scheduler/cluster/mesos/MesosCoarseGrainedSchedulerBackend.scala @@ -19,6 +19,7 @@ package org.apache.spark.scheduler.cluster.mesos import java.io.File import java.util.{Collections, List => JList} +import java.util.concurrent.atomic.{AtomicBoolean, AtomicLong} import java.util.concurrent.locks.ReentrantLock import scala.collection.JavaConverters._ @@ -170,6 +171,15 @@ private[spark] class MesosCoarseGrainedSchedulerBackend( override def start() { super.start() + + val startedBefore = IdHelper.startedBefore.getAndSet(true) + + val suffix = if (startedBefore) { + f"-${IdHelper.nextSCNumber.incrementAndGet()}%04d" + } else { + "" + } + val driver = createSchedulerDriver( master, MesosCoarseGrainedSchedulerBackend.this, @@ -179,10 +189,9 @@ private[spark] class MesosCoarseGrainedSchedulerBackend( sc.conf.getOption("spark.mesos.driver.webui.url").orElse(sc.ui.map(_.webUrl)), None, Some(sc.conf.get(DRIVER_FAILOVER_TIMEOUT)), - sc.conf.getOption("spark.mesos.driver.frameworkId") + sc.conf.getOption("spark.mesos.driver.frameworkId").map(_ + suffix) ) - unsetFrameworkID(sc) startScheduler(driver) } @@ -271,6 +280,7 @@ private[spark] class MesosCoarseGrainedSchedulerBackend( driver: org.apache.mesos.SchedulerDriver, frameworkId: FrameworkID, masterInfo: MasterInfo) { + this.appId = frameworkId.getValue this.mesosExternalShuffleClient.foreach(_.init(appId)) this.schedulerDriver = driver @@ -672,3 +682,9 @@ private class Slave(val hostname: String) { var taskFailures = 0 var shuffleRegistered = false } + +object IdHelper { + // Use atomic values since Spark contexts can be initialized in parallel + private[mesos] val nextSCNumber = new AtomicLong(0) + private[mesos] val startedBefore = new AtomicBoolean(false) +} --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}