This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new 727f044 [SPARK-38189][K8S][DOC] Add `Priority scheduling` doc for
Spark on K8S
727f044 is described below
commit 727f044612c0a71097aa0d29cb3f24a53b93fc1f
Author: Yikun Jiang <[email protected]>
AuthorDate: Fri Mar 4 19:28:14 2022 -0800
[SPARK-38189][K8S][DOC] Add `Priority scheduling` doc for Spark on K8S
### What changes were proposed in this pull request?
Document how to set the priority class with the pod template.
### Why are the changes needed?
Currently, we didn't have a certain doc to help user enable priority
scheduling
Related: https://github.com/apache/spark/pull/35716
https://github.com/apache/spark/pull/35639#issuecomment-1055847723
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Closes #35728 from Yikun/SPARK-38189-doc.
Authored-by: Yikun Jiang <[email protected]>
Signed-off-by: Dongjoon Hyun <[email protected]>
---
docs/running-on-kubernetes.md | 24 ++++++++++++++++++++++++
1 file changed, 24 insertions(+)
diff --git a/docs/running-on-kubernetes.md b/docs/running-on-kubernetes.md
index 8553d78..971c0a6 100644
--- a/docs/running-on-kubernetes.md
+++ b/docs/running-on-kubernetes.md
@@ -1707,6 +1707,30 @@ Spark automatically handles translating the Spark
configs <code>spark.{driver/ex
Kubernetes does not tell Spark the addresses of the resources allocated to
each container. For that reason, the user must specify a discovery script that
gets run by the executor on startup to discover what resources are available to
that executor. You can find an example scripts in
`examples/src/main/scripts/getGpusResources.sh`. The script must have execute
permissions set and the user should setup permissions to not allow malicious
users to modify it. The script should write to STDOUT [...]
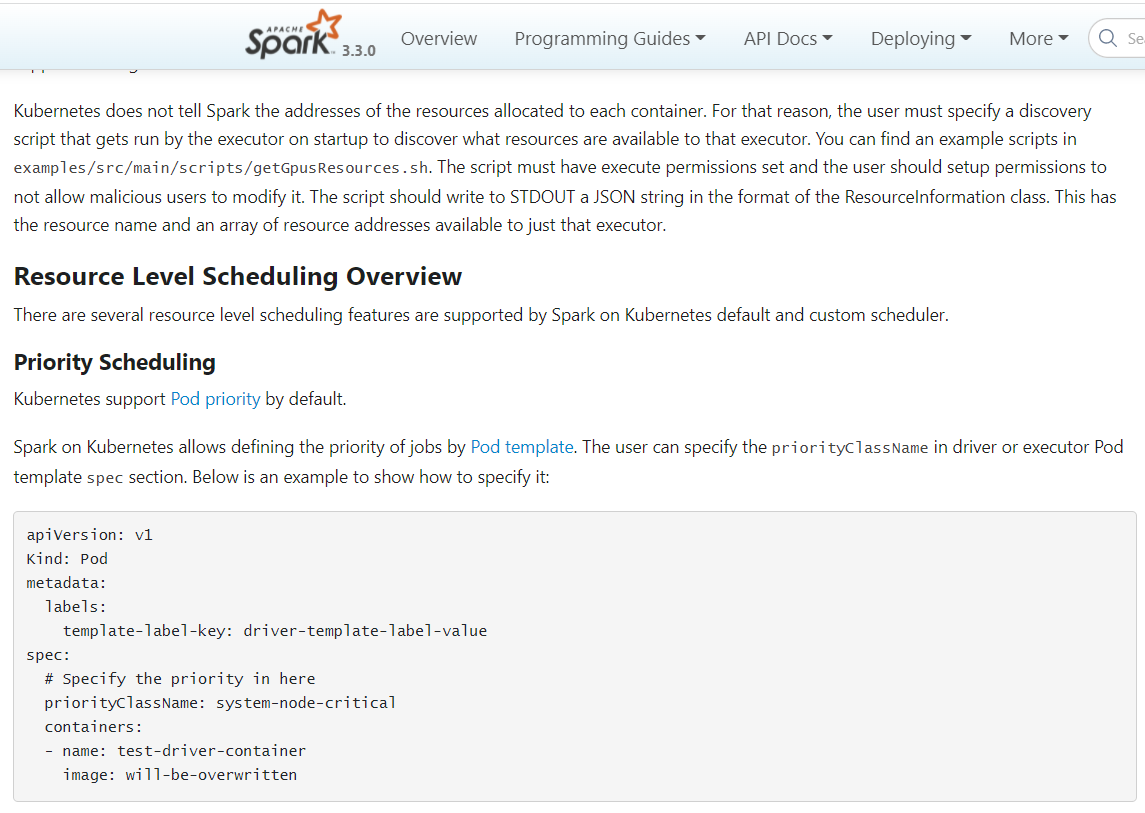
+### Resource Level Scheduling Overview
+
+There are several resource level scheduling features supported by Spark on
Kubernetes.
+
+#### Priority Scheduling
+
+Kubernetes supports [Pod
priority](https://kubernetes.io/docs/concepts/scheduling-eviction/pod-priority-preemption)
by default.
+
+Spark on Kubernetes allows defining the priority of jobs by [Pod
template](#pod-template). The user can specify the
<code>priorityClassName</code> in driver or executor Pod template
<code>spec</code> section. Below is an example to show how to specify it:
+
+```
+apiVersion: v1
+Kind: Pod
+metadata:
+ labels:
+ template-label-key: driver-template-label-value
+spec:
+ # Specify the priority in here
+ priorityClassName: system-node-critical
+ containers:
+ - name: test-driver-container
+ image: will-be-overwritten
+```
+
### Stage Level Scheduling Overview
Stage level scheduling is supported on Kubernetes when dynamic allocation is
enabled. This also requires
<code>spark.dynamicAllocation.shuffleTracking.enabled</code> to be enabled
since Kubernetes doesn't support an external shuffle service at this time. The
order in which containers for different profiles is requested from Kubernetes
is not guaranteed. Note that since dynamic allocation on Kubernetes requires
the shuffle tracking feature, this means that executors from previous stages t
[...]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}