This is an automated email from the ASF dual-hosted git repository.
wuyi pushed a commit to branch branch-3.2
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.2 by this push:
new f20c408 [SPARK-37481][CORE][WEBUI] Fix disappearance of skipped
stages after they retry
f20c408 is described below
commit f20c408be0cd2f53815b4b26a88aa8c2e3545a5c
Author: Kent Yao <[email protected]>
AuthorDate: Mon Dec 13 10:40:42 2021 +0800
[SPARK-37481][CORE][WEBUI] Fix disappearance of skipped stages after they
retry
### What changes were proposed in this pull request?
When skipped stages retry, their skipped info will be lost on the UI, and
then we may see a stage with 200 tasks indeed, shows that it only has 3 tasks
but its `retry 1` has 15 tasks and completely different inputs/outputs.
A simple way to reproduce,
```
bin/spark-sql --packages com.github.yaooqinn:itachi_2.12:0.3.0
```
and run
```
select * from (select v from (values (1), (2), (3) t(v))) t1 join (select
stage_id_with_retry(3) from (select v from values (1), (2), (3) t(v) group by
v)) t2;
```
Also, Detailed in the Gist here -
https://gist.github.com/yaooqinn/6acb7b74b343a6a6dffe8401f6b7b45c
In this PR, we increase the nextAttempIds of these skipped stages once they
get visited.
### Why are the changes needed?
fix problems when we have skipped stage retries.
### Does this PR introduce _any_ user-facing change?
Yes, the UI will keep the skipped stages info
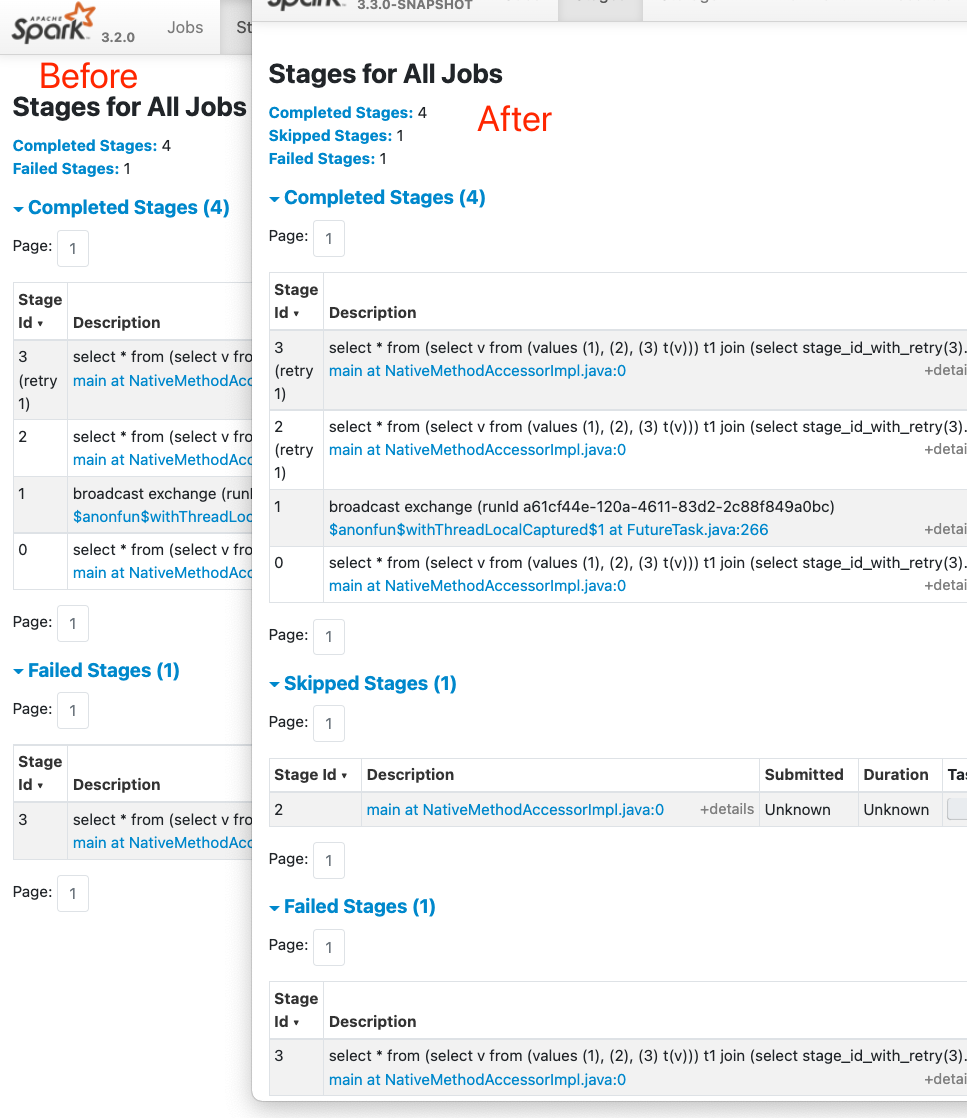
### How was this patch tested?
manually as recorded in
https://gist.github.com/yaooqinn/6acb7b74b343a6a6dffe8401f6b7b45c
existing tests
Closes #34735 from yaooqinn/SPARK-37481.
Authored-by: Kent Yao <[email protected]>
Signed-off-by: yi.wu <[email protected]>
(cherry picked from commit 5880df41f50210f2df44f25640437d99b8979d70)
Signed-off-by: yi.wu <[email protected]>
---
core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala | 6 ++++++
core/src/main/scala/org/apache/spark/scheduler/Stage.scala | 7 +++++++
.../test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala | 6 +++---
3 files changed, 16 insertions(+), 3 deletions(-)
diff --git a/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
b/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
index bb77a58d..9a27d9c 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
@@ -716,6 +716,12 @@ private[spark] class DAGScheduler(
// read from merged output as the MergeStatuses are not
available.
if (!mapStage.isAvailable ||
!mapStage.shuffleDep.shuffleMergeFinalized) {
missing += mapStage
+ } else {
+ // Forward the nextAttemptId if skipped and get visited for
the first time.
+ // Otherwise, once it gets retried,
+ // 1) the stuffs in stage info become distorting, e.g. task
num, input byte, e.t.c
+ // 2) the first attempt starts from 0-idx, it will not be
marked as a retry
+ mapStage.increaseAttemptIdOnFirstSkip()
}
case narrowDep: NarrowDependency[_] =>
waitingForVisit.prepend(narrowDep.rdd)
diff --git a/core/src/main/scala/org/apache/spark/scheduler/Stage.scala
b/core/src/main/scala/org/apache/spark/scheduler/Stage.scala
index ae7924d..9707211 100644
--- a/core/src/main/scala/org/apache/spark/scheduler/Stage.scala
+++ b/core/src/main/scala/org/apache/spark/scheduler/Stage.scala
@@ -107,6 +107,13 @@ private[scheduler] abstract class Stage(
nextAttemptId += 1
}
+ /** Forward the nextAttemptId if skipped and get visited for the first time.
*/
+ def increaseAttemptIdOnFirstSkip(): Unit = {
+ if (nextAttemptId == 0) {
+ nextAttemptId = 1
+ }
+ }
+
/** Returns the StageInfo for the most recent attempt for this stage. */
def latestInfo: StageInfo = _latestInfo
diff --git
a/core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala
b/core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala
index 4cb64ed..afea912 100644
--- a/core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala
+++ b/core/src/test/scala/org/apache/spark/scheduler/DAGSchedulerSuite.scala
@@ -1622,7 +1622,7 @@ class DAGSchedulerSuite extends SparkFunSuite with
TempLocalSparkContext with Ti
// the shuffle map output is still available from stage 0); make sure
we've still got internal
// accumulators setup
assert(scheduler.stageIdToStage(2).latestInfo.taskMetrics != null)
- completeShuffleMapStageSuccessfully(2, 0, 2)
+ completeShuffleMapStageSuccessfully(2, 1, 2)
completeNextResultStageWithSuccess(3, 1, idx => idx + 1234)
assert(results === Map(0 -> 1234, 1 -> 1235))
@@ -3514,7 +3514,7 @@ class DAGSchedulerSuite extends SparkFunSuite with
TempLocalSparkContext with Ti
// Check if same merger locs is reused for the new stage with shared
shuffle dependency
assert(mergerLocs.zip(newMergerLocs).forall(x => x._1.host == x._2.host))
- completeShuffleMapStageSuccessfully(2, 0, 2)
+ completeShuffleMapStageSuccessfully(2, 1, 2)
completeNextResultStageWithSuccess(3, 1, idx => idx + 1234)
assert(results === Map(0 -> 1234, 1 -> 1235))
@@ -3650,7 +3650,7 @@ class DAGSchedulerSuite extends SparkFunSuite with
TempLocalSparkContext with Ti
// the scheduler now creates a new task set to regenerate the missing map
output, but this time
// using a different stage, the "skipped" one
assert(scheduler.stageIdToStage(2).latestInfo.taskMetrics != null)
- completeShuffleMapStageSuccessfully(2, 0, 2)
+ completeShuffleMapStageSuccessfully(2, 1, 2)
completeNextResultStageWithSuccess(3, 1, idx => idx + 1234)
val expected = (0 until parts).map(idx => (idx, idx + 1234))
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}