This is an automated email from the ASF dual-hosted git repository.
gurwls223 pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new 36be232 [SPARK-36541][DOCS][PYTHON] Replace the word Koalas to
pandas-on-Spark
36be232 is described below
commit 36be232eeaa5a07daaa4a40b0f4490d3d96726ab
Author: Leona Yoda <[email protected]>
AuthorDate: Thu Aug 26 19:03:02 2021 +0900
[SPARK-36541][DOCS][PYTHON] Replace the word Koalas to pandas-on-Spark
### What changes were proposed in this pull request?
Replace images in pyspark on pandas document because those images uses the
word Koalas
### Why are the changes needed?
Images in Transform and apply a function documentation still uses the word
Koalas, althogh the word was replaced to panas-on-Spark by this PR .
https://github.com/apache/spark/pull/32835
I think we have to match the word on that images
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
`make html`
Screen shots




Environment
- Windows 10
- Google Chrome 92.0.4515.159
[images.pptx](https://github.com/apache/spark/files/7029087/images.pptx)
Closes #33786 from yoda-mon/replace-pyspark-doc-images.
Authored-by: Leona Yoda <[email protected]>
Signed-off-by: Hyukjin Kwon <[email protected]>
(cherry picked from commit aeb3da2798c283cb8efd09ed673695f4ecc63aab)
Signed-off-by: Hyukjin Kwon <[email protected]>
---
docs/img/pyspark-pandas_on_spark-transform_apply.pptx | Bin 0 -> 139692 bytes
docs/img/pyspark-pandas_on_spark-transform_apply1.png | Bin 0 -> 190159 bytes
docs/img/pyspark-pandas_on_spark-transform_apply2.png | Bin 0 -> 182356 bytes
docs/img/pyspark-pandas_on_spark-transform_apply3.png | Bin 0 -> 166645 bytes
docs/img/pyspark-pandas_on_spark-transform_apply4.png | Bin 0 -> 64346 bytes
.../user_guide/pandas_on_spark/transform_apply.rst | 8 ++++----
6 files changed, 4 insertions(+), 4 deletions(-)
diff --git a/docs/img/pyspark-pandas_on_spark-transform_apply.pptx
b/docs/img/pyspark-pandas_on_spark-transform_apply.pptx
new file mode 100644
index 0000000..64cc050
Binary files /dev/null and
b/docs/img/pyspark-pandas_on_spark-transform_apply.pptx differ
diff --git a/docs/img/pyspark-pandas_on_spark-transform_apply1.png
b/docs/img/pyspark-pandas_on_spark-transform_apply1.png
new file mode 100644
index 0000000..f5df0b1
Binary files /dev/null and
b/docs/img/pyspark-pandas_on_spark-transform_apply1.png differ
diff --git a/docs/img/pyspark-pandas_on_spark-transform_apply2.png
b/docs/img/pyspark-pandas_on_spark-transform_apply2.png
new file mode 100644
index 0000000..1f662b3e
Binary files /dev/null and
b/docs/img/pyspark-pandas_on_spark-transform_apply2.png differ
diff --git a/docs/img/pyspark-pandas_on_spark-transform_apply3.png
b/docs/img/pyspark-pandas_on_spark-transform_apply3.png
new file mode 100644
index 0000000..674067d
Binary files /dev/null and
b/docs/img/pyspark-pandas_on_spark-transform_apply3.png differ
diff --git a/docs/img/pyspark-pandas_on_spark-transform_apply4.png
b/docs/img/pyspark-pandas_on_spark-transform_apply4.png
new file mode 100644
index 0000000..b123185
Binary files /dev/null and
b/docs/img/pyspark-pandas_on_spark-transform_apply4.png differ
diff --git a/python/docs/source/user_guide/pandas_on_spark/transform_apply.rst
b/python/docs/source/user_guide/pandas_on_spark/transform_apply.rst
index 6e44156..83c8818 100644
--- a/python/docs/source/user_guide/pandas_on_spark/transform_apply.rst
+++ b/python/docs/source/user_guide/pandas_on_spark/transform_apply.rst
@@ -36,7 +36,7 @@ to return the same length of the input and the latter does
not require this. See
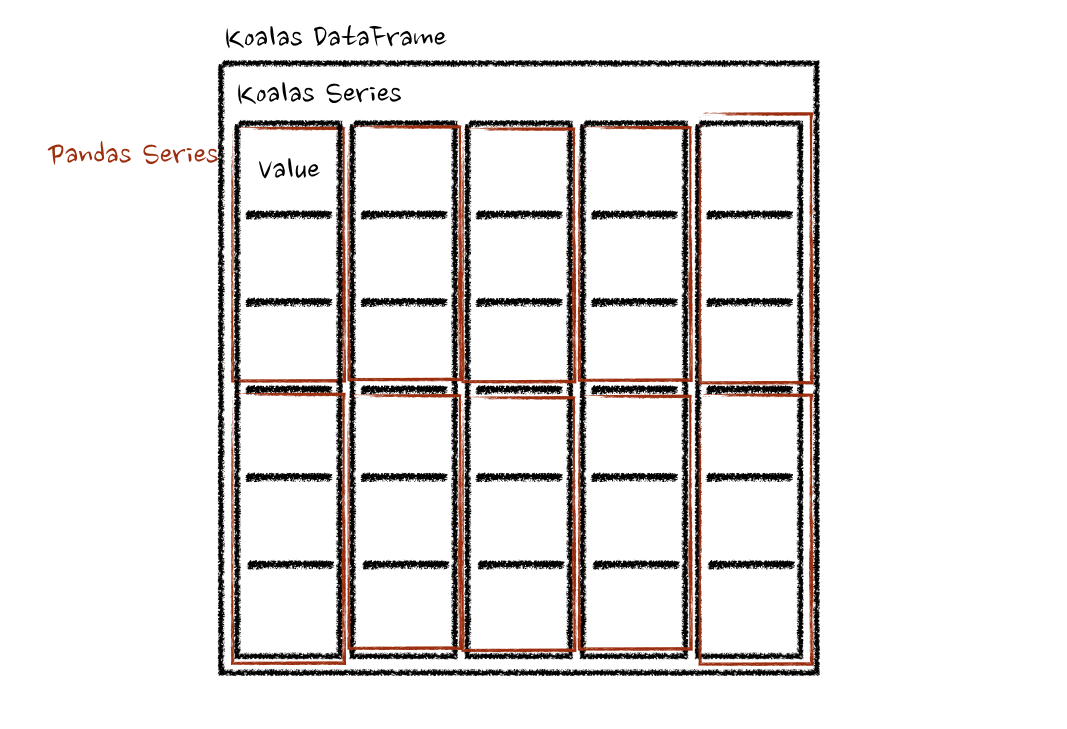
In this case, each function takes a pandas Series, and pandas API on Spark
computes the functions in a distributed manner as below.
-.. image::
https://user-images.githubusercontent.com/6477701/80076790-a1cf0680-8587-11ea-8b08-8dc694071ba0.png
+.. image:: ../../../../../docs/img/pyspark-pandas_on_spark-transform_apply1.png
:alt: transform and apply
:align: center
:width: 550
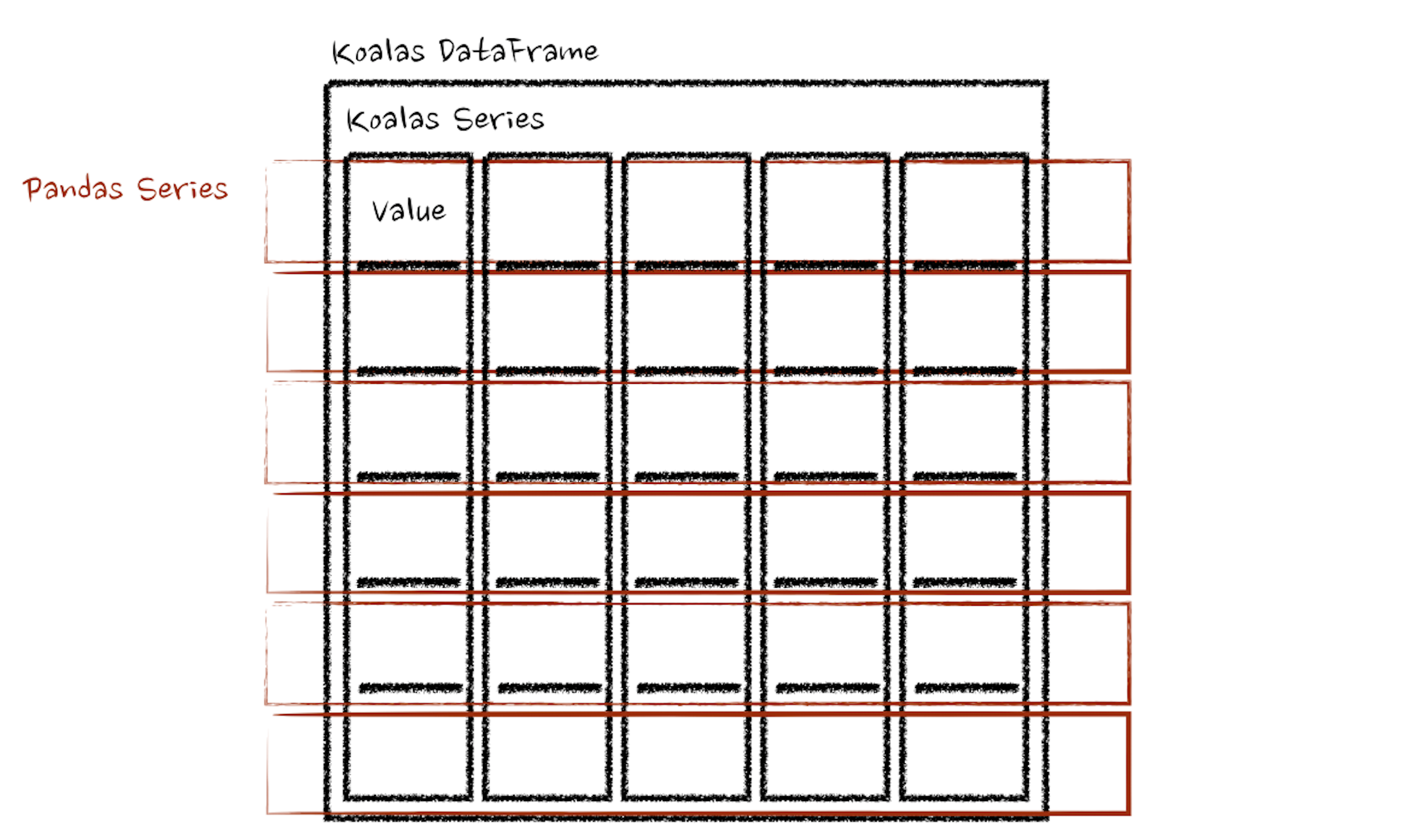
@@ -53,7 +53,7 @@ In case of 'column' axis, the function takes each row as a
pandas Series.
The example above calculates the summation of each row as a pandas Series. See
below:
-.. image::
https://user-images.githubusercontent.com/6477701/80076898-c2975c00-8587-11ea-9b2c-69c9729e9294.png
+.. image:: ../../../../../docs/img/pyspark-pandas_on_spark-transform_apply2.png
:alt: apply axis
:align: center
:width: 600
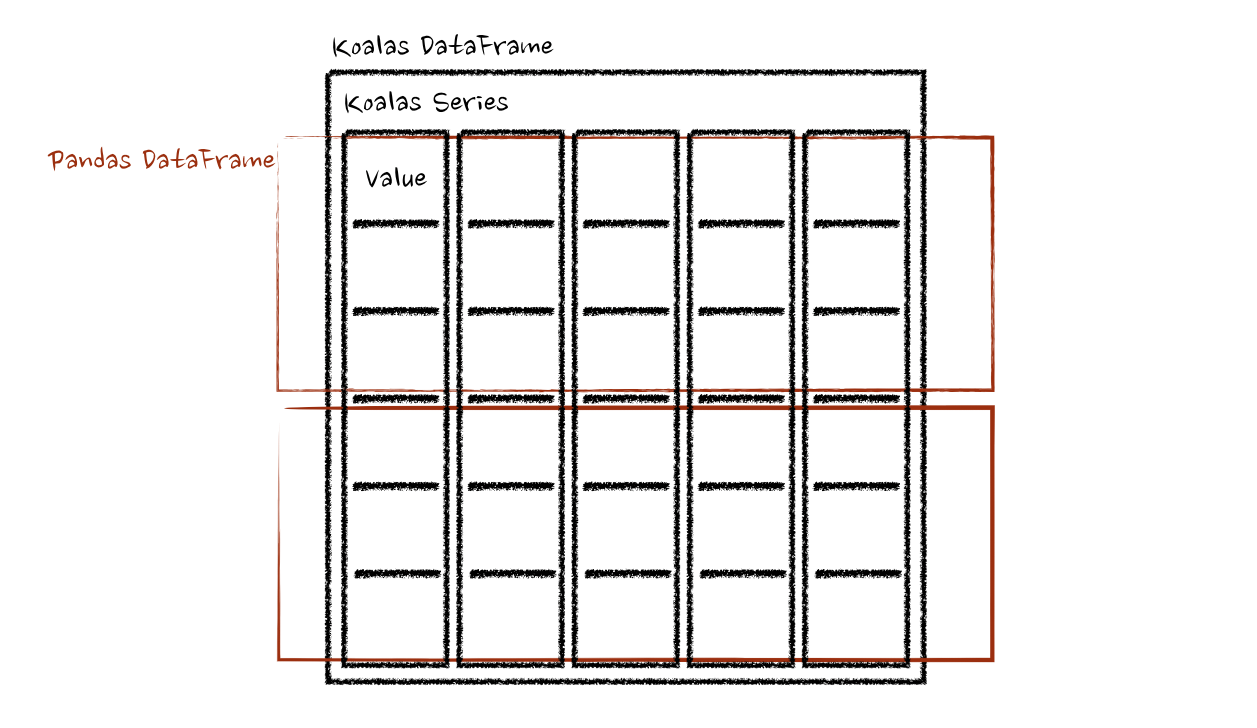
@@ -95,7 +95,7 @@ you can avoid a shuffle by the operations between different
DataFrames. In case
treated that it belongs to a new different DataFrame. See also
`Operations on different DataFrames
<options.rst#operations-on-different-dataframes>`_ for more details.
-.. image::
https://user-images.githubusercontent.com/6477701/80076779-9f6cac80-8587-11ea-8c92-07d7b992733b.png
+.. image:: ../../../../../docs/img/pyspark-pandas_on_spark-transform_apply3.png
:alt: pandas_on_spark.transform_batch and pandas_on_spark.apply_batch in
Frame
:align: center
:width: 650
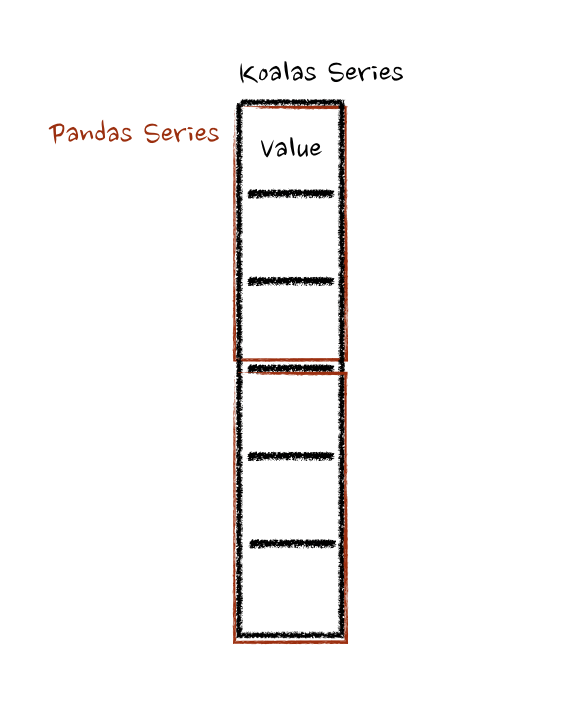
@@ -113,7 +113,7 @@ a pandas Series as a chunk of pandas-on-Spark Series.
Under the hood, each batch of pandas-on-Spark Series is split to multiple
pandas Series, and each function computes on that as below:
-.. image::
https://user-images.githubusercontent.com/6477701/80076795-a3003380-8587-11ea-8b73-186e4047f8c0.png
+.. image:: ../../../../../docs/img/pyspark-pandas_on_spark-transform_apply4.png
:alt: pandas_on_spark.transform_batch in Series
:width: 350
:align: center
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}