Repository: spark Updated Branches: refs/heads/master 290c30a53 -> 59c3c233f
[SPARK-23254][ML] Add user guide entry and example for DataFrame multivariate summary ## What changes were proposed in this pull request? Add user guide and scala/java/python examples for `ml.stat.Summarizer` ## How was this patch tested? Doc generated snapshot:  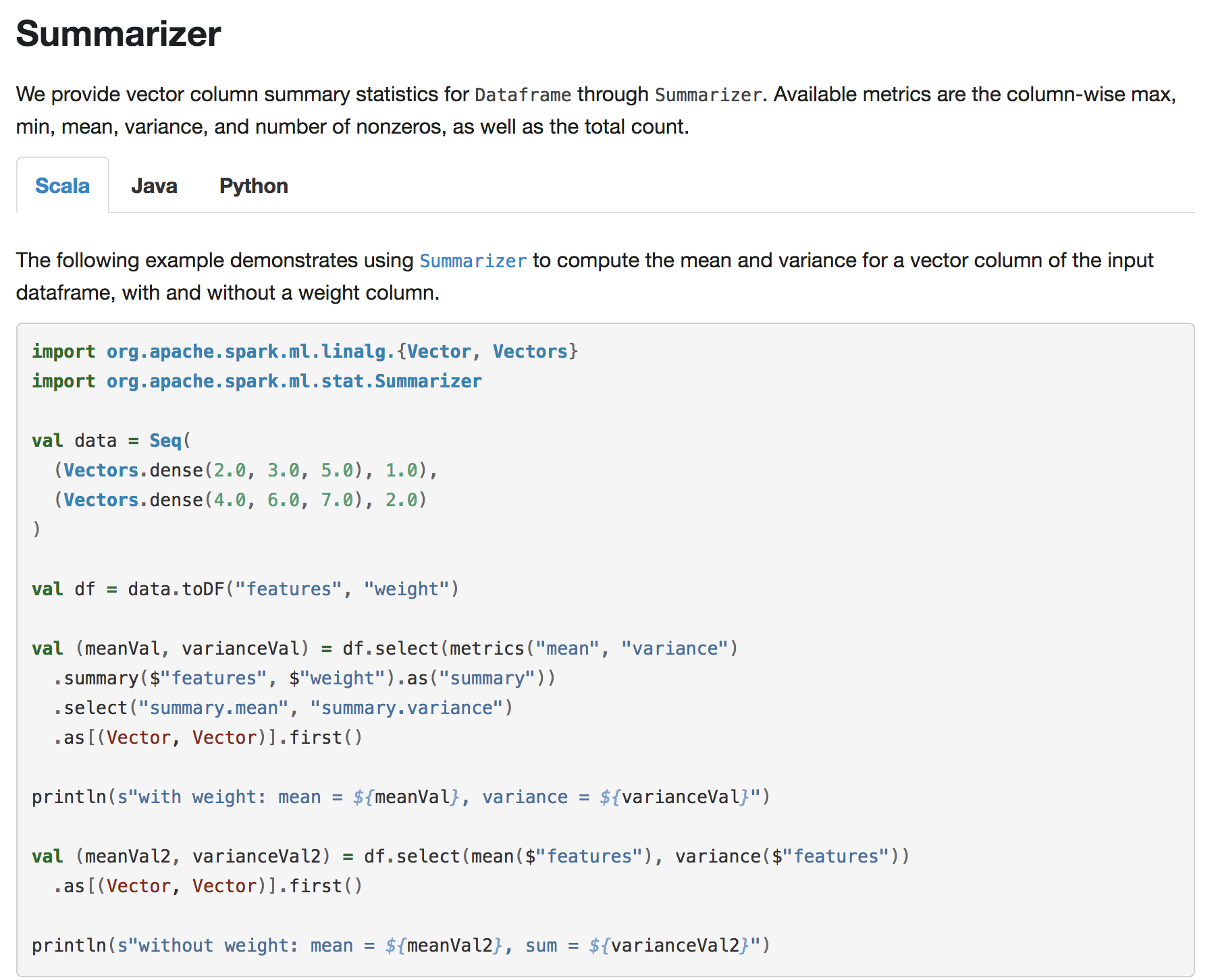   Author: WeichenXu <[email protected]> Closes #20446 from WeichenXu123/summ_guide. Project: http://git-wip-us.apache.org/repos/asf/spark/repo Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/59c3c233 Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/59c3c233 Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/59c3c233 Branch: refs/heads/master Commit: 59c3c233f4366809b6b4db39b3d32c194c98d5ab Parents: 290c30a Author: WeichenXu <[email protected]> Authored: Wed Jul 11 13:56:09 2018 -0500 Committer: Sean Owen <[email protected]> Committed: Wed Jul 11 13:56:09 2018 -0500 ---------------------------------------------------------------------- docs/ml-statistics.md | 28 ++++++++ .../examples/ml/JavaSummarizerExample.java | 71 ++++++++++++++++++++ .../src/main/python/ml/summarizer_example.py | 59 ++++++++++++++++ .../spark/examples/ml/SummarizerExample.scala | 61 +++++++++++++++++ 4 files changed, 219 insertions(+) ---------------------------------------------------------------------- http://git-wip-us.apache.org/repos/asf/spark/blob/59c3c233/docs/ml-statistics.md ---------------------------------------------------------------------- diff --git a/docs/ml-statistics.md b/docs/ml-statistics.md index abfb3ca..6c82b3b 100644 --- a/docs/ml-statistics.md +++ b/docs/ml-statistics.md @@ -89,4 +89,32 @@ Refer to the [`ChiSquareTest` Python docs](api/python/index.html#pyspark.ml.stat {% include_example python/ml/chi_square_test_example.py %} </div> +</div> + +## Summarizer + +We provide vector column summary statistics for `Dataframe` through `Summarizer`. +Available metrics are the column-wise max, min, mean, variance, and number of nonzeros, as well as the total count. + +<div class="codetabs"> +<div data-lang="scala" markdown="1"> +The following example demonstrates using [`Summarizer`](api/scala/index.html#org.apache.spark.ml.stat.Summarizer$) +to compute the mean and variance for a vector column of the input dataframe, with and without a weight column. + +{% include_example scala/org/apache/spark/examples/ml/SummarizerExample.scala %} +</div> + +<div data-lang="java" markdown="1"> +The following example demonstrates using [`Summarizer`](api/java/org/apache/spark/ml/stat/Summarizer.html) +to compute the mean and variance for a vector column of the input dataframe, with and without a weight column. + +{% include_example java/org/apache/spark/examples/ml/JavaSummarizerExample.java %} +</div> + +<div data-lang="python" markdown="1"> +Refer to the [`Summarizer` Python docs](api/python/index.html#pyspark.ml.stat.Summarizer$) for details on the API. + +{% include_example python/ml/summarizer_example.py %} +</div> + </div> \ No newline at end of file http://git-wip-us.apache.org/repos/asf/spark/blob/59c3c233/examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java ---------------------------------------------------------------------- diff --git a/examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java b/examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java new file mode 100644 index 0000000..e9b8436 --- /dev/null +++ b/examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java @@ -0,0 +1,71 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.examples.ml; + +import org.apache.spark.sql.*; + +// $example on$ +import java.util.Arrays; +import java.util.List; + +import org.apache.spark.ml.linalg.Vector; +import org.apache.spark.ml.linalg.Vectors; +import org.apache.spark.ml.linalg.VectorUDT; +import org.apache.spark.ml.stat.Summarizer; +import org.apache.spark.sql.types.DataTypes; +import org.apache.spark.sql.types.Metadata; +import org.apache.spark.sql.types.StructField; +import org.apache.spark.sql.types.StructType; +// $example off$ + +public class JavaSummarizerExample { + public static void main(String[] args) { + SparkSession spark = SparkSession + .builder() + .appName("JavaSummarizerExample") + .getOrCreate(); + + // $example on$ + List<Row> data = Arrays.asList( + RowFactory.create(Vectors.dense(2.0, 3.0, 5.0), 1.0), + RowFactory.create(Vectors.dense(4.0, 6.0, 7.0), 2.0) + ); + + StructType schema = new StructType(new StructField[]{ + new StructField("features", new VectorUDT(), false, Metadata.empty()), + new StructField("weight", DataTypes.DoubleType, false, Metadata.empty()) + }); + + Dataset<Row> df = spark.createDataFrame(data, schema); + + Row result1 = df.select(Summarizer.metrics("mean", "variance") + .summary(new Column("features"), new Column("weight")).as("summary")) + .select("summary.mean", "summary.variance").first(); + System.out.println("with weight: mean = " + result1.<Vector>getAs(0).toString() + + ", variance = " + result1.<Vector>getAs(1).toString()); + + Row result2 = df.select( + Summarizer.mean(new Column("features")), + Summarizer.variance(new Column("features")) + ).first(); + System.out.println("without weight: mean = " + result2.<Vector>getAs(0).toString() + + ", variance = " + result2.<Vector>getAs(1).toString()); + // $example off$ + spark.stop(); + } +} http://git-wip-us.apache.org/repos/asf/spark/blob/59c3c233/examples/src/main/python/ml/summarizer_example.py ---------------------------------------------------------------------- diff --git a/examples/src/main/python/ml/summarizer_example.py b/examples/src/main/python/ml/summarizer_example.py new file mode 100644 index 0000000..8835f18 --- /dev/null +++ b/examples/src/main/python/ml/summarizer_example.py @@ -0,0 +1,59 @@ +# +# Licensed to the Apache Software Foundation (ASF) under one or more +# contributor license agreements. See the NOTICE file distributed with +# this work for additional information regarding copyright ownership. +# The ASF licenses this file to You under the Apache License, Version 2.0 +# (the "License"); you may not use this file except in compliance with +# the License. You may obtain a copy of the License at +# +# http://www.apache.org/licenses/LICENSE-2.0 +# +# Unless required by applicable law or agreed to in writing, software +# distributed under the License is distributed on an "AS IS" BASIS, +# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. +# See the License for the specific language governing permissions and +# limitations under the License. +# + +""" +An example for summarizer. +Run with: + bin/spark-submit examples/src/main/python/ml/summarizer_example.py +""" +from __future__ import print_function + +from pyspark.sql import SparkSession +# $example on$ +from pyspark.ml.stat import Summarizer +from pyspark.sql import Row +from pyspark.ml.linalg import Vectors +# $example off$ + +if __name__ == "__main__": + spark = SparkSession \ + .builder \ + .appName("SummarizerExample") \ + .getOrCreate() + sc = spark.sparkContext + + # $example on$ + df = sc.parallelize([Row(weight=1.0, features=Vectors.dense(1.0, 1.0, 1.0)), + Row(weight=0.0, features=Vectors.dense(1.0, 2.0, 3.0))]).toDF() + + # create summarizer for multiple metrics "mean" and "count" + summarizer = Summarizer.metrics("mean", "count") + + # compute statistics for multiple metrics with weight + df.select(summarizer.summary(df.features, df.weight)).show(truncate=False) + + # compute statistics for multiple metrics without weight + df.select(summarizer.summary(df.features)).show(truncate=False) + + # compute statistics for single metric "mean" with weight + df.select(Summarizer.mean(df.features, df.weight)).show(truncate=False) + + # compute statistics for single metric "mean" without weight + df.select(Summarizer.mean(df.features)).show(truncate=False) + # $example off$ + + spark.stop() http://git-wip-us.apache.org/repos/asf/spark/blob/59c3c233/examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala ---------------------------------------------------------------------- diff --git a/examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala b/examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala new file mode 100644 index 0000000..2f54d1d --- /dev/null +++ b/examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala @@ -0,0 +1,61 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +// scalastyle:off println +package org.apache.spark.examples.ml + +// $example on$ +import org.apache.spark.ml.linalg.{Vector, Vectors} +import org.apache.spark.ml.stat.Summarizer +// $example off$ +import org.apache.spark.sql.SparkSession + +object SummarizerExample { + def main(args: Array[String]): Unit = { + val spark = SparkSession + .builder + .appName("SummarizerExample") + .getOrCreate() + + import spark.implicits._ + import Summarizer._ + + // $example on$ + val data = Seq( + (Vectors.dense(2.0, 3.0, 5.0), 1.0), + (Vectors.dense(4.0, 6.0, 7.0), 2.0) + ) + + val df = data.toDF("features", "weight") + + val (meanVal, varianceVal) = df.select(metrics("mean", "variance") + .summary($"features", $"weight").as("summary")) + .select("summary.mean", "summary.variance") + .as[(Vector, Vector)].first() + + println(s"with weight: mean = ${meanVal}, variance = ${varianceVal}") + + val (meanVal2, varianceVal2) = df.select(mean($"features"), variance($"features")) + .as[(Vector, Vector)].first() + + println(s"without weight: mean = ${meanVal2}, sum = ${varianceVal2}") + // $example off$ + + spark.stop() + } +} +// scalastyle:on println --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}